 播面
播面 ApplicationMaster 的内存过小会导致什么问题?
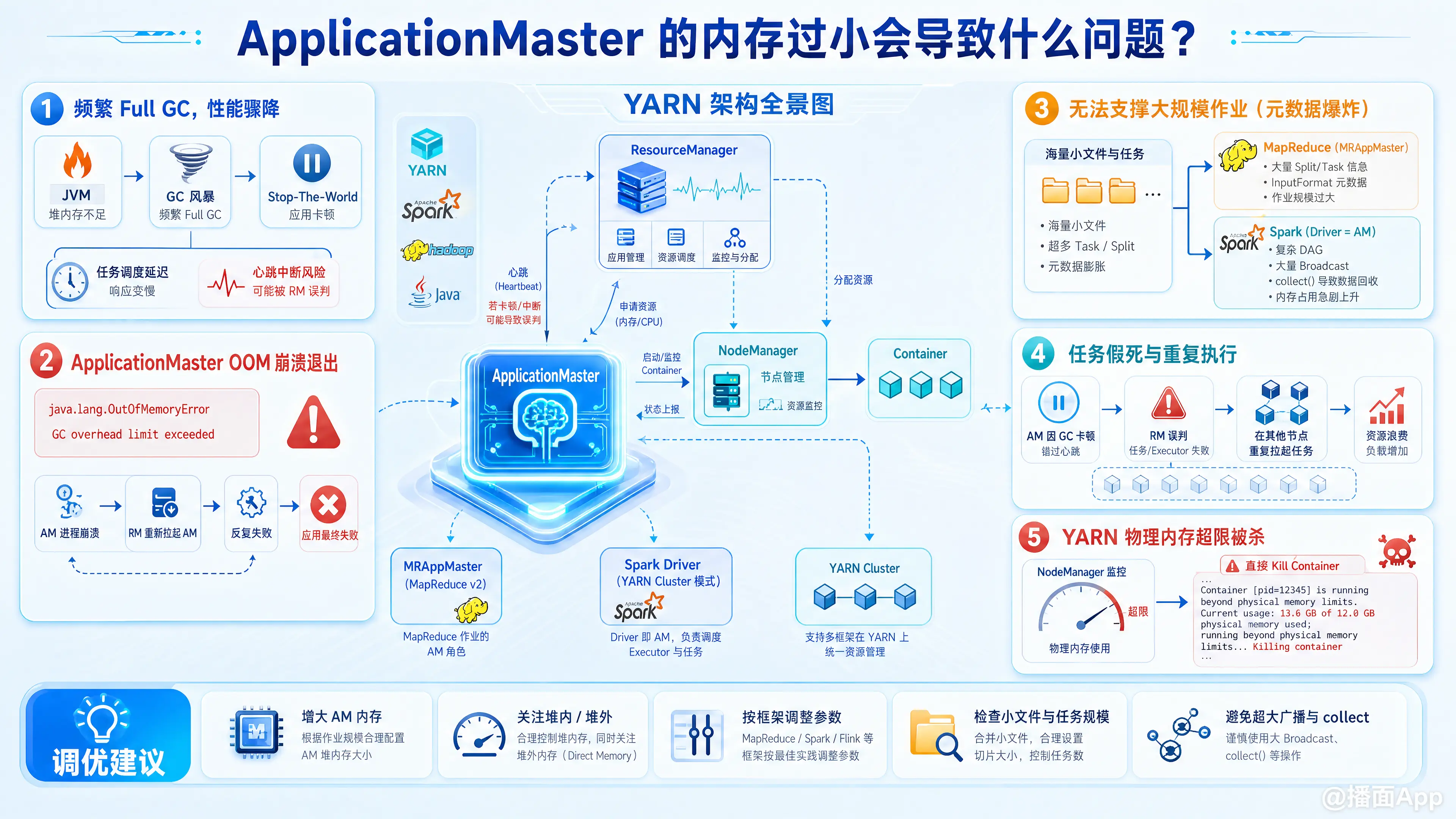
在 YARN 架构中,ApplicationMaster (AM) 是负责管理单个应用程序生命周期的核心组件。它负责向 ResourceManager 申请资源(Container)、与 NodeManager 通信启动任务、以及监控任务的运行状态。
如果 ApplicationMaster 的内存设置过小,会导致一系列严重的问题,主要可以归结为以下几个方面:
1. 频繁的 Full GC 与性能极度下降
当 AM 内存不足但尚未完全耗尽时,JVM 会频繁触发 Full GC (垃圾回收) 来尝试释放内存。
- 现象:AM 会出现严重的 "Stop-The-World"(程序暂停)现象。
- 后果:
- AM 无法及时处理来自各个 Task/Executor 的心跳信息。
- 任务调度变慢,整个作业的执行时间被大幅拉长。
- ResourceManager 可能会因为长时间收不到 AM 的心跳,误判 AM 已经挂掉。
2. ApplicationMaster 崩溃退出 (OOM)
这是最直接的后果。如果内存实在不够用,AM 会直接抛出 java.lang.OutOfMemoryError: Java heap space 或 GC overhead limit exceeded 异常并崩溃。
- 后果:YARN 默认会尝试重启失败的 AM(由参数
yarn.resourcemanager.am.max-attempts控制,默认通常是 2 次)。如果是因为作业本身元数据过大导致的内存不足,重启后的 AM 依然会 OOM,最终导致整个应用程序失败。
3. 无法支撑大规模作业(元数据爆炸)
AM 需要在内存中维护整个作业的所有 Task 的状态、进度、以及数据切片(Split)信息。
- MapReduce 作业:如果输入包含海量的小文件,或者 Map/Reduce Task 数量极多(例如达到数万个),
MRAppMaster需要消耗大量内存来存储这些任务的元数据。内存过小会导致大规模作业直接在初始化或调度阶段崩溃。 - Spark 作业(YARN Cluster 模式):在 Cluster 模式下,Spark Driver 就是 ApplicationMaster。除了任务调度,Driver 还要负责存储 DAG 图、广播变量(Broadcast Variables)、累加器,以及接收
collect()拉回的数据。如果内存太小,稍微大一点的广播变量或者复杂的 DAG 就会让应用直接 OOM 挂掉。
4. 任务假死与重复执行 (心跳超时)
AM 负责监控底层的具体计算任务(如 Map/Reduce Task 或 Spark Executor)。
- 现象:如果 AM 因为内存过小而卡顿(GC)或者处理能力下降,它可能会错过底层 Task 发来的心跳。
