 播面
播面 HDFS DataNode的主要职责是什么?
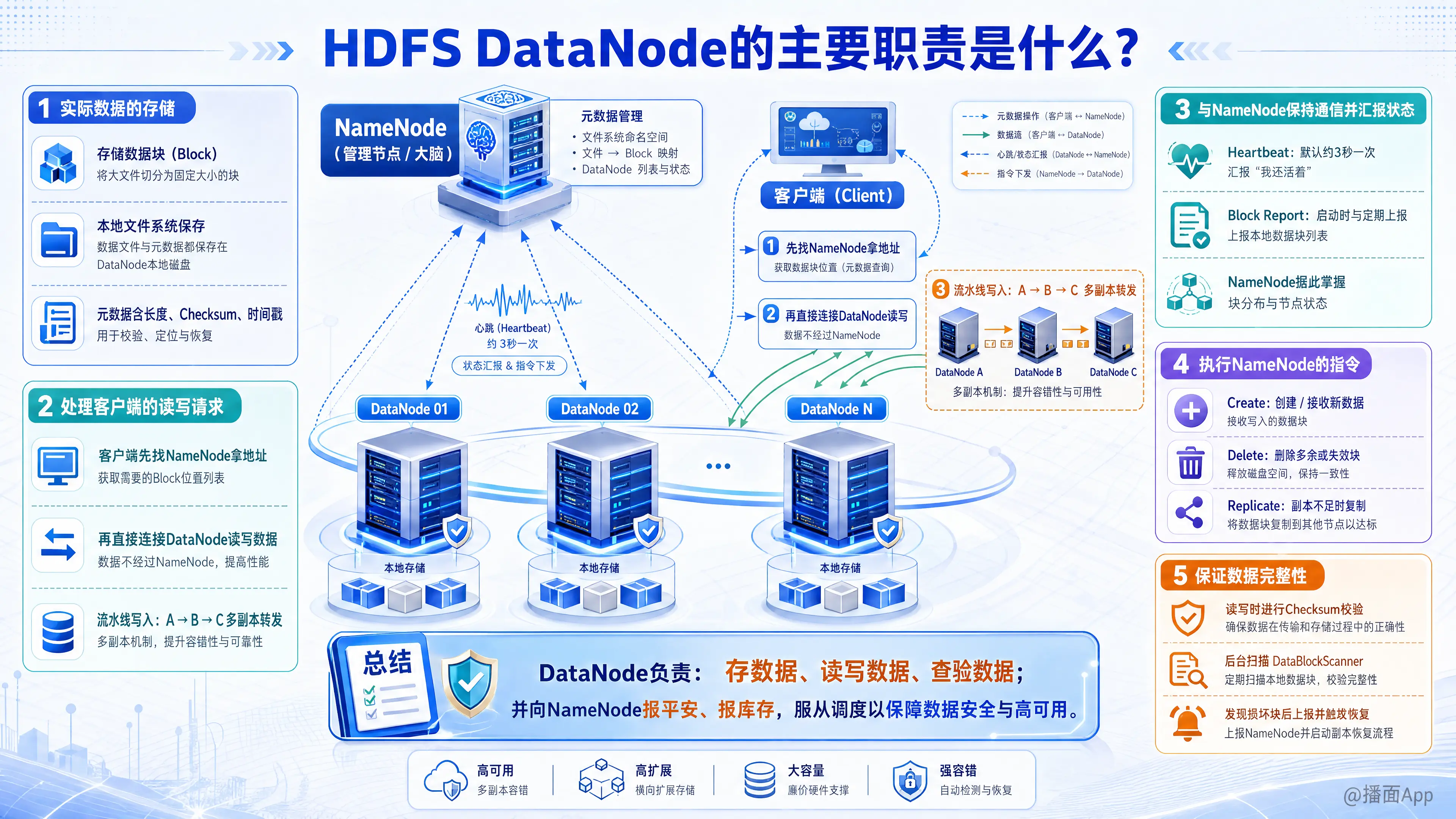
在Hadoop分布式文件系统(HDFS)中,DataNode 是工作节点(Slave/Worker node),而 NameNode 是管理节点(Master node)。如果说 NameNode 是 HDFS 的“大脑”(负责管理目录和元数据),那么 DataNode 就是 HDFS 的“手脚”和“仓库”。
DataNode 的主要职责可以归结为以下几个核心方面:
1. 实际数据的存储(Data Storage)
- 存储数据块(Block): HDFS 会将大文件切割成固定大小的“数据块”(默认通常是 128MB)。DataNode 的最基本职责就是将这些数据块以文件的形式存储在它所在服务器的本地文件系统(如 ext4, xfs)中。
- 存储元数据: 除了实际的数据文件,DataNode 还会为每个数据块存储一个关联的元数据文件,其中包含数据块的长度、校验和(Checksum)以及生成时间戳等信息。
2. 处理客户端的读写请求(Client I/O)
- 直接数据传输: 客户端在读写文件时,会先访问 NameNode 获取数据块所在的 DataNode 地址。拿到地址后,客户端会直接与 DataNode 建立网络连接进行实际的数据读写。NameNode 不参与实际数据的传输,从而减轻了单点压力。
- 流水线写入(Pipeline Write): 在写入数据时,DataNode 负责参与构建数据流管道。例如,客户端将数据写入 DataNode A,DataNode A 会一边接收数据,一边将数据实时转发给 DataNode B,B 再转发给 C,从而完成多副本的快速写入。
3. 与 NameNode 保持通信并汇报状态(Heartbeat & Block Report)
- 心跳机制(Heartbeat): DataNode 默认每隔 3 秒向 NameNode 发送一次心跳信息,告知 NameNode “我还活着”。如果 NameNode 长时间(默认约10分钟)没有收到某个 DataNode 的心跳,就会认为该节点已宕机,并将其上的数据块重新复制到其他存活的节点上。
- 数据块汇报(Block Report): DataNode 在启动时,以及运行期间定期(默认每6小时)会向 NameNode 发送“块报告”,列出自己本地磁盘上存储的所有有效数据块列表。这让 NameNode 能够实时掌握全集群数据块的分布情况。
4. 执行 NameNode 的指令(Block Management)
DataNode 完全听从 NameNode 的调度,执行对底层数据块的管理操作,包括:
- 创建(Create): 接收客户端或集群的新数据。
- 删除(Delete): 当用户删除文件或某数据块副本过多时,NameNode 会下达删除指令,DataNode 负责在本地磁盘上物理删除这些数据块。
- 复制(Replicate): 当集群中某个节点宕机导致某数据块的副本数不足时,NameNode 会命令拥有该数据块的 DataNode 将其复制到其他机器上。
5. 保证数据完整性(Data Integrity)
- 校验和计算(Checksum): DataNode 在接收客户端或其它 DataNode 传来的数据时,会验证数据的校验和;在客户端读取数据时,也会重新计算并验证,确保数据在网络传输或磁盘存储过程中没有发生损坏。
- 后台扫描(DataBlockScanner): DataNode 会在后台运行一个扫描线程,定期验证存储在本地的所有数据块的校验和。如果发现数据块损坏(Corrupted),它会向 NameNode 报告,NameNode 会安排从其他健康副本所在的 DataNode 恢复数据。
总结来说:
DataNode 负责存数据、读写数据、查验数据,并时刻向 NameNode 报平安、报库存,完全服从 NameNode 的指挥来维护集群数据的安全与高可用。