 播面
播面 社交APP中,如何利用Redis实现“共同好友”、“可能认识的人”这样的关系推算功能?
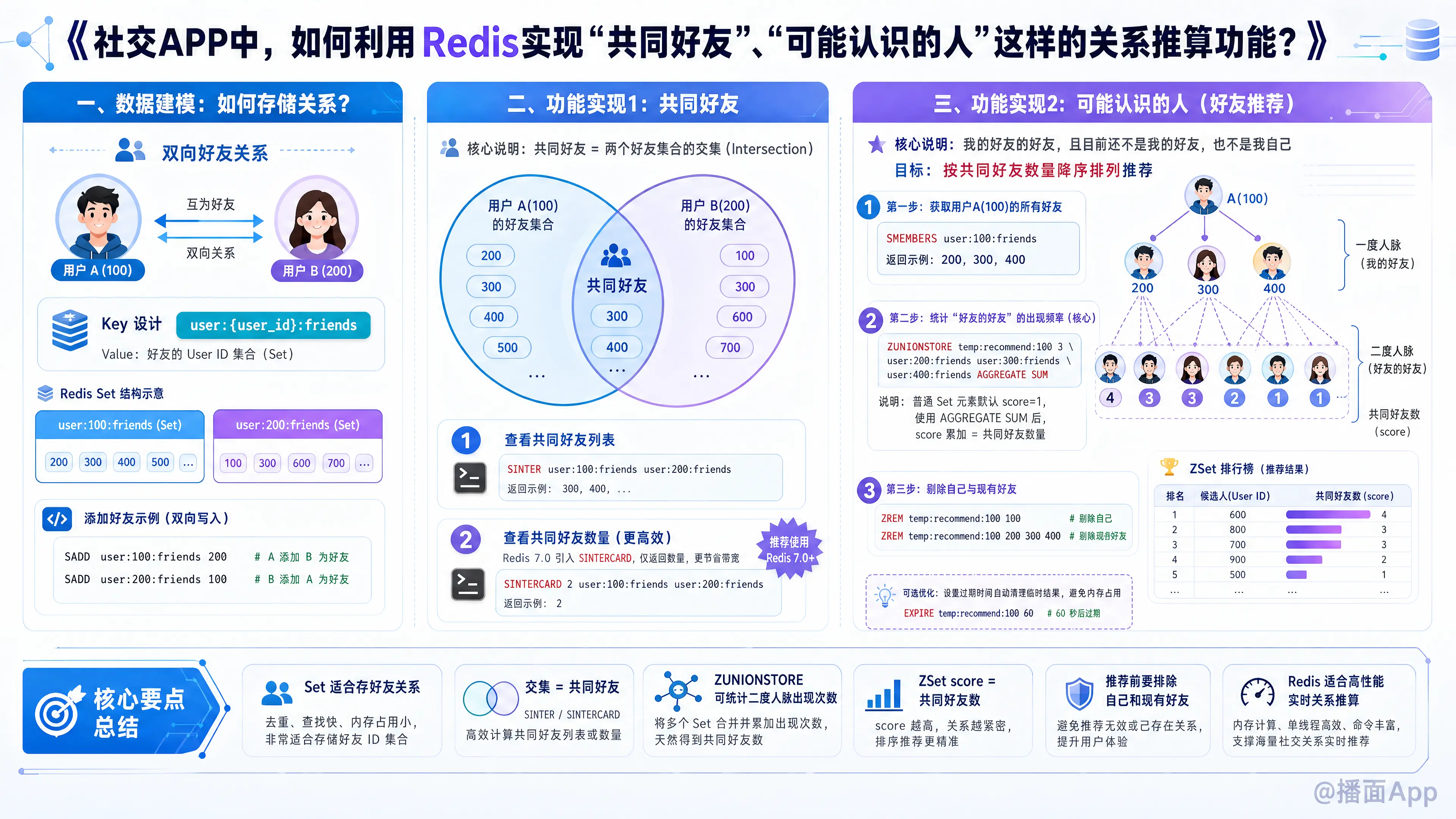
在社交APP中,实现“共同好友”和“可能认识的人”这类关系推算功能,Redis 的集合(Set)和有序集合(Sorted Set / ZSet)是绝佳的工具。因为这类功能在数学本质上就是集合的交集、并集和差集运算。
下面我将从数据建模、功能实现到生产环境优化,一步步为你拆解如何利用 Redis 实现这些功能。
一、 数据建模:如何存储关系?
