 播面
播面 Redis主从同步时,如果网络断开了一段时间后重新连接,它是如何判断该进行增量同步还是全量同步的?
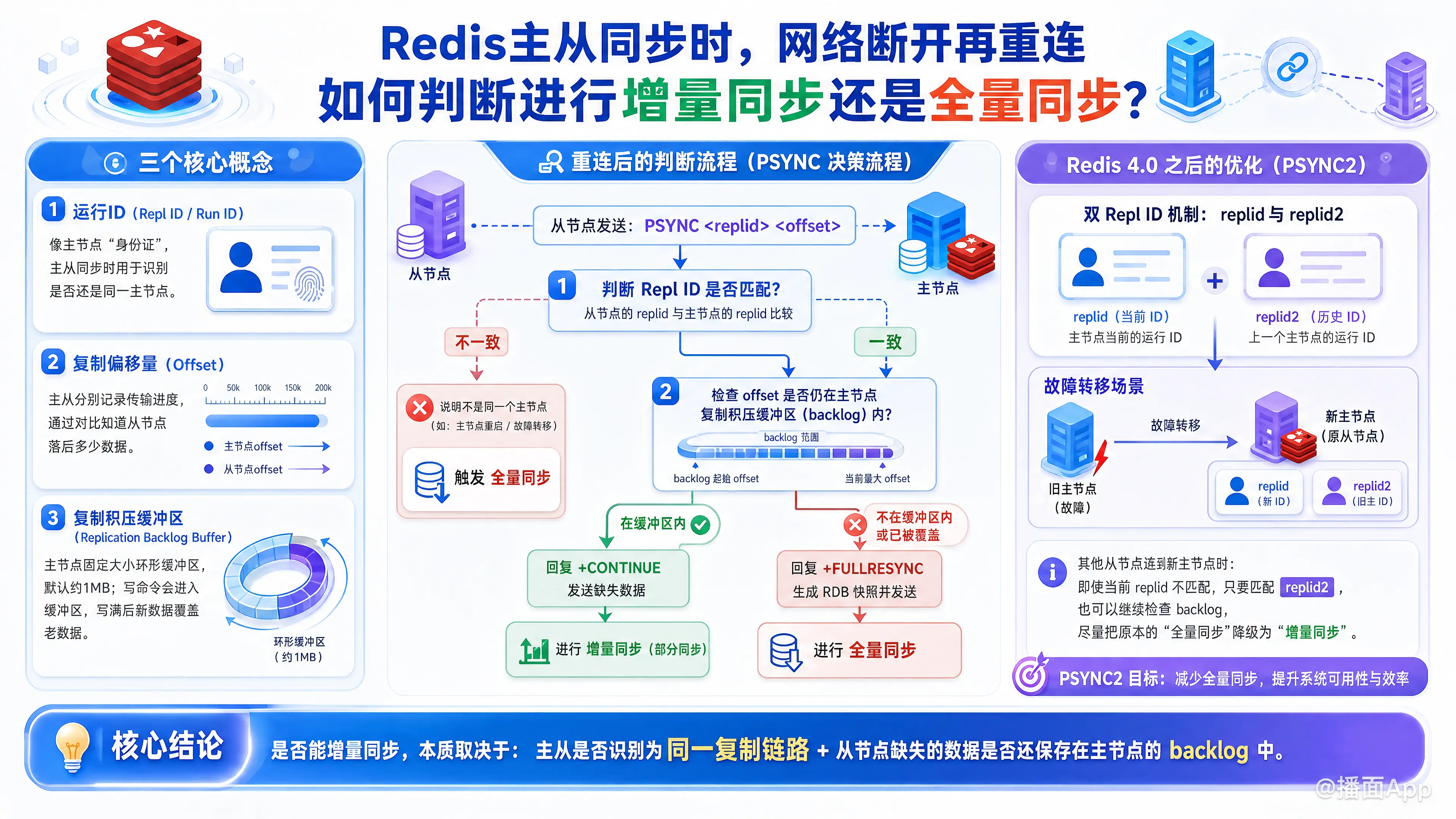
Redis 在处理主从网络断开重连时,判断进行全量同步还是增量同步(部分同步),核心是依赖 PSYNC 命令以及三个关键的内部机制:复制偏移量(Offset)、复制积压缓冲区(Replication Backlog Buffer) 和 运行ID(Repl ID / Run ID)。
下面是具体的判断逻辑和底层原理:
1. 三个核心概念
在了解判断过程前,需要先明确这三个核心概念:
- 运行 ID (Repl ID): 每个 Redis 实例启动时都会自动生成一个随机的 ID。主节点会将自己的 ID 同步给从节点。这个 ID 就像是主节点的“身份证”。
- 复制偏移量 (Offset): 主节点和从节点都会维护一个偏移量。主节点每次向从节点发送 N 个字节的数据时,自己的 offset 就会增加 N;从节点每次收到 N 个字节的数据时,自己的 offset 也会增加 N。通过对比主从的 offset,就能知道从节点落后了多少数据。
- 复制积压缓冲区 (Replication Backlog Buffer): 这是主节点上的一个固定大小的环形缓冲区(Ring Buffer),默认大小通常是 1MB。当主节点处理写命令时,不仅会发给从节点,还会写入这个缓冲区。因为它是一个环形队列,如果写满了,新数据就会覆盖最早的老数据。
2. 重连后的判断流程
当主从网络断开一段时间后重新连接,从节点会向主节点发送 PSYNC <replid> <offset> 命令(把自己的“主节点身份证”和“当前阅读进度”告诉主节点)。
主节点收到命令后,会按照以下逻辑进行判断:
第一步:判断运行 ID (Repl ID) 是否匹配
- 如果不一致: 说明从节点之前连接的主节点和当前的主节点不是同一个(比如主节点宕机重启了,或者发生了主从切换),此时主节点拒绝增量同步,强制触发全量同步。
- 如果一致: 说明是同一个主节点,进入第二步判断。
第二步:判断偏移量 (Offset) 是否还在缓冲区中
主节点会检查从节点发来的 offset 是否还存在于自己的复制积压缓冲区中。
