 播面
播面 NodeManager 是如何监控 Container 的资源使用情况的?
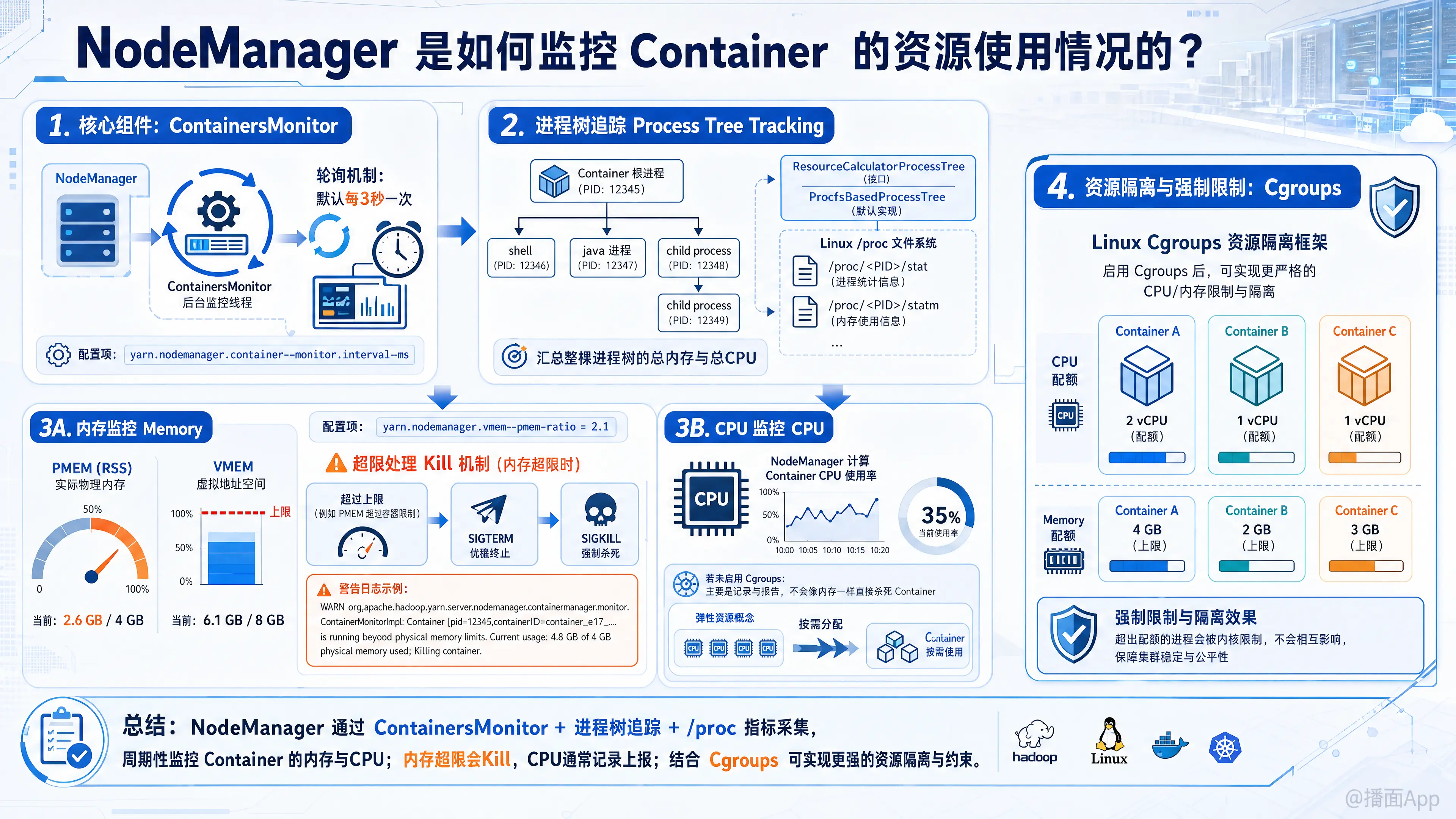
在 Hadoop YARN 架构中,NodeManager (NM) 是运行在每个计算节点上的代理,负责该节点上 Container 的生命周期管理。其中,监控 Container 的资源使用情况是 NodeManager 的核心功能之一,主要为了防止某个 Container 恶意或意外地消耗过多资源,从而影响节点上其他 Container 或系统基础服务的运行。
NodeManager 监控 Container 资源使用情况的机制主要依赖于以下几个核心组件和操作系统特性:
1. 核心组件:ContainersMonitor
在 NodeManager 内部,有一个专门的后台服务叫做 ContainersMonitor(具体实现类通常是 ContainersMonitorImpl)。
- 轮询机制:这个服务会启动一个监控线程,按照一定的时间间隔(默认是 3秒,可通过
yarn.nodemanager.container-monitor.interval-ms配置)周期性地醒来。 - 收集指标:每次醒来时,它会去收集当前节点上所有正在运行的 Container 的资源(主要是 CPU 和内存)使用数据。
2. 进程树追踪 (Process Tree Tracking)
一个 Container 往往不止包含一个单一的进程。例如,YARN 启动一个 shell 脚本,该脚本又启动了一个 Java 进程,Java 进程可能还会派生子进程。NodeManager 必须监控这整个进程组。
ResourceCalculatorProcessTree:NodeManager 使用这个工具类来构建和追踪 Container 的进程树。- 基于
/proc文件系统 (Linux 环境):在 Linux 上,默认使用ProcfsBasedProcessTree。它通过读取 Linux 系统的/proc目录(特别是/proc/<PID>/stat和/proc/<PID>/statm等文件)来发现 Container 根进程的所有子进程,并汇总计算这棵进程树上的总内存(物理内存和虚拟内存)和总 CPU 使用率。
3. 监控的具体资源类型及策略
A. 内存监控 (Memory)
内存监控是 YARN 中最严格的监控项。NodeManager 会同时监控物理内存 (PMEM) 和虚拟内存 (VMEM)。
- 物理内存 (PMEM):计算进程树实际占用的 RAM (Resident Set Size, RSS)。
- 虚拟内存 (VMEM):计算进程树申请的虚拟地址空间。YARN 默认规定虚拟内存的上限是物理内存的 2.1 倍(由
yarn.nodemanager.vmem-pmem-ratio配置)。 - 超限处理 (Kill 机制):如果在某次轮询中,
ContainersMonitor发现某个 Container 的 PMEM 或 VMEM 使用量超过了分配给它的上限,NodeManager 会立刻向该 Container 的进程树发送 SIGTERM 信号,随后发送 SIGKILL 信号将其强制杀死。
(常见的报错日志:Container [pid] is running beyond physical memory limits. Current usage: X GB. Limit: Y GB. Killing container.)
