 播面
播面 HDFS HA是如何防止脑裂的?
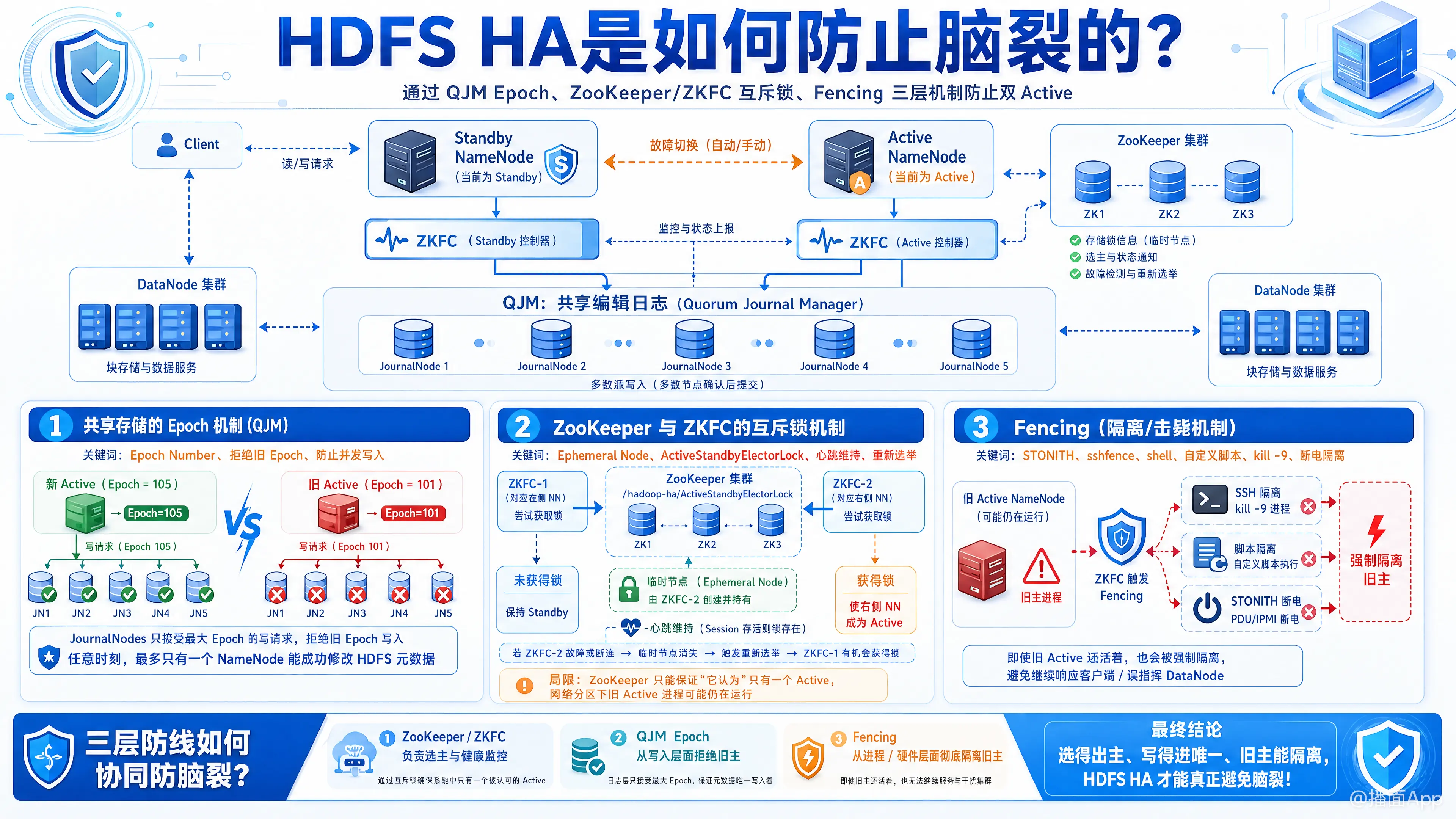
在HDFS HA(高可用)架构中,“脑裂”(Split-Brain)是指由于网络分区或其他故障,导致集群中同时出现了两个Active NameNode。如果这两个NameNode同时对共享存储(如JournalNodes)进行写操作,或者同时响应客户端请求,就会导致元数据损坏和集群崩溃。
为了彻底防止脑裂,HDFS HA 设计了多层防御机制,主要通过以下三个核心手段来实现:
1. 共享存储的 Epoch 机制(Quorum Journal Manager, QJM)
这是防止脑裂最底层、最核心的数据保护机制。HDFS HA 通常使用一组 JournalNodes(JN)来同步 Active 和 Standby NameNode 之间的元数据。
- Epoch Number(纪元编号): 每次 NameNode 发生状态切换(Standby -> Active)时,都会生成一个新的、递增的 Epoch Number。
- 拒绝旧 Epoch: 当新的 Active NameNode 产生后,它会带着新的 Epoch 去连接 JournalNodes。JournalNodes 内部有一个严格的规则:只接受携带当前最大 Epoch 编号的 NameNode 的写请求。
- 防止并发写入: 如果旧的 Active NameNode(假死后复活,或者因为网络延迟不知道自己已经被降级)尝试向 JN 写入数据,由于它携带的 Epoch 是旧的,JN 会直接拒绝它的写入请求。
- 结论: 这一机制从根本上保证了在任何时刻,最多只能有一个 NameNode 能够成功修改 HDFS 的元数据。
2. ZooKeeper 与 ZKFC 的互斥锁机制
HDFS HA 依赖 ZooKeeper 和 ZKFC(ZooKeeper Failover Controller)来进行主备选举和健康监控。
- 排他锁(Ephemeral Node): 两个 NameNode 的 ZKFC 启动时,都会尝试在 ZooKeeper 中创建一个临时节点(ActiveStandbyElectorLock)。ZooKeeper 保证只有一个 ZKFC 能创建成功,成功的那个 NameNode 就成为 Active,失败的成为 Standby。
- 心跳维持: Active 状态的维持依赖于 ZKFC 与 ZooKeeper 之间的心跳。如果 Active NameNode 发生故障或网络断开,ZooKeeper 上的临时节点会自动消失,触发重新选举。
