 播面
播面 讲讲Secondary NameNode的Checkpoint(检查点)工作机制和流程
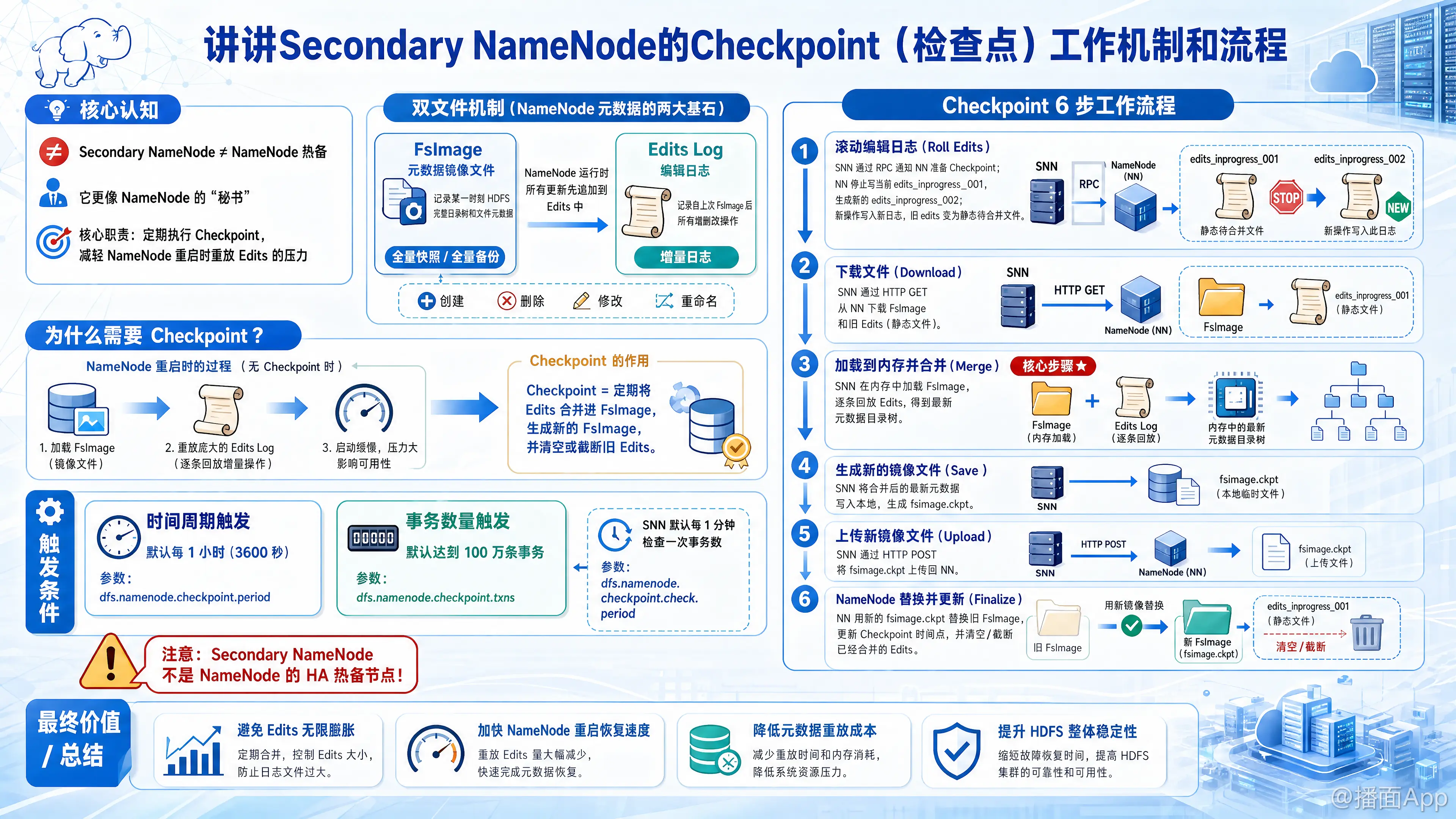
在Hadoop HDFS中,Secondary NameNode(简称SNN) 的核心职责并不是作为 NameNode 的热备(High Availability 备份),而是作为 NameNode 的“秘书”,专门负责执行 Checkpoint(检查点) 操作。
要理解 Checkpoint 机制,首先需要明白两个核心文件:
- FsImage(元数据镜像文件):记录了某一时刻HDFS完整的目录树和文件元数据(相当于“全量备份”)。
- Edits Log(编辑日志):记录了自上一次 FsImage 生成以来,客户端对HDFS发起的所有增删改操作(相当于“增量日志”)。
NameNode 在运行时,所有更新操作都会先追加到 Edits 日志中。如果运行时间很长,Edits 文件会无限增大。一旦 NameNode 重启,它需要先加载 FsImage,然后再把庞大的 Edits 日志从头到尾重放一遍,这个过程极其缓慢。
Checkpoint 机制就是为了解决这个问题而诞生的:定期将 Edits 日志合并到 FsImage 中,生成新的 FsImage,从而清空(或截断)旧的 Edits 日志。
以下是 Checkpoint 的详细工作机制和流程:
一、 Checkpoint 的触发条件
Secondary NameNode 会定期询问 NameNode 是否需要执行 Checkpoint。触发条件通常有两个(满足其一即可):
- 时间周期(定时触发):
- 默认每隔 1小时(3600秒)触发一次。
- 配置参数:
dfs.namenode.checkpoint.period
- 事务数量(定量触发):
- 默认当 Edits 日志中的事务(操作)数量达到 100万条 时触发。
- 配置参数:
dfs.namenode.checkpoint.txns - 注:SNN 默认每隔 1分钟(
dfs.namenode.checkpoint.check.period)会向 NN 查验一次事务数是否达标。
二、 Checkpoint 的详细工作流程
当满足上述任一触发条件时,SNN 就会开始执行 Checkpoint,整个过程分为 6 个主要步骤:
1. 滚动编辑日志 (Roll Edits)
- SNN 通过 RPC 请求通知 NameNode 准备 Checkpoint。
- NameNode 收到请求后,会停止向当前的正在写入的日志文件(假设叫
edits_inprogress_001)中写入数据。 - NameNode 会立即生成一个新的日志文件(例如
edits_inprogress_002),以后的新操作记录都会写到这个新文件里。此时,旧的edits_001就变成了一个静态文件,等待被合并。
2. 下载文件 (Download)
- SNN 通过 HTTP GET 请求,从 NameNode 下载当前的 FsImage 文件 以及刚才被封存的 旧 Edits 日志文件。
- (在首次Checkpoint时下载全量,后续可以只下载增量的Edits)
3. 加载到内存并合并 (Merge)
- 这是 SNN 最核心的工作。
- SNN 将下载下来的 FsImage 加载到自己的内存中,构建出目录树结构。
- SNN 接着在内存中逐条回放(Replay)下载下来的 Edits 日志文件中的操作。