B. CPU 监控 (CPU)
与内存的“硬杀”策略不同,CPU 是一种“弹性”资源。
- NodeManager 同样会计算 Container 的 CPU 使用率。
- 如果没有启用 Cgroups,NodeManager 对 CPU 的监控仅仅是记录和报告,即使 Container 使用的 CPU 超出了申请量,通常也不会被杀死(除非节点整体 CPU 负载过高导致系统级干预)。
4. 资源隔离与强制限制:Cgroups (Control Groups)
虽然 NodeManager 自己的轮询监控可以兜底,但在现代生产环境中,通常会开启 Linux 的 Cgroups (控制组) 特性(配置 yarn.nodemanager.linux-container-executor.resources-handler.class = CGroupsLCEResourcesHandler)。
开启 Cgroups 后,监控和限制机制发生了本质的变化:
- CPU 隔离:Cgroups 可以严格限制 Container 只能使用特定比例的 CPU 时间片(甚至绑定特定的 CPU 核心)。如果 Container 尝试超额使用 CPU,操作系统底层会将其降速(Throttle),而不是杀死。
- 内存隔离:如果 Container 尝试使用超过 Cgroups 限制的物理内存,Linux 内核的 OOM Killer (Out-Of-Memory Killer) 会在操作系统级别直接将其杀死。这比 NodeManager 每 3 秒一次的轮询反应更快、更精准。
5. 相关的重要配置项 (yarn-site.xml)
管理员可以通过以下参数调整 NodeManager 的监控行为:
| 配置项 | 默认值 | 作用 |
|---|---|---|
yarn.nodemanager.container-monitor.interval-ms |
3000 |
NodeManager 轮询监控资源的时间间隔(毫秒)。 |
yarn.nodemanager.pmem-check-enabled |
true |
是否开启物理内存检查。 |
yarn.nodemanager.vmem-check-enabled |
true |
是否开启虚拟内存检查。(注:CentOS 6/7 环境下,Java 进程很容易造成 VMEM 假性飙高,现代集群常将其设为 false) |
yarn.nodemanager.vmem-pmem-ratio |
2.1 |
虚拟内存与物理内存的允许比例。 |
yarn.nodemanager.resource.percentage-physical-cpu-limit |
100 |
所有 Container 最多可使用的节点物理 CPU 比例。 |
总结
NodeManager 监控 Container 资源主要是通过 定期轮询(默认3秒) + 解析 Linux /proc 文件系统 来计算整个 Container 进程树 的 CPU 和内存消耗。如果发现内存超限,NM 会主动 Kill 掉容器;而在开启了 Cgroups 的集群中,资源的限制和隔离则进一步下放给了 Linux 操作系统内核,以实现更底层的硬限制(CPU 降速,内存 OOM Kill)。