 播面
播面 讲讲ViewFS(View File System)在HDFS Federation中的作用。
在 Hadoop 分布式文件系统(HDFS)的发展历程中,HDFS Federation(联邦) 和 ViewFS(View File System,视图文件系统) 是两个紧密相连的概念。
简单来说:HDFS Federation 解决了 NameNode 的扩展性问题(把大集群拆成多个 NameNode 管理),而 ViewFS 则负责帮客户端把这些拆散的 NameNode 重新“拼”成一个统一的、逻辑上的文件系统。
下面为您详细拆解 ViewFS 在 HDFS Federation 中的具体作用和工作原理:
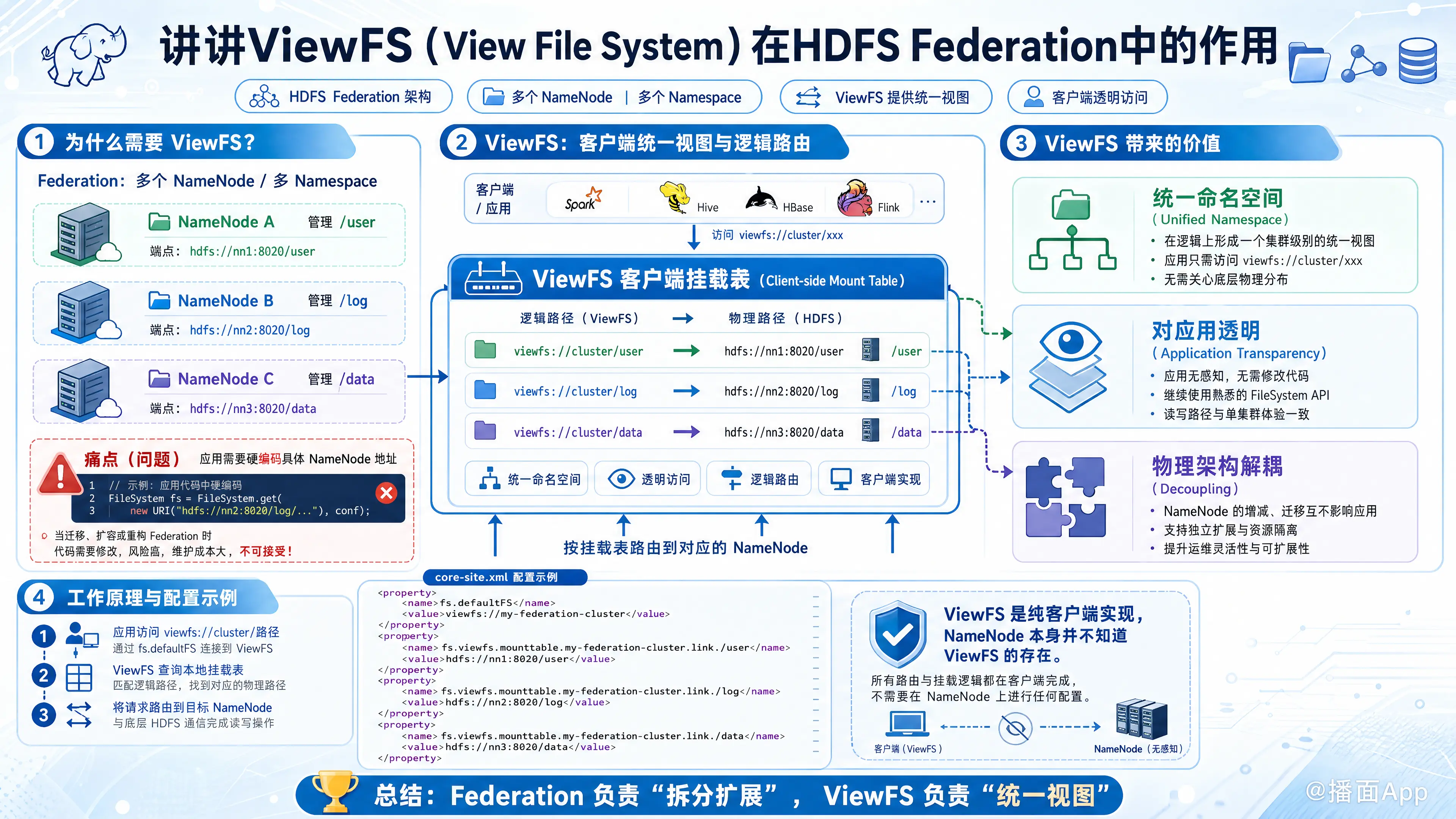
1. 为什么需要 ViewFS?(解决什么痛点)
在 HDFS Federation 架构出现之前,一个 HDFS 集群只有一个 NameNode,客户端访问数据非常简单,直接访问 hdfs://namenode:8020/ 即可。
引入 Federation 后,一个集群中有了多个互不相关的 NameNode(即多个 Namespace/命名空间)。例如:
- NameNode A 专门管理用户目录:
hdfs://nn1/user/ - NameNode B 专门管理日志数据:
hdfs://nn2/log/ - NameNode C 专门管理业务数据:
hdfs://nn3/data/
痛点: 如果没有 ViewFS,客户端或应用程序(如 MapReduce、Spark)必须硬编码知道具体的物理位置。如果用户想读取日志,必须写 hdfs://nn2/log/...。如果管理员后来把日志数据迁移到了 NameNode C,所有的应用程序代码都需要修改,这在生产环境中是不可接受的。
2. ViewFS 的核心作用
ViewFS 的核心作用是提供客户端视角的统一命名空间(Client-side Mount Table)。
它就像 Linux 系统中的 fstab(挂载表),或者一种虚拟的路由层。它在客户端拦截用户的路径访问请求,并根据配置好的“挂载表”,将逻辑路径翻译并路由到真实的物理 NameNode 上。
具体作用表现为:
- 统一命名空间(Unified Namespace): 将多个分散的 HDFS URI 组合成一个单一的逻辑目录树。例如,用户只需要访问
viewfs://cluster_name/user和viewfs://cluster_name/log。 - 对应用程序透明(Transparency): 应用程序依然感觉自己是在访问一个单一的 HDFS 集群。不需要修改代码,只需要把默认文件系统修改为
viewfs://。 - 物理架构解耦: 管理员可以在后端自由地增加 NameNode、拆分目录或迁移数据,只需更新客户端的 ViewFS 挂载配置即可,业务侧无感知。
3. ViewFS 是如何工作的?(工作原理)
ViewFS 完全是一个纯客户端(Client-side) 的实现。NameNode 本身根本不知道 ViewFS 的存在。
管理员需要在 Hadoop 集群的客户端配置文件(主要是 core-site.xml)中定义挂载表(Mount Table)。
配置示例:
<!-- 1. 将默认的文件系统设置为 ViewFS -->
<property>
<name>fs.defaultFS</name>
<value>viewfs://my-federation-cluster</value>
