 播面
播面 Yarn中Capacity Scheduler 和 Fair Scheduler 的主要区别
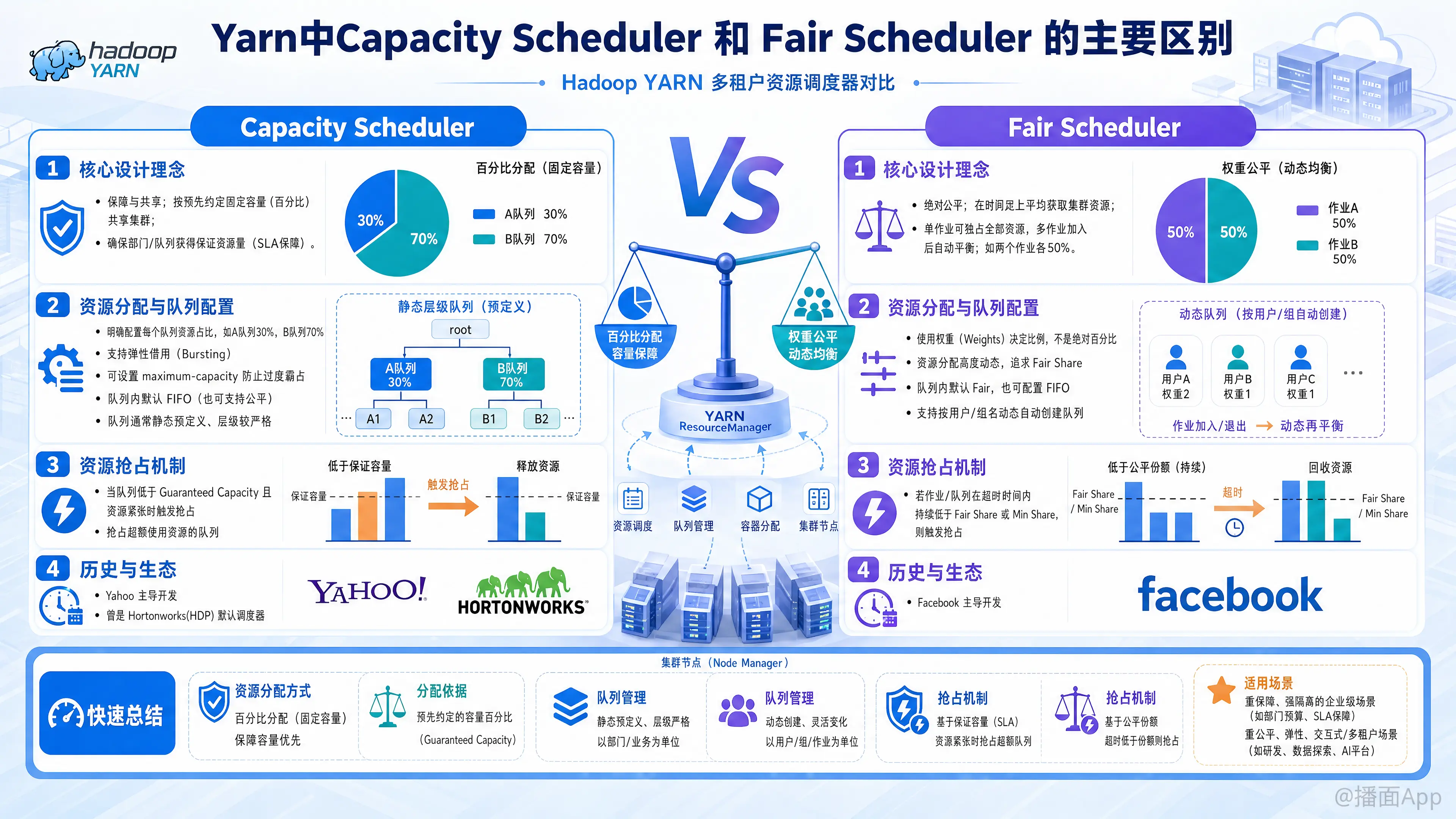
在 Hadoop YARN 中,Capacity Scheduler(容量调度器) 和 Fair Scheduler(公平调度器) 是两种最常用的多租户资源调度器。它们的设计初衷都是为了解决单一 FIFO 调度器无法满足多用户、多部门共享集群资源的问题,但在核心设计理念、资源分配策略和使用场景上存在显著差异。
以下是两者的主要区别详细对比:
1. 核心设计理念 (Core Philosophy)
- Capacity Scheduler (容量调度器):
- 核心思想: “保障”与“共享”。它的设计目标是让不同的组织或部门能够以事先约定好的固定容量(百分比)共享集群。
- 关注点: 确保每个部门(队列)在需要时至少能获得其配置的“保证资源量”(SLA保障)。
- Fair Scheduler (公平调度器):
- 核心思想: “绝对公平”。它的设计目标是让所有正在运行的应用在时间尺度上平均获取集群资源。
- 关注点: 动态平衡。如果集群中只有一个作业,它会占用全部资源;当第二个作业加入时,资源会自动调整分配,使得两个作业各占 50%。
2. 资源分配与队列配置 (Resource Allocation & Queues)
- Capacity Scheduler:
- 容量配置: 必须明确为每个队列配置资源占比(例如:A队列占30%,B队列占70%)。
- 弹性伸缩(Bursting): 如果A队列空闲,B队列可以“借用”A的资源。但可以配置一个
maximum-capacity(最大容量限制),防止B队列过度霸占资源导致A队列突然需要资源时无法回收。 - 队列内调度: 默认情况下,队列内部采用 FIFO(先进先出)策略执行任务(现在也支持配置为公平策略)。
- 队列创建: 传统上较为严格,通常需要在配置文件中预先静态定义好队列层级。
- Fair Scheduler:
- 权重配置: 队列使用“权重(Weights)”来决定资源分配的比例,而不是绝对百分比。权重为 2 的队列获得的资源大约是权重为 1 的队列的两倍。
- 动态调整: 资源分配是高度动态的,时刻朝着“让所有作业获得同等份额(Fair Share)”的目标调整。
- 队列内调度: 队列内部默认也是 Fair 策略(所有作业平分队列内的资源),也可以配置为 FIFO。
- 动态队列: 支持根据规则(如用户名、组名)动态/自动创建队列,无需事先在配置文件中写死。
3. 资源抢占机制 (Preemption)
当一个队列需要资源,而其资源正被其他队列“借用”时,调度器会触发抢占(强行杀死借用者的 Container 并收回资源)。
- Capacity Scheduler:
- 触发条件: 基于容量保证。如果一个队列的当前资源低于其保证容量(Guaranteed Capacity),且集群资源紧张,它会抢占那些超额使用资源(超出其保证容量)的队列。
