 播面
播面 YARN 与 Kubernetes (K8s) 同作为集群资源调度管理平台,它们的设计理念有什么核心区别?
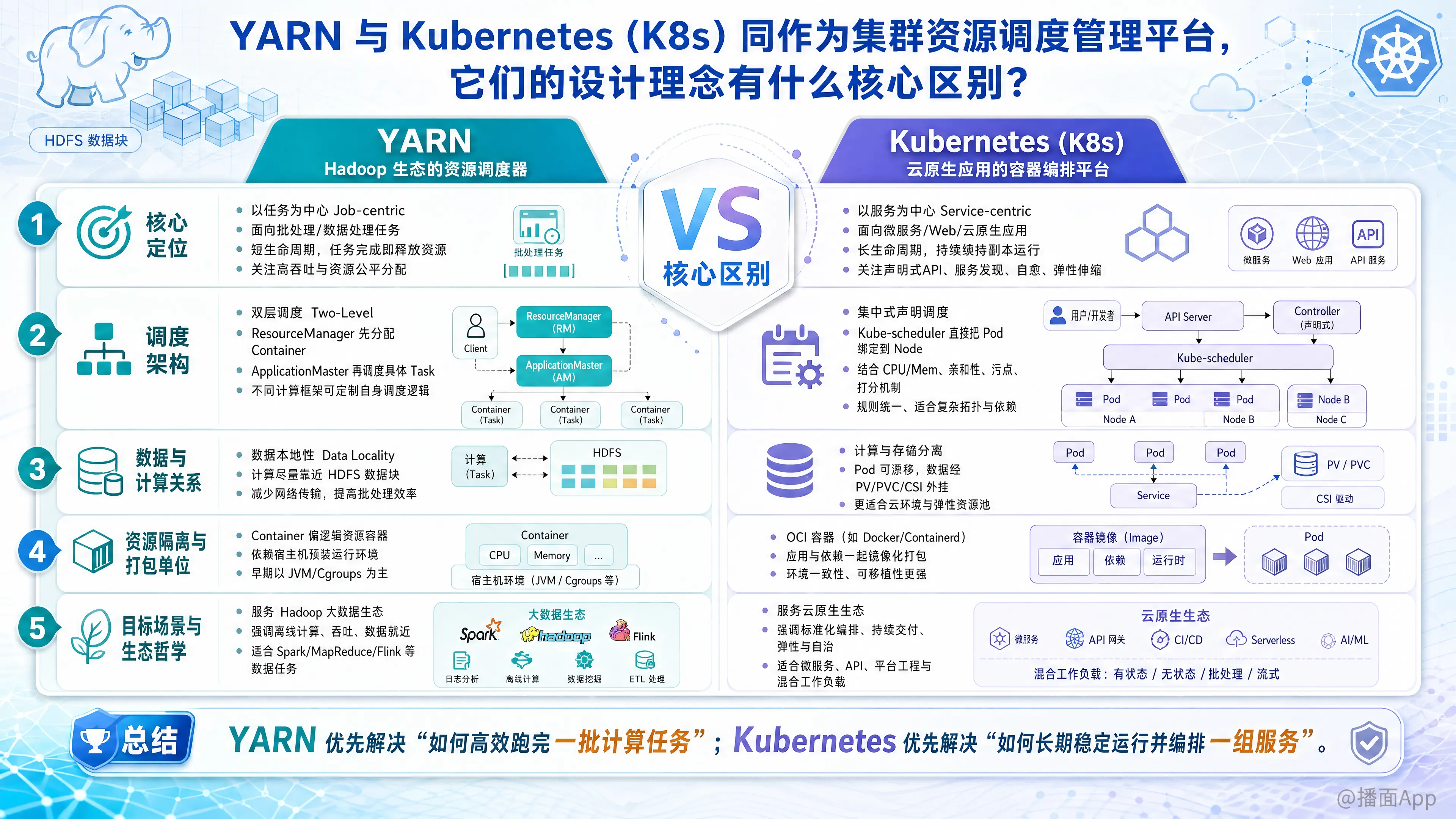
YARN(Hadoop生态)和 Kubernetes(云原生生态)虽然都是集群资源调度和管理平台,但它们分别诞生于大数据时代和云计算/微服务时代。这导致它们在设计理念、核心抽象、调度机制以及目标场景上存在着根本性的区别。
它们的核心区别可以总结为以下五个维度:
1. 核心定位:计算任务(Job-centric) vs 服务编排(Service-centric)
YARN(以任务为中心):
- 设计初衷: 为短生命周期的、高吞吐量的批处理/数据处理任务(如 MapReduce, Spark, Flink)设计。
- 生命周期: 任务导向(Ephemeral)。一个 Application 启动,申请资源,执行计算,完成后释放资源并退出。
- 核心关注点: 如何在多租户环境下,公平、高效地分配计算资源(CPU、内存),以最快速度跑完海量数据。
Kubernetes(以服务为中心):
- 设计初衷: 为长生命周期的微服务、Web应用、云原生架构设计。
- 生命周期: 常驻导向(Long-running)。核心概念是持续运行的服务(Deployment/StatefulSet)。
- 核心关注点: 状态维持(Reconciliation)、服务发现、负载均衡、自动扩缩容(HPA)、故障自愈。K8s 的理念是“声明式API”——你告诉我期望状态(例如保持3个副本),我负责永远维持这个状态。
2. 调度架构:双层调度(Two-Level) vs 集中式声明调度(Declarative Monolithic)
YARN 的双层调度模型:
- 第一层(ResourceManager): 粗粒度的资源分配。它只管把资源(Container)分配给各个应用的管理者。
- 第二层(ApplicationMaster, AM): 每个应用(如一个 Spark 任务)自带一个 AM。AM 拿到资源后,自己决定把哪个具体的 Task(比如 Map 任务还是 Reduce 任务)放到哪个 Container 里运行。
- 优势: 极大地减轻了中心节点的调度压力,允许不同的大数据框架(Spark, Tez, Flink)实现自己独特的调度逻辑。
Kubernetes 的声明式调度模型:
- 集中式调度: Kube-scheduler 是一个全局的调度器。它根据 Pod 的需求(CPU/Mem、亲和性 Affinity、污点 Taint 等),通过打分机制直接将 Pod 绑定到具体的 Node 上。
- 优势: 调度规则极其丰富且标准化,非常适合处理复杂的硬件拓扑和微服务间的依赖关系。
3. 数据与计算的关系:数据本地性(Data Locality) vs 计算与存储分离
YARN(计算向数据靠拢):
- YARN 深度绑定 HDFS。它的一个核心调度理念是数据本地性(Data Locality)。调度器会优先把计算任务(Container)分配到存储着该任务所需数据块的节点上,以减少网络传输带宽消耗。
Kubernetes(计算与数据分离):