情况 A(在缓冲区内)触发增量同步:
如果网络断开的时间比较短,或者主节点在这期间接收的写操作不多,从节点缺失的那部分数据(即主节点当前 offset-从节点提交的 offset)还在缓冲区里,没有被新数据覆盖。
处理方式: 主节点向从节点回复+CONTINUE,然后把缓冲区中缺失的那部分数据直接发送给从节点,完成增量同步。情况 B(已被覆盖出局)触发全量同步:
如果网络断开时间过长,或者主节点的写入非常频繁,导致从节点缺失的数据已经被缓冲区里的新数据覆盖掉了(即从节点的offset已经太老了,主节点找不到对应的历史记录了)。
处理方式: 主节点向从节点回复+FULLRESYNC,并生成当前数据的 RDB 快照发送给从节点,强制触发全量同步。
3. Redis 4.0 之后的优化 (PSYNC2)
在 Redis 4.0 之前,只要主节点发生了故障转移(Failover),也就是某个从节点被提升为新主节点,其他从节点连上新主节点时,因为 Repl ID 变了,必然会触发全量同步。这在大型集群中代价非常高昂。
Redis 4.0 引入了 PSYNC2 机制解决这个问题:
Redis 现在会维护两个 Repl ID(replid 和 replid2)。
当一个从节点被晋升为新主节点时,它会把旧主节点的 Repl ID 存入 replid2 中,并记住切换时的偏移量。
这样,当其他从节点连接到新主节点并发来旧的 Repl ID 时,新主节点发现虽然当前的 replid 不匹配,但它匹配历史的 replid2,于是依然可以尝试去缓冲区里找数据,从而大概率把原本的全量同步降级为增量同步。
💡 生产环境避坑建议
为了尽量避免因短暂网络抖动而引发代价高昂的全量同步,我们通常需要调整复制积压缓冲区的大小。
- 配置项:
repl-backlog-size(默认 1MB) - 计算公式:
缓冲空间大小 = 预估网络最大断开时间(秒) * 主节点每秒产生的写数据量(字节) - 实践: 假设主节点每秒产生 1MB 的写数据,你希望能够容忍网络断线 60 秒后依然能进行增量同步,那么你应该把
repl-backlog-size至少设置为 60MB(建议在此基础上再乘以 2,即 120MB,留出余量)。