- 后果:AM 会错误地认为这些正常运行的 Task 已经失败,从而在其他节点上重新申请资源并拉起重复的 Task(推测执行或故障恢复机制被错误触发)。这不仅浪费集群计算资源,还可能导致数据一致性问题(如果处理不当)或加剧集群负载。
5. YARN 物理内存超限被杀 (Physical Memory Exceeded)
如果 AM 进程使用的实际物理内存(包含了 JVM 堆内存、堆外内存等)超过了 YARN 为该 Container 分配的内存上限。
- 现象:NodeManager 会直接
kill掉这个 AM 进程。 - 日志:你会看到类似
Container [pid=xxx,containerID=xxx] is running beyond physical memory limits. Current usage: 1.1 GB of 1 GB physical memory used;... Killing container.的经典报错。
💡 针对不同框架的解决与调优建议
如果你遇到了 AM 内存过小的问题,可以通过调整以下参数来增大内存:
对于纯 MapReduce 作业:
- 增加 AM 所在 Container 的物理内存申请量:
yarn.app.mapreduce.am.resource.mb(默认通常是 1536MB,大作业可调至 2048MB 或 4096MB)。 - 增加 AM 内部 JVM 堆内存大小:
yarn.app.mapreduce.am.command-opts(例如设置为-Xmx3072m,建议设置为am.resource.mb的 80% 左右)。
- 增加 AM 所在 Container 的物理内存申请量:
对于 Spark 作业 (YARN Cluster 模式):
- 在 Cluster 模式下,调大 Driver 内存即可,因为 Driver 就是 AM:
--driver-memory 4g(或者spark.driver.memory=4g)。 - 注意:如果是 YARN Client 模式,Driver 在本地,AM 只是个壳,此时需要通过
spark.yarn.am.memory(默认 512M)来调整 YARN 上那个轻量级 AM 的内存,通常 Client 模式下 AM 不需要太大内存,除非 executor 数量极大。
- 在 Cluster 模式下,调大 Driver 内存即可,因为 Driver 就是 AM:
对于 Flink 作业 (YARN 部署):
- 调整 JobManager 的内存(JobManager 在 YARN 中作为 AM 运行):在
flink-conf.yaml中修改jobmanager.memory.process.size,或者提交时使用参数-yjm 2048m。
- 调整 JobManager 的内存(JobManager 在 YARN 中作为 AM 运行):在