- Fair Scheduler:
- 触发条件: 基于公平份额时间。如果一个作业/队列在配置的超时时间(Timeout)内,获得的资源一直低于其“公平份额(Fair Share)”或配置的“最小份额(Min Share)”,它就会触发抢占,去夺取其他队列的资源。
4. 历史渊源与生态系统 (Ecosystem & History)
- Capacity Scheduler:
- 由 Yahoo 主导开发。
- 曾是 Hortonworks (HDP) 发行版的默认调度器。
- Fair Scheduler:
- 由 Facebook 主导开发。
- 曾是 Cloudera (CDH) 发行版的默认调度器。
⚠️ 重要现状提示 (CDP 时代的统一):
随着 Cloudera 和 Hortonworks 合并为现在的 CDP (Cloudera Data Platform),官方为了整合技术栈,已将 Capacity Scheduler 作为 CDP 的唯一默认和推荐调度器。Fair Scheduler 的许多优秀特性(如动态队列)已被移植到了 Capacity Scheduler 中,Fair Scheduler 正在被逐步淘汰。
总结对比表
| 特性维度 | Capacity Scheduler (容量调度器) | Fair Scheduler (公平调度器) |
|---|---|---|
| 设计初衷 | 部门间的资源容量保障(SLA) | 所有作业之间的动态公平分享 |
| 资源划分方式 | 严格的百分比(如:保证30%,最大80%) | 相对权重(Weights)和最小共享量 |
| 队列内部默认策略 | FIFO (先进先出) | Fair (公平平分) |
| 空闲资源利用 | 允许借用(受限于最大容量上限) | 允许借用(自动向完全公平状态调整) |
| 动态创建队列 | 传统不支持(新版本受限支持) | 完全支持,可基于用户名/组自动创建 |
| 资源抢占触发依据 | 队列未达到其“保证容量” | 作业在超时时间内未达到其“公平份额” |
| 代表企业/平台 | Yahoo / HDP (Hortonworks) / CDP | Facebook / CDH (Cloudera) |
选型建议
- 如果你的公司采用现代的 Hadoop 发行版(如 CDP)或原生 Apache Hadoop 3.x+:强烈建议直接使用 Capacity Scheduler。因为它现在已经吸收了 Fair Scheduler 的大部分优点(例如也支持 Dominant Resource Fairness DRF 算法),并且是社区后续维护的重心。
- 如果业务场景强调“按部门核算成本,必须保证核心部门随时有固定资源可用”:Capacity Scheduler 的思想更契合。
- 如果业务场景是“以数据科学家临时探索分析为主,希望每个人的查询都能获得同样的体验”(基于老集群):Fair Scheduler 的动态公平特性体验更好。