</property>
<!-- 2. 配置挂载表:把逻辑路径 /user 映射到 NameNode A -->
<property>
<name>fs.viewfs.mounttable.my-federation-cluster.link./user</name>
<value>hdfs://nn1:8020/user</value>
</property>
<!-- 3. 配置挂载表:把逻辑路径 /data 映射到 NameNode B -->
<property>
<name>fs.viewfs.mounttable.my-federation-cluster.link./data</name>
<value>hdfs://nn2:8020/data</value>
</property>工作流程:
- 客户端代码请求访问
/data/table1/part.txt。 - ViewFS 检查
fs.defaultFS,发现当前处于viewfs://my-federation-cluster环境下。 - ViewFS 查找挂载表,发现
/data对应的是hdfs://nn2:8020/data。 - ViewFS 自动将请求重写为
hdfs://nn2:8020/data/table1/part.txt。 - ViewFS 底层调用 HDFS 客户端 API,直接与
nn2通信并获取数据。
4. ViewFS 的局限性与注意事项
虽然 ViewFS 解决了联邦架构下的访问问题,但由于物理上数据仍然分布在不同的 NameNode 上,它也有一些不可忽视的局限性:
- 跨 NameNode 的 Rename(重命名/移动)操作失败:
你不能执行mv /user/file.txt /data/file.txt。因为/user和/data属于不同的 NameNode,HDFS 不支持跨 NameNode 的元数据原子移动。如果需要移动,必须走完整的读写拷贝(DistCp)。 - 配额(Quota)管理隔离:
由于 Quota 是在 NameNode 级别管理的,你无法设置一个跨越多个挂载点的全局目录 Quota。 - 配置分发负担重(运维痛点):
因为 ViewFS 是在客户端生效的,这意味着如果你修改了挂载表(例如增加了新的 NameNode),你需要把这份新的core-site.xml分发到集群中成百上千个所有提交任务的客户端节点。一旦有节点遗漏,就会出现访问失败。
5. 补充:从 ViewFS 到 RBF(HDFS 联邦的进化)
正是因为 ViewFS 存在“配置需要在所有客户端同步”这个巨大的运维痛点,Hadoop 在 2.9/3.0 版本之后引入了 Router-Based Federation (RBF,基于路由的联邦)。
- ViewFS 是客户端路由(逻辑在 Client)。
- RBF 是服务端路由(逻辑在专用的 Router 节点)。
在 RBF 架构中,客户端只要把请求发给 Router,Router 内部维护了一张全局挂载表(存在 ZooKeeper 或 State Store 中),由 Router 负责把请求转发给底层的各个 NameNode。这样客户端就彻底不需要配置复杂的挂载表了。
总结
在 HDFS Federation 架构中,ViewFS 扮演了“路由器”和“翻译官”的角色。它通过客户端挂载表的技术,掩盖了底层多个 NameNode 的复杂性,为上层应用提供了一个统一的、透明的、逻辑上的 HDFS 文件系统视图。