 播面
播面 JournalNode在HA架构中起什么作用?
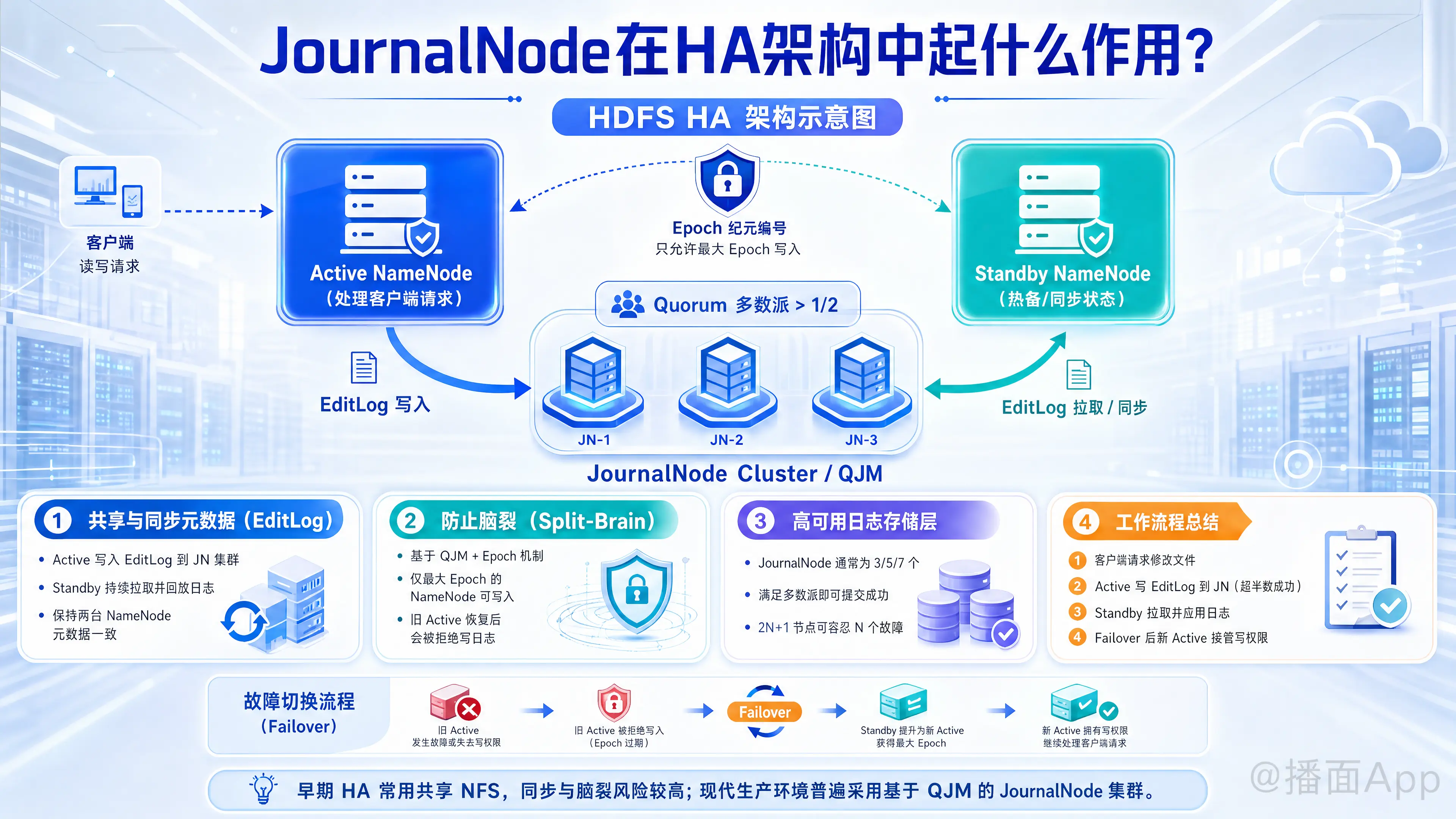
在Hadoop HDFS的HA(High Availability,高可用)架构中,JournalNode(简称JN)的核心作用是实现 Active NameNode 和 Standby NameNode 之间的元数据(EditLog)同步,并依靠多数派机制防止“脑裂”(Split-Brain)现象。
具体来说,JournalNode 扮演了以下几个至关重要的角色:
1. 共享与同步元数据 (EditLog)
在 HA 架构中,存在两个 NameNode:一个是 Active(活跃)状态,负责处理客户端的所有读写请求;另一个是 Standby(备用)状态,作为热备随时准备接管。
- 写入: 当 Active NameNode 处理客户端请求(如创建文件、删除文件)时,它会将这些修改记录(EditLog)写入到 JournalNode 集群中。
- 读取: Standby NameNode 会一直监听 JournalNode,一旦发现有新的 EditLog 写入,就会立即将其拉取过来,并应用到自己内存中的文件系统目录树中。
结果: 通过这种方式,Standby NameNode 的内存状态与 Active NameNode 保持完全一致,从而为秒级的主备切换(Failover)提供数据基础。
2. 防止“脑裂”(Split-Brain)
“脑裂”是指在一个 HA 集群中,由于网络分区或通信故障,导致两个 NameNode 都认为自己是 Active 状态,并同时尝试对外提供服务和写入数据,这会导致极度严重的数据损坏。JournalNode 是防止脑裂的最后一道防线(Fencing 机制的一部分):
- Epoch Number(纪元编号): JournalNode 使用一种称为 QJM (Quorum Journal Manager) 的机制。每次 NameNode 成为 Active 时,都会生成一个唯一的、递增的 Epoch 编号。
- 排他性写入: JournalNode 只允许携带最大 Epoch 编号的 NameNode 写入数据。
- 拦截“假死”节点: 如果原来的 Active NameNode 因为网络卡顿被判定死亡(此时 Standby 已经晋升为新的 Active 并生成了更大的 Epoch),当原来的 Active 恢复并尝试继续写入 EditLog 时,JournalNode 会发现它的 Epoch 编号太小,从而直接拒绝它的写入请求。这样就完美避免了两个 NameNode 同时修改元数据。
3. 提供高可用的日志存储层
JournalNode 本身也是一个集群,通常由奇数个节点组成(如 3、5、7 个)。它基于“多数派”(Quorum)原则工作:
- Active NameNode 只要成功将 EditLog 写入到半数以上的 JournalNode 节点(例如 3 个节点中写成功 2 个),就认为这次写入是成功的。
- 容错性: 对于 个节点的 JournalNode 集群,可以容忍 个节点同时宕机而不影响整个 HDFS 的运行。(例如,3 个 JN 可以容忍 1 台宕机;5 个 JN 可以容忍 2 台宕机)。
总结工作流程:
- 客户端请求修改文件。
- Active NameNode 将修改操作(EditLog)推送到 JournalNode 集群(必须超半数写入成功)。
- Standby NameNode 从 JournalNode 集群 拉取最新的 EditLog 并执行操作,保持状态同步。
- 如果发生故障切换,新的 Active NameNode 凭借更高的 Epoch 获得 JournalNode 的写入权限,旧的 NameNode 将被剥夺写入权限。
注:在早期的 Hadoop 版本中,HA 的数据同步是通过共享的 NFS(网络文件系统)来实现的,但 NFS 容易出现单点故障和脑裂问题,因此目前生产环境中几乎全部采用基于 QJM 机制的 JournalNode 集群。