- K8s 诞生于云环境,默认网络带宽充足。它的理念是计算和存储解耦。
- Pod 可以随时在任何节点漂移,数据则通过持久卷(PV/PVC)和 CSI 接口外挂(如 EBS, Ceph, NFS)。K8s 调度器通常不关心(或很难关心)底层数据具体存在哪块物理磁盘上。
4. 资源隔离与打包单位:JVM/Cgroups vs OCI 容器 (Docker)
YARN 的 Container:
- YARN 里的 Container 最初只是一个逻辑概念,通过 Linux Cgroups 限制 CPU 和内存。任务通常依赖于宿主机上预装的运行环境(如 Java/Python 环境)。虽然现在 YARN 也支持 Docker,但并非其原生基因。
Kubernetes 的 Pod:
- K8s 基于 OCI 标准(如 Docker, containerd)。Pod 是最小调度单元。
- 它的核心理念是不可变基础设施(Immutable Infrastructure)。应用及其所有依赖都被打包在镜像中,实现了运行环境的绝对隔离和跨环境的一致性。
5. 扩展性与生态:定制化 AM vs CRD/Operator
YARN 的扩展方式:
- 如果要在 YARN 上跑一种新架构,你需要自己用 Java 编写一套
ApplicationMaster的逻辑去和 ResourceManager 谈判。门槛较高,生态主要局限于大数据领域。
- 如果要在 YARN 上跑一种新架构,你需要自己用 Java 编写一套
Kubernetes 的扩展方式:
- K8s 被称为“云时代的操作系统”。它通过 CRD (Custom Resource Definition) 和 Operator 模式 提供了无与伦比的扩展性。不仅可以管应用,还可以管数据库、消息队列,甚至反向管理底层云资源(如 Crossplane)。
总结对照表
| 对比维度 | YARN (Hadoop生态) | Kubernetes (云原生生态) |
|---|---|---|
| 核心基因 | 大数据批处理 / 流计算 | 云原生微服务 / 容器化应用 |
| 主要工作负载 | 短周期的 Job/Application | 长周期的 Service/Deployment |
| 调度架构 | 双层调度 (RM -> AppMaster) | 集中式/声明式 (Kube-scheduler) |
| 数据理念 | 计算向数据靠拢 (数据本地性) | 计算与存储解耦 (CSI外挂存储) |
| 运行环境 | 强依赖宿主机环境 (传统Cgroups) | 镜像打包,环境绝对隔离 (OCI/Docker) |
| 容错/自愈机制 | 重试失败的 Task,完成即止 | 持续对比期望状态,Pod死掉自动重建 |
现在的融合趋势:
由于 Kubernetes 的生态过于强大,现在大数据生态正在向 K8s 靠拢(即 Big Data on K8s)。例如,Spark 原生支持将 K8s 作为集群管理器(取代 YARN);Flink 也提供了 Kubernetes Operator。未来,K8s 有望成为统一调度底层基础设施的唯一平台,而 YARN 则可能逐渐退守到纯粹的传统 Hadoop 遗留集群中。