 播面
播面 Yarn的 Capacity Scheduler(容量调度器)
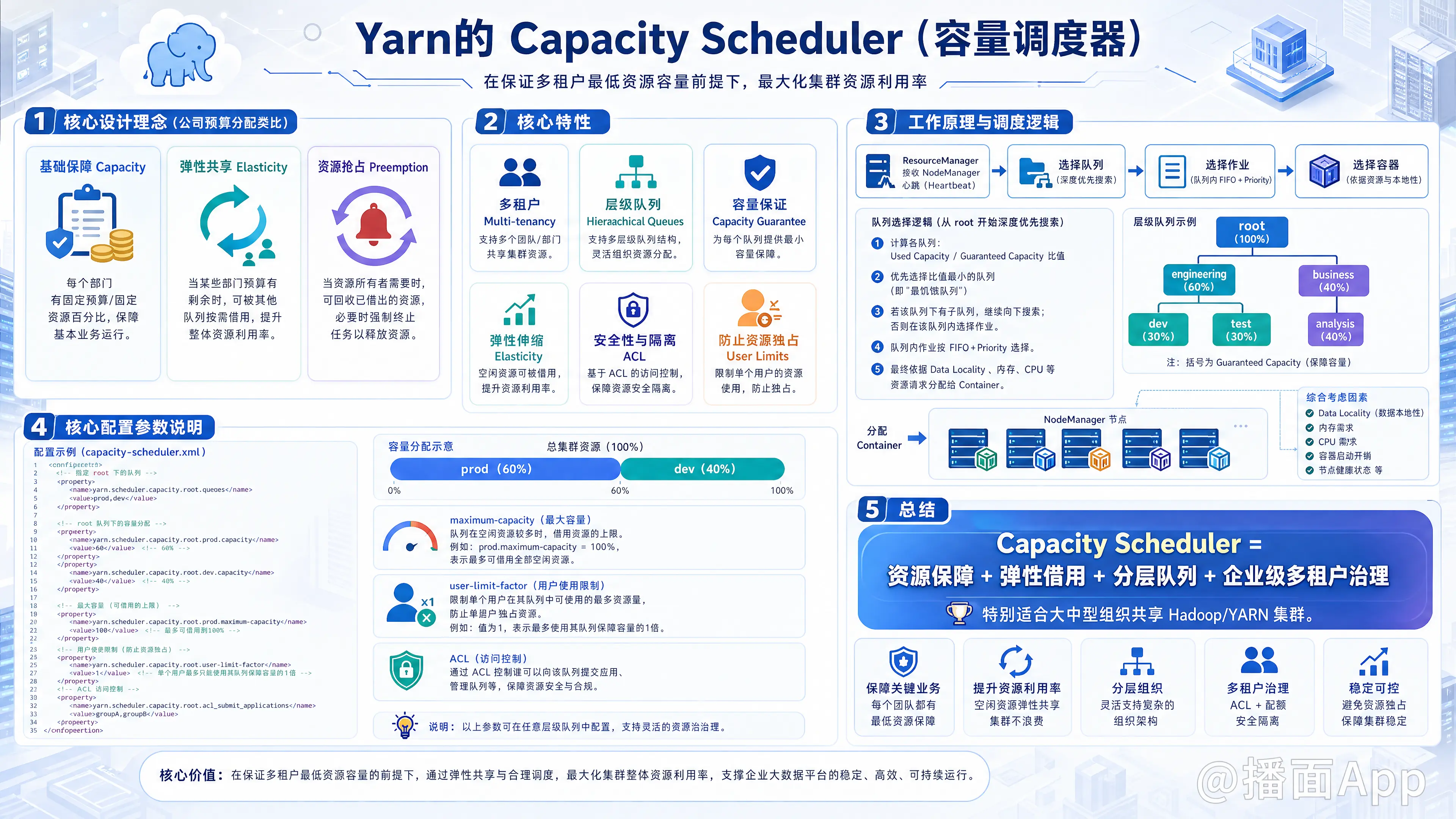
YARN 的 Capacity Scheduler(容量调度器) 是 Hadoop YARN 中最核心、在企业中使用最广泛的资源调度器之一(特别是 Hortonworks 和目前的 Cloudera CDP 默认使用的调度器)。
它的核心设计思想是“在保证多租户(多个团队/部门)最低资源容量的前提下,最大化集群的资源利用率”。
以下是对 Capacity Scheduler 的全面解析:
1. 核心设计理念
可以将 Capacity Scheduler 想象成公司的年度预算分配机制:
- 基础保障(Capacity): 每个部门(如研发部、市场部)都有自己固定的预算(资源百分比)。只要你需要,这部分资源一定能给你。
- 弹性共享(Elasticity): 如果市场部今天没有用完他们的预算,研发部可以“借用”这部分空闲资源,从而避免集群资源闲置。
- 资源抢占(Preemption): 当市场部突然需要用资源时,YARN 会要求研发部归还借用的资源;如果研发部不主动归还,YARN 会强制杀死研发部的部分任务,把资源还给市场部。
2. 核心特性
- 多租户(Multi-tenancy): 支持多个组织共享整个 Hadoop 集群,通过队列配置实现资源隔离,互不干扰。
- 层级队列(Hierarchical Queues): 支持将队列设计成树状结构,映射企业的组织架构。例如:
root -> engineering -> dev和root -> engineering -> test。 - 容量保证(Capacity Guarantee): 每个队列配置一个基础容量百分比,所有同级队列的基础容量相加必须等于 100%。
- 弹性伸缩(Elasticity): 队列可以设置一个“最大容量(Maximum Capacity)”。当集群有空闲资源时,队列可以突破基础容量,最多使用到最大容量。
- 安全性与隔离(Security): 可以配置 ACL(访问控制列表),限制哪些用户可以向特定队列提交任务,或者谁可以杀死特定队列的任务。
- 防止资源独占(User Limits): 可以限制单个用户在一个队列中最多能使用的资源比例,防止某个疯狂提交任务的用户占满整个队列。
3. 工作原理与调度逻辑
当 ResourceManager 收到 NodeManager 的心跳(表示有空闲资源)时,Capacity Scheduler 会按照以下顺序进行分配:
- 选择队列: 调度器从根队列(root)开始,采用深度优先算法,寻找当前资源使用率最低(Used Capacity / Guaranteed Capacity 比值最小)的队列。这样可以保证资源最饥饿的队列优先得到资源。
- 选择作业(App): 在选定的队列内部,默认按照 FIFO(先进先出) 加 作业优先级(Priority) 的策略选择作业。
- 选择容器(Container): 根据作业的资源请求(如数据本地性 Data Locality、内存大小),将空闲资源分配给具体的任务。
4. 核心配置参数说明
Capacity Scheduler 的配置通常在 capacity-scheduler.xml 中进行。以下是几个最重要的配置项:
假设我们有如下需求:集群分给 prod (生产环境) 和 dev (开发环境) 两个队列,分别占 60% 和 40% 的资源。
- 定义队列结构:xml
