 播面
播面 什么是HDFS的快照(Snapshot)功能?它的底层实现原理是什么?
HDFS的快照(Snapshot)功能是Hadoop分布式文件系统中一个非常重要的企业级特性。下面为您详细解析它的定义、特点以及底层的实现原理。
一、 什么是HDFS的快照(Snapshot)?
HDFS快照是文件系统目录在某一特定时刻的只读镜像。你可以把它理解为给HDFS中的某个目录拍了一张“照片”,记录下了那一瞬间该目录下所有文件和子目录的状态。
核心特点:
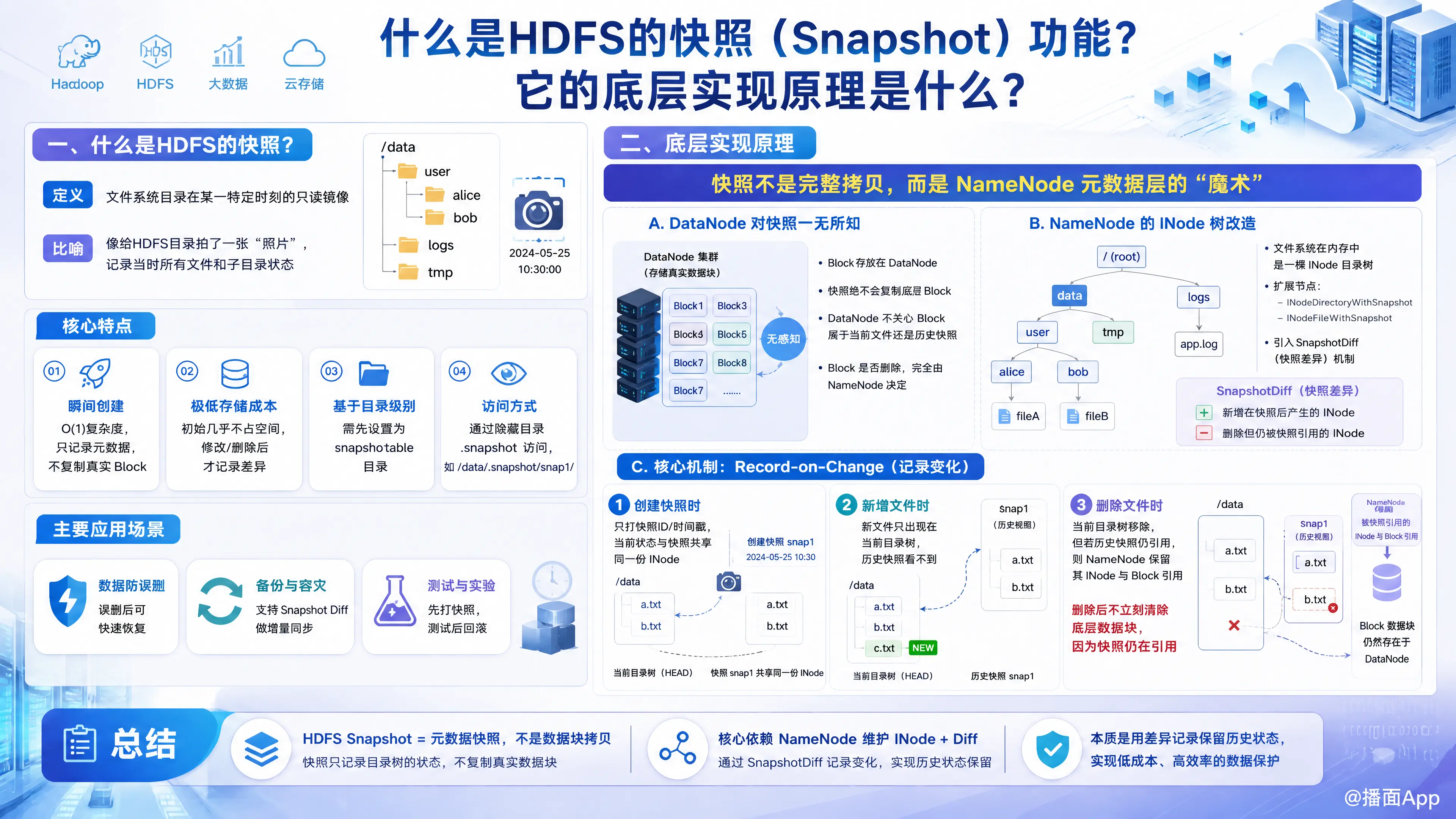
- 瞬间创建(O(1)复杂度):创建快照的操作是瞬间完成的,因为它不需要复制任何真实的数据块(Block),只涉及元数据(Metadata)的记录。
- 极低的存储成本:刚创建时几乎不占用额外的存储空间。只有当原目录的数据发生修改或删除时,才会占用额外的空间来记录这些差异(类似“写时复制” Copy-On-Write 机制)。
- 基于目录级别:快照可以作用于整个文件系统,也可以作用于特定的目录(需要先将该目录设置为“可快照目录” snapshottable)。
- 访问方式隐蔽:用户可以通过被快照目录下的隐藏目录
.snapshot来访问快照数据。例如,访问/data目录的快照snap1:/data/.snapshot/snap1/。
主要应用场景:
- 数据防误删:用户的最高频需求。如果误删了文件,可以从快照中瞬间恢复。
- 数据备份与容灾:作为增量备份的基础,可以对比两个快照的差异(Snapshot Diff),只同步变化的数据。
- 测试与实验环境:在真实数据上进行破坏性测试前打个快照,测试完后可随时回滚。
二、 底层实现原理
很多初学者认为快照是把数据完整的拷贝了一份,这在HDFS中是完全错误的。
HDFS快照的核心实现原理可以总结为两句话:快照纯粹是NameNode内存中元数据(Metadata)的魔术,DataNode(底层数据块)对此毫无感知;它通过记录目录树的差异(Diff)来实现状态的保留。
具体原理解析如下:
1. DataNode 对快照“一无所知”
在HDFS中,文件是由Block组成的,存放在DataNode上。快照绝对不会去复制DataNode上的Block。
DataNode只负责保存Block。至于这个Block属于当前文件,还是属于某个历史快照,DataNode根本不知道。保留或删除Block的指令完全由NameNode下发。
2. NameNode 的 INode 树改造
在NameNode的内存中,整个文件系统是一棵目录树,树的节点叫 INode(包括目录 INodeDirectory 和文件 INodeFile)。
为了支持快照,HDFS对 INode 进行了扩展:
- 引入了带有快照特性的节点类,如