- 执行完毕后,SNN 内存中就得到了一份最新状态的元数据目录树。
4. 生成新的镜像文件 (Save)
- SNN 将内存中合并后的最新元数据状态,持久化写入到本地磁盘,生成一个新的镜像文件,通常命名为
fsimage.ckpt(ckpt代表checkpoint)。
5. 上传新镜像文件 (Upload)
- SNN 通过 HTTP POST 请求,将刚刚生成的
fsimage.ckpt文件上传回 NameNode。
6. NameNode 替换并更新 (Finalize)
- NameNode 接收到 SNN 传来的
fsimage.ckpt文件后,会将其重命名为正式的fsimage文件,覆盖掉旧的镜像文件。 - NameNode 更新自己的
fstime(或事务ID记录),标记 Checkpoint 完成。 - 之前被合并的旧 Edits 日志文件就可以被安全清理或归档了。
三、 流程图解(文字版)
[NameNode] [Secondary NameNode]
| |
| 1. SNN 请求执行 Checkpoint |
|<--------------------------------------------------|
| 2. NN 滚动日志 (edits_inprogress -> edits) |
| 并创建新的 edits_inprogress_new |
| |
| 3. SNN 通过 HTTP 下载 fsimage 和 旧 edits |
|-------------------------------------------------->|
| |
| | 4. SNN 在内存中加载 fsimage
| | 并重放 edits
| |
| | 5. 生成新的 fsimage.ckpt
| |
| 6. SNN 通过 HTTP 将 fsimage.ckpt 上传给 NN |
|<--------------------------------------------------|
| |
| 7. NN 将 fsimage.ckpt 重命名为 fsimage |
| 更新检查点状态,旧 edits 废弃。 |四、 Checkpoint 的核心意义
- 加速 NameNode 重启:因为定期合并,Edits 日志不会变得无限大。NameNode 启动时只需加载最新的 FsImage 和少量新的 Edits,启动速度成百上千倍地提升。
- 防止磁盘写满:清理掉已经合并过的 Edits 历史日志,节约 NameNode 的磁盘空间。
- 提供数据恢复的冷备份:虽然 SNN 不能自动顶替 NN 工作(不是HA),但如果 NameNode 磁盘彻底损坏,管理员可以从 SNN 所在的机器上找回最新的
fsimage和已合并的元数据,最大程度减少数据丢失(只能恢复到上一次 Checkpoint 的状态)。
💡 延伸补充:Hadoop 2.x/3.x HA 架构中的 Checkpoint
在现代的 Hadoop 生产环境中,通常会配置 NameNode HA(高可用模式:Active NN + Standby NN)。
在 HA 架构下,Secondary NameNode 会被废弃。Checkpoint 的工作直接由 Standby NameNode 来完成。
Standby NN 会持续从 JournalNodes 中读取 Active NN 产生的 Edits 日志,实时在自己的内存中合并,并定期将生成的 FsImage 上传给 Active NN。这使得 HA 架构下的 Checkpoint 更加高效且实时。