 播面
播面 在HDFS Federation架构中,Block Pool和Namespace Volume的关系是什么?
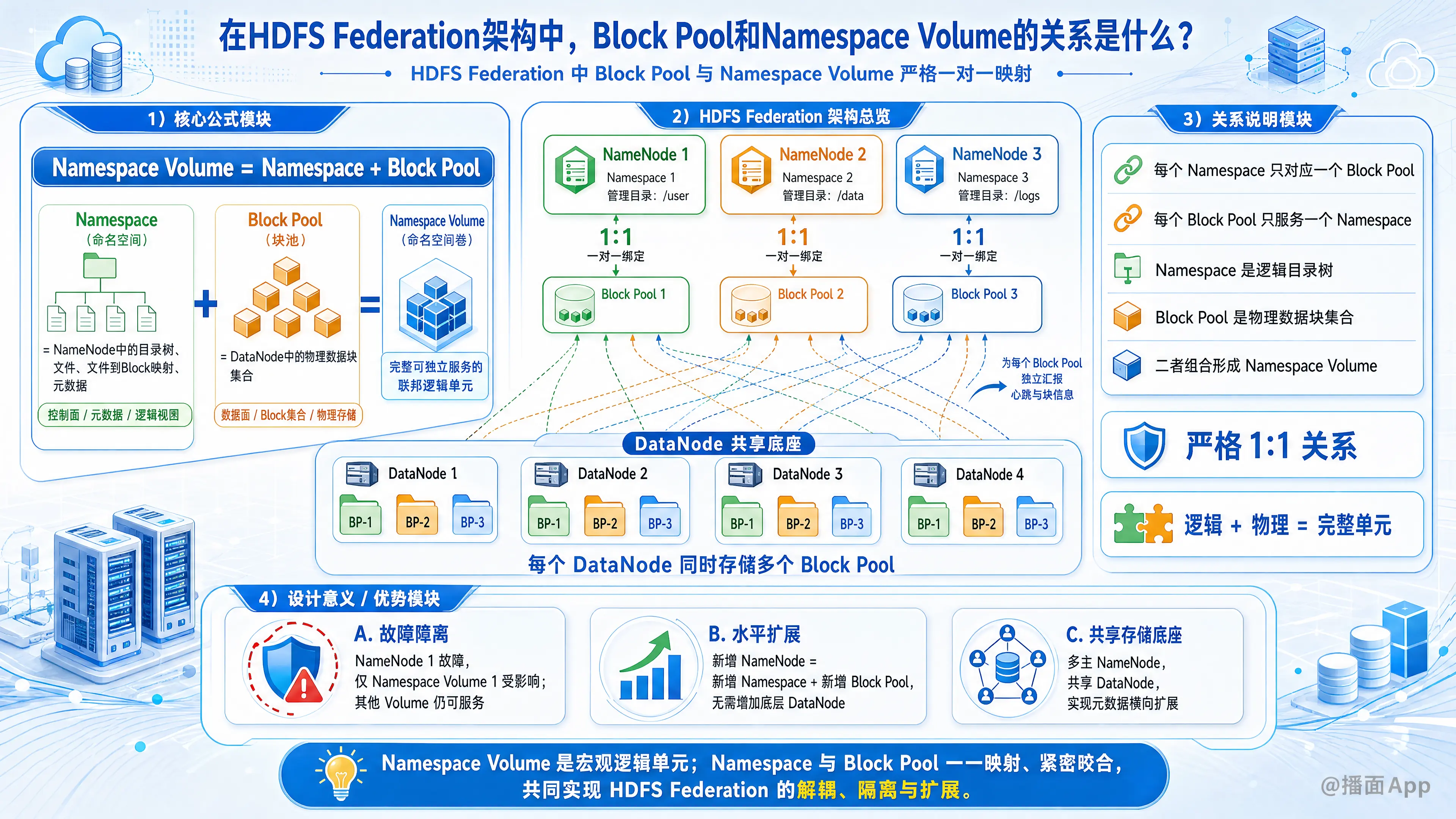
在HDFS Federation(联邦)架构中,Block Pool(块池)和Namespace Volume(命名空间卷)之间是严格的一对一(1:1)关系。
为了让你更清晰地理解它们的关系,我们需要从概念拆解、架构组成以及它们如何协同工作三个方面来详细说明。
1. 核心公式:什么是 Namespace Volume?
在HDFS联邦中,有一个非常直观的等式:
Namespace Volume = Namespace(命名空间) + Block Pool(块池)
- Namespace(命名空间): 存在于 NameNode(控制面) 中。它包含了目录树、文件以及文件到Block的映射关系(即元数据)。
- Block Pool(块池): 存在于 DataNode(数据面) 中。它是属于特定Namespace的所有物理数据块(Block)的集合。
2. 它们之间的具体关系
- 一对一绑定: 每一个独立的 Namespace(由一个独立的 NameNode 管理)必然对应且只对应一个 Block Pool。反之亦然。
- 逻辑与物理的统一: Namespace 是逻辑上的目录树(存在内存里),而 Block Pool 是这棵目录树下所有文件对应的实际物理数据(存在磁盘上)。它们结合在一起,就构成了一个完整的、可以独立提供读写服务的逻辑单元,这个单元就被称为 Namespace Volume。
3. 在集群中的实际表现(架构图景)
在传统的HDFS中,整个集群只有一个NameNode,对应一个Namespace和一个Block Pool。
但在Federation架构中,底层的DataNode是共享的,而上层的NameNode是多主的。
假设你的联邦集群有3个NameNode(分别管理 /user, /data, /logs 三个目录):
- NameNode 1 维护 Namespace 1,对应底层的 Block Pool 1。
- NameNode 2 维护 Namespace 2,对应底层的 Block Pool 2。
- NameNode 3 维护 Namespace 3,对应底层的 Block Pool 3。
关键点:
所有的 DataNode 都会同时存储 Block Pool 1、2、3 的数据块。在 DataNode 的物理磁盘上,你会看到不同 Block Pool ID 对应的不同文件夹。DataNode 会为每一个 Block Pool 启动一个独立的线程,向对应的 NameNode 汇报心跳和块信息。
4. 这种分离设计的意义是什么?
HDFS Federation之所以创造出“Block Pool”和“Namespace Volume”的概念,是为了解耦:
- 故障隔离(独立性): 因为每个 Namespace Volume 是相互独立的。如果 NameNode 1 宕机了,Namespace 1 和 Block Pool 1 就不可用了;但是,NameNode 2 和 3 以及它们对应的 Block Pool 2 和 3 完全不受影响,DataNode 依然可以为它们提供服务。
- 水平扩展: 当元数据过多,一个NameNode撑不住时,可以增加一个新的NameNode(创建一个新的Namespace),底层的DataNode不需要增加,只需在现有的DataNode上划出一个新的Block Pool即可,这就无缝增加了一个 Namespace Volume。
总结
Namespace Volume 是一个宏观的逻辑概念,代表一个完整的联邦子系统;而 Namespace(元数据)和 Block Pool(实体数据)是组成它的两个半壁江山。它们紧密咬合,一对一映射,共同实现了HDFS在不增加物理机器的情况下扩展NameNode处理能力的壮举。