INodeDirectoryWithSnapshot和INodeFileWithSnapshot。 - 引入了 SnapshotDiff(快照差异) 机制。每个开启了快照的目录或文件,都会维护一个 Diff 列表。
3. 核心机制:修改记录(Record-on-Change)
HDFS快照并不像传统文件系统那样采用严格的“写时复制(Copy-On-Write)”,因为HDFS文件本身是不可修改(只能追加和删除)的。HDFS采用的是记录差异的方式:
创建快照时:
NameNode仅仅是给当前的目录树状态打上一个时间戳和快照ID。没有任何数据或元数据的复制。此时,当前状态和快照状态指向同一个INode。当发生【新增文件】时:
新文件被加入到当前的目录树中。历史快照的 Diff 列表中不包含这个新文件,因此通过.snapshot访问时看不到新文件。当发生【删除文件】时(最核心场景):
假设在/data下删除了file_A。file_A会从当前文件系统的目录树中被移除。- 但是,NameNode 发现
file_A还被历史快照snap1引用。 - 于是,NameNode 会把
file_A的元数据信息存入snap1的 SnapshotDiff(差异列表)的deleted集合 中。 - 关键点: 因为快照依然持有
file_A的元数据引用,NameNode 不会向 DataNode 发送删除真实 Block 的指令。数据依然安全地躺在磁盘上。
当发生【追加文件】时(Append):
HDFS会记录文件长度的变化。快照中记录的是追加前的文件长度。当通过快照读取该文件时,NameNode只允许客户端读取到原来长度对应的Block数据,后面追加的Block对该快照不可见。
4. 快照的读取路由(路径解析)
当用户输入路径 hdfs dfs -cat /data/.snapshot/snap1/file_A 时:
- NameNode 解析路径,发现包含魔法关键字
.snapshot。 - NameNode 找到
/data目录对应的 INode,并找到snap1对应的快照ID。 - NameNode 结合
/data的当前目录树状态,逆向应用(从当前状态倒推)保存在 SnapshotDiff 中的差异记录(比如把被删除的file_A重新拼接到视图中)。 - 最终在内存中“动态计算”出
snap1时刻的目录结构视图,并返回给客户端。
5. 真实数据的销毁时刻
只有当以下两个条件同时满足时,NameNode才会真正通知DataNode去删除底层的Block数据:
- 文件在当前文件系统中被删除了。
- 且 所有包含该文件的历史快照也都被删除了。
总结
HDFS快照是一种极其轻量级的元数据操作。它利用了HDFS文件不可就地修改(只读/追加)的特性,通过在NameNode内存中维护当前目录树 + 快照变更差异日志(SnapshotDiff)的方式,实现了瞬间创建、极低开销的历史状态保留,是保障大数据集群数据安全的一道关键防线。