- 局限性: ZooKeeper 只能保证它自己“认为”只有一个 Active,但如果发生网络分区(Active NN 和 ZK 断网,但和客户端、DataNode 没断网),旧的 Active NN 进程依然在运行。这就需要第三步机制。
3. Fencing(隔离/击毙机制)
虽然 QJM 的 Epoch 机制防止了旧的 Active 修改元数据,但旧的 Active 仍然可能接收客户端的读请求,或者向 DataNode 发送错误的指令,造成数据不一致。因此,HDFS 引入了 Fencing 机制,俗称“爆头”(STONITH - Shoot The Other Node In The Head)。
在 Standby NameNode 正式接管成为 Active 之前,ZKFC 会触发 Fencing 操作,强行将旧的 Active NameNode 隔离或杀死。HDFS 提供了几种 Fencing 方法:
- sshfence(最常用): 新的 Active 节点通过 SSH 无密码登录到旧的 Active 节点机器上,执行
fuser命令找到 NameNode 进程,并直接kill -9杀掉它。 - shell(自定义脚本): 可以配置执行自定义的 Shell 脚本来进行隔离。例如,在极高要求的生产环境中,脚本可以调用智能电源分配器(PDU)的接口,直接切断旧 Active 节点服务器的电源(硬件级别的隔离),或者通过交换机禁用旧节点的网络端口。
Fencing 的强制性: 如果配置了 Fencing,Standby NameNode 在尝试变成 Active 之前,必须确保 Fencing 操作执行成功。如果 Fencing 失败,Standby 节点将拒绝切换为 Active 状态,宁可集群不可用,也不能容忍脑裂的发生。
总结:HDFS HA 防脑裂的完整流程
当原 Active 节点发生假死(如 GC 停顿或网络抖动)时:
- ZooKeeper 层面: ZK 认为原 Active 已死,释放锁,Standby ZKFC 抢到锁,准备切换为 Active。
- Fencing 层面(确保旧进程死亡): Standby ZKFC 通过 SSH (
sshfence) 登录到旧节点,直接kill掉旧的 NameNode 进程。 - QJM 层面(确保数据绝对安全): 即使 Fencing 因为某种奇葩原因没杀死旧进程,新的 Active NameNode 会向 JournalNodes 申请更高的 Epoch。旧的 NameNode 即使还活着,它发出的写请求也会被 JournalNodes 无情拒绝。
通过 选举互斥 + 进程级暴力隔离(Fencing) + 存储级 Epoch 拦截 这三重保险,HDFS HA 完美地防止了脑裂的发生。