假设我们的社交关系是双向好友关系(类似微信)。我们为每个用户创建一个 Redis Set,用来存储该用户的所有好友 ID。
- Key 设计:
user:{user_id}:friends - Value:好友的 User ID 集合。
添加好友时的操作:
假设用户 A (ID: 100) 和用户 B (ID: 200) 互加好友,你需要向双方的 Set 中添加对方的 ID:
SADD user:100:friends 200
SADD user:200:friends 100二、 功能实现 1:共同好友
“共同好友”的本质就是求两个用户好友集合的交集(Intersection)。
1. 查看共同好友列表
如果你想展示用户 A (100) 和用户 B (200) 的共同好友列表,使用 SINTER 命令:
# 返回 100 和 200 都有的好友 ID
SINTER user:100:friends user:200:friends 2. 查看共同好友数量
如果只需要展示“你们有 5 个共同好友”这样的数字,强烈建议使用 Redis 7.0 引入的 SINTERCARD 命令。它只在服务端计算数量并返回,不会把大量 ID 传输到网络中,极大节省带宽。
# 返回交集的数量,2 表示传入了 2 个 key
SINTERCARD 2 user:100:friends user:200:friends三、 功能实现 2:可能认识的人(好友推荐)
“可能认识的人”的推荐逻辑通常是:“我的好友的好友,且目前还不是我的好友,也不是我自己”。
为了让推荐更精准,我们通常需要按照“共同好友的数量”进行降序排列,共同好友越多,说明你们越可能认识。
这个功能完全可以通过 Redis 的 ZUNIONSTORE(有序集合并集计算)来巧妙实现。
实现步骤(以给用户 A(100) 推荐为例):
第一步:获取用户 A 的所有好友
SMEMBERS user:100:friends
# 假设返回了 200, 300, 400第二步:计算“好友的好友”的出现频率(核心技巧)
将 A 的所有好友(200, 300, 400)的好友列表进行并集计算,并将结果存入一个临时的有序集合(ZSet)中。
当 ZUNIONSTORE 处理普通的 Set 时,会默认给 Set 中的每个元素赋予 score = 1。配合 AGGREGATE SUM(默认行为),同一个 ID 出现几次,它的 score 就会累加到几。这恰好就是共同好友的数量!
# 语法:ZUNIONSTORE 目标key key数量 key1 key2...
ZUNIONSTORE temp:recommend:100 3 user:200:friends user:300:friends user:400:friends此时,temp:recommend:100 这个 ZSet 中存储了 A 的所有二度人脉,Score 就是共同好友数。
第三步:剔除掉 A 现有的好友和 A 自己
推荐列表里不能包含已经是好友的人,也不能包含自己。
# 删除自己
ZREM temp:recommend:100 100
# 删除现有的好友(假设程序里已经拿到了好友列表 200, 300, 400)
ZREM temp:recommend:100 200 300 400第四步:按共同好友数量倒序获取推荐名单
# 获取共同好友最多的前 10 个人,并带上共同好友的数量
ZREVRANGE temp:recommend:100 0 9 WITHSCORES第五步:清理临时 Key
# 阅后即焚,或者设置一个过期时间 (EXPIRE temp:recommend:100 300)
DEL temp:recommend:100四、 拓展:单向关系(关注 / 粉丝 模型)
如果是类似微博/小红书的单向关注模型,我们需要维护两个集合:
- 关注列表:
user:{id}:following - 粉丝列表:
user:{id}:followers
运算逻辑也随之变化:
- 互相关注(互粉):
SINTER user:100:following user:100:followers - 共同关注的人:
SINTER user:100:following user:200:following - 可能感兴趣的人(我关注的人也关注了谁):使用类似上述
ZUNIONSTORE的逻辑,去并集计算我关注的人的following集合。
五、 生产环境避坑指南(高级优化)
在真实的千万级甚至亿级 DAU 的应用中,直接按上述逻辑跑可能会导致 Redis 崩溃,需要注意以下几点:
防范 Big Key(大键)阻塞:
- 如果某个用户(如大 V)有 100 万好友/粉丝,
SINTER或ZUNIONSTORE这样复杂度为O(N)的命令会长时间阻塞 Redis 的单线程,导致整个系统卡顿。 - 解决方案:
- 限制普通用户的好友上限(如微信限制 1 万)。
- 对大 V 用户做特殊降级处理,不实时计算他们的关系,而是打标签或走离线推荐。
- 拆分集群,将关系计算的请求路由到从库(Read Replica),不影响主库的写入。
- 如果某个用户(如大 V)有 100 万好友/粉丝,
避免全量实时计算(冷热分离):
- “可能认识的人”不需要每次刷新都去 Redis 里执行庞大的并集计算。
- 业界标准做法:后台通过大数据平台(Hadoop/Spark/GraphDB)离线/异步计算好每个用户的推荐列表,然后直接将排好序的结果推送到 Redis 的一个 List 或 ZSet 中作为缓存(如
user:100:recommend_cache)。 - APP 端请求时,直接
ZRANGE读取缓存的推荐列表即可,只有缓存为空时,才触发一次实时 Redis 计算作为兜底。
使用 Pipeline(管道)提升性能:
- 在执行类似批量
ZREM或者多次读取好友列表的操作时,一定要使用 Redis 的 Pipeline 技术,将多条命令打包发送,大幅减少网络 RTT(往返时延)。
- 在执行类似批量
引入布隆过滤器(Bloom Filter):
- 在推荐系统中,为了确保“推荐过的人不再重复推荐”(已读过滤),可以在 Redis 中为每个用户维护一个布隆过滤器,记录已经曝光过的推荐用户 ID。
总结来说,Redis 提供了极其契合图关系运算的基础数据结构。在应用初期和中等规模下,纯 Redis 计算足够支撑;当体量演进到海量数据时,将 Redis 作为离线图计算引擎的“高速缓存层”是最佳的架构选择。