<property> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> - 设置基础容量 (Capacity): 必须保证同级队列相加为 100%。xml
<property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>60</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>40</value> </property> - 设置最大容量 (Maximum Capacity): 限制队列最多能借用多少资源。xml
<property> <name>yarn.scheduler.capacity.root.dev.maximum-capacity</name> <value>100</value> <!-- 开发环境闲时可以用满集群 --> </property> <property> <name>yarn.scheduler.capacity.root.prod.maximum-capacity</name> <value>100</value> </property> - 用户资源限制 (User Limit):xml
<property> <name>yarn.scheduler.capacity.root.dev.minimum-user-limit-percent</name> <value>50</value> <!-- 即使只有一个用户,最多只能使用dev队列50%的资源(如果有其他用户的话) --> </property>
5. YARN 三大调度器对比
| 特性 | FIFO Scheduler (先进先出) | Fair Scheduler (公平调度器) | Capacity Scheduler (容量调度器) |
|---|---|---|---|
| 设计目标 | 简单快速,单用户 | 动态平均分配,无明确保障 | 多租户,明确的容量保障与弹性共享 |
| 队列结构 | 单一队列 | 扁平或层级队列 | 层级队列 (树状结构) |
| 资源分配 | 按提交顺序排队,大的任务会阻塞后面的小任务 | 动态调整,所有任务获得大致相等的资源份额 | 按配置的百分比保证基础容量,空闲可借用 |
| 适用场景 | 测试环境,个人使用 | CDH旧版本的默认选择,看重公平性 | CDP/HDP默认选择,大型企业、多部门共享集群 |
(注:在最新的 Hadoop 3.x 版本中,Fair Scheduler 的功能已经完全被合并到了 Capacity Scheduler 中,官方推荐统一使用 Capacity Scheduler。)
6. 企业生产环境的最佳实践
- 合理设置
maximum-capacity: 对于核心生产队列(如实时计算、核心数仓),不要让其他低优先级队列(如个人测试队列)的最大容量设置过高。虽然有抢占机制,但“杀任务归还资源”需要时间,可能会导致生产任务出现短暂延迟。 - 开启并调优抢占机制(Preemption): 默认情况下,抢占可能是关闭的。在多租户且资源紧张的环境中,必须开启抢占,否则“借出”的资源可能要等任务自然结束才能收回。
- 结合节点标签(Node Labels): Capacity Scheduler 完美支持 Node Labels。可以将集群中性能最好的几台机器打上
GPU或High-Memory标签,并将其作为一个专属资源池分配给特定的机器学习或重度计算队列。 - 按业务线划分队列: 队列层级不要太深(一般 2-3 层即可),建议按照“事业部 -> 业务线”或“生产 -> 离线/实时”来划分。