 播面
播面 如果NameNode出现RPC响应延迟高、Full GC频繁,你通常会从哪些角度进行调优?
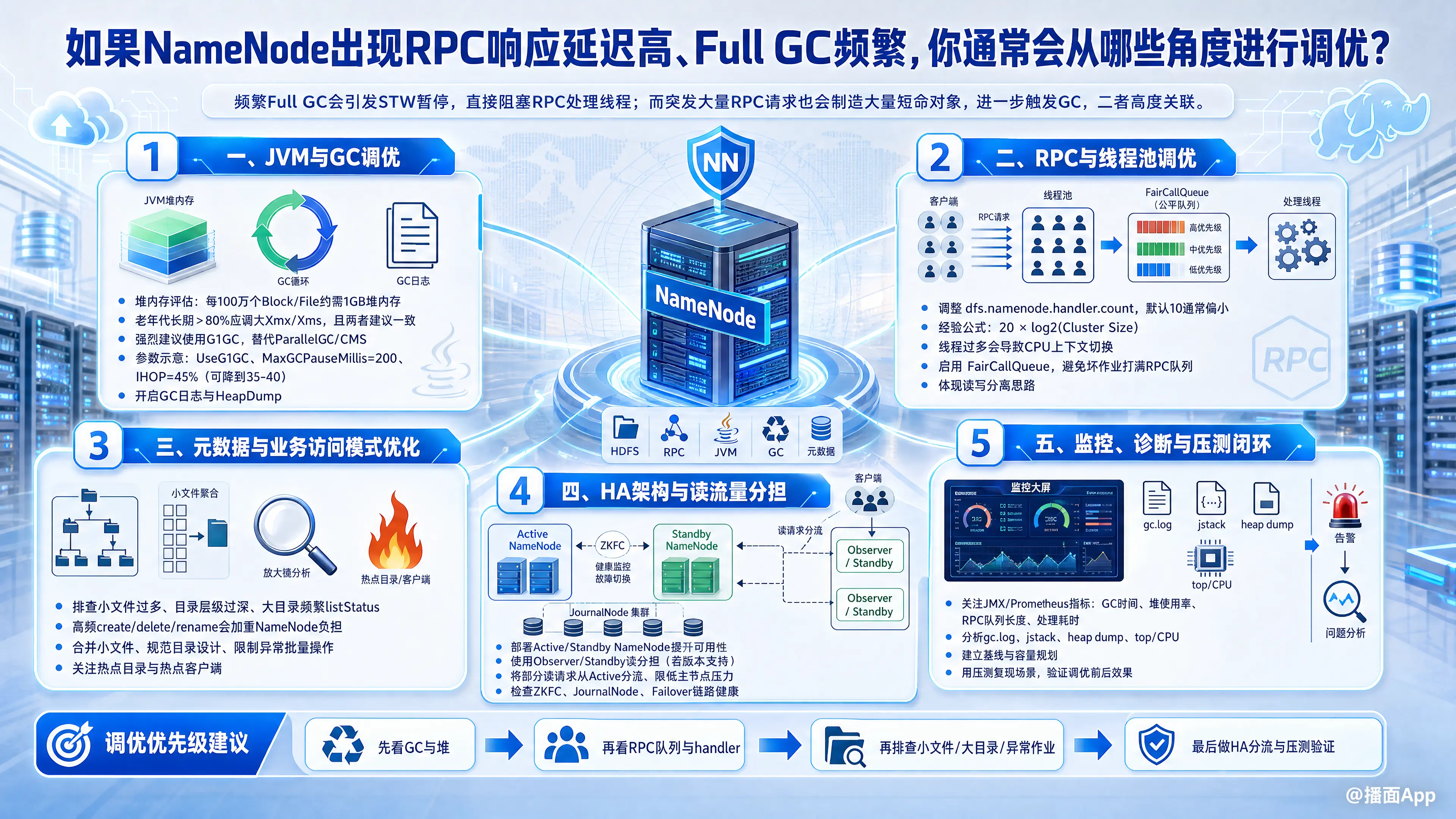
NameNode出现 RPC响应延迟高 和 Full GC频繁 是高度关联的两个症状。通常情况下,频繁的Full GC会导致JVM发生STW(Stop-The-World)暂停,从而直接阻塞RPC处理线程,导致RPC响应延迟飙升;反过来,突发的大量RPC请求(如大量创建文件、列出大目录)会产生大量短期存活对象,迅速撑爆堆内存,从而触发GC。
作为一个有经验的大数据运维/开发人员,我会从以下 五个维度 进行排查和系统性调优:
一、 JVM与GC调优(解决Full GC频繁)
这是最直接的缓解手段。NameNode是典型的内存密集型应用,管理着整个HDFS的元数据。
- 评估并调整堆内存大小(Heap Size)
- 规则:通常每 100万个Block/File 需要约 1GB 的堆内存。
- 操作:通过观察JMX指标计算当前元数据量。如果堆内存经常处于高水位(比如老年代使用率长期>80%),必须调大
-Xmx和-Xms(两者建议设为一致,避免扩容开销)。
- 切换并优化垃圾回收器(强烈建议使用G1GC)
- 对于大内存(>8GB)的NameNode,默认的 ParallelGC 会导致极长的 STW 时间,CMS容易产生内存碎片。必须使用 G1GC。
- G1核心参数调优:
-XX:+UseG1GC:启用G1。-XX:MaxGCPauseMillis=200:设置期望的最大GC停顿时间(默认200ms)。不要设置得太小,否则会导致频繁的Young GC,反而降低吞吐量。-XX:InitiatingHeapOccupancyPercent=45(IHOP):默认45%。如果发现Mixed GC跟不上对象分配速度导致Full GC,可以适当调低(如 35-40),让G1提早介入回收。-XX:G1NewSizePercent和-XX:G1MaxNewSizePercent:合理限制年轻代大小,防止年轻代过大导致复制成本高,或者过小导致对象过早晋升到老年代。
- 开启GC日志与内存溢出快照
- 确保开启
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log。 - 加上
-XX:+HeapDumpOnOutOfMemoryError,为极端情况下的事后分析保留证据。
- 确保开启
二、 RPC与线程池调优(缓解并发压力)
当JVM正常时,RPC延迟高通常是因为请求队列积压或处理线程不足。
- 调整RPC Handler数量
dfs.namenode.handler.count:默认值通常太小(10)。- 经验公式:
20 * log2(Cluster Size)。例如 100台节点的集群,建议设置为20 * log2(100) ≈ 132。不要盲目调得极大,过多的线程会导致严重的CPU上下文切换。
- 启用 FairCallQueue(公平调度队列)
- 痛点:经常有某个“糟糕的作业”(如死循环频繁调用
listStatus)打满RPC队列,导致整个集群瘫痪。 - 优化:将FIFO队列改为多级反馈队列,对请求量大的用户进行降级。
- 配置:xml
<property> <name>ipc.8020.callqueue.impl</name> <value>org.apache.hadoop.ipc.FairCallQueue</value> </property>
- 痛点:经常有某个“糟糕的作业”(如死循环频繁调用
- RPC读写分离
- 大量耗时的写请求可能会阻塞快速的读请求。
- 配置
ipc.8020.faircallqueue.multiplexer.weights等参数,将读请求和写请求分发到不同的处理队列。
- 开启 RPC Backoff(客户端退避)
- 配置
ipc.8020.backoff.enable = true。当NameNode的RPC队列满了时,直接抛出RetriableException,让客户端等待一段时间再重试,而不是在队列死等。
- 配置
三、 HDFS架构与元数据层面优化(治本:减轻NameNode负荷)
如果集群规模极大或使用姿势不对,单纯调优JVM和RPC是无济于事的。
- 治理小文件问题(最常见的元数据杀手)
- NameNode的内存中,每个文件/目录/Block平均占用约 150 Byte。海量小文件不仅消耗内存(导致Full GC),还增加RPC交互次数。
- 解决方案:
- 离线数仓:定期执行文件合并(Compact),使用 CombineFileInputFormat。
- 归档:使用 Hadoop Archive (HAR) 技术。
- 规范:限制Spark/Hive作业的输出文件数(如
repartition或coalesce)。
- 打散 DataNode 的 Block Report 风暴
- 如果集群节点多,所有DataNode在重启或特定时间同时向NN发送全量块汇报(Block Report),会瞬间产生巨大RPC压力和大量短存活对象。
- 优化:确保
dfs.blockreport.initialDelay处于开启状态,打散启动时的汇报时间;日常汇报间隔dfs.blockreport.intervalMsec默认6小时,通常不需要改小。
- 实施 HDFS Federation (Router-Based Federation, RBF)
- 如果单一NameNode已经达到物理极限(如内存>256GB,文件数>几亿),必须考虑横向扩展。通过 Router 将不同的目录(如
/user/hive,/hbase)映射到不同的独立 NameNode (Namespace) 上。
- 如果单一NameNode已经达到物理极限(如内存>256GB,文件数>几亿),必须考虑横向扩展。通过 Router 将不同的目录(如
四、 监控与审计(找到“罪魁祸首”)
调优不能凭空猜测,需要用数据说话。
- 分析 Audit Log(审计日志)
- 编写脚本或使用ELK/Splunk分析
hdfs-audit.log。 - 寻找 Top-N IP 和 Top-N 操作。通常会发现某个特定的Spark作业或定时任务在疯狂调用
getFileInfo或listStatus大目录。 - 注意:确保Audit Log配置为异步写入(
AsyncRollingFileAppender),否则磁盘I/O抖动会反向阻塞NameNode。
- 编写脚本或使用ELK/Splunk分析
- 使用 JMX 和 Metrics 系统
- 监控
RpcQueueTimeNumOps和RpcProcessingTimeNumOps。如果 QueueTime 远大于 ProcessingTime,说明请求在排队,需要调大 Handler 或排查是否有慢请求卡住线程。
- 监控
- 抓取 Jstack 和 Heap Dump
- 在延迟高发期,执行
jstack <NameNode-PID>查看 Handler 线程在等什么(是在等全局读写锁FSNamesystem lock,还是在等外部存储系统?)。 - 如果发生 OOM 或 Full GC 无法回收,拿到 Heap Dump 后用 MAT (Memory Analyzer Tool) 分析,找出占用内存最多的对象类型。
- 在延迟高发期,执行
总结排查路径:
看监控定位现象 -> 查GC日志看是否STW -> 若是内存问题:查小文件/改G1GC参数/扩容 -> 若是并发问题:看AuditLog抓出异常应用/开启FairCallQueue/调大RPC Handler -> 长远规划:小文件治理与Federation。