 播面
播面 NameNode的主要职责是什么?它的内存中主要存储了哪些元数据信息?
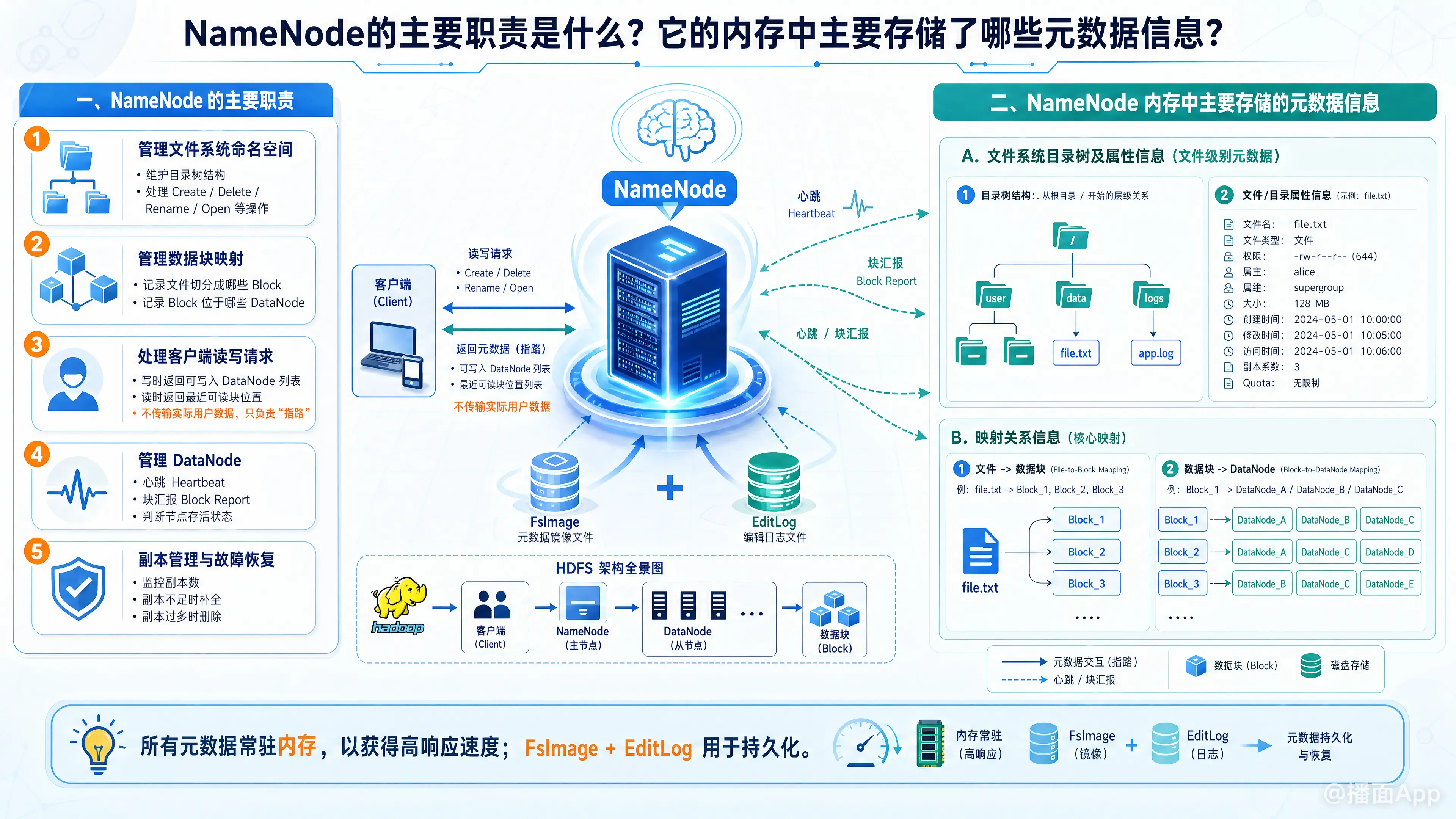
在 Hadoop 分布式文件系统(HDFS)中,NameNode(名称节点)是整个文件系统的“大脑”和管理者(Master)。它的设计核心是协调和管理文件系统中的所有元数据,而将实际的数据读写操作交给 DataNode(数据节点)执行。
以下是关于 NameNode 主要职责及内存中元数据信息的详细解答:
一、 NameNode 的主要职责
NameNode 的职责可以总结为以下五个方面:
- 管理文件系统命名空间(Namespace Management)
- 维护 HDFS 的目录树结构(类似于单机操作系统的文件目录)。
- 处理客户端针对目录和文件的操作请求,如创建(Create)、删除(Delete)、重命名(Rename)、打开(Open)等。
- 管理数据块映射(Block Mapping Management)
- 记录每个大文件被切分成了哪些数据块(Block)。
- 记录每个数据块分配到了哪些具体的 DataNode 上。
- 处理客户端的读写请求(Client Request Handling)
- 写数据时:客户端请求 NameNode,NameNode 根据集群的负载情况和机架感知策略,返回可以存放数据块的 DataNode 列表,之后客户端直接与 DataNode 通信写入数据。
- 读数据时:客户端请求 NameNode 获取指定文件的数据块位置信息(即哪些 DataNode 上有这些块),然后客户端直接去找最近的 DataNode 读取数据。
- (注意:NameNode 自身不处理或传输实际的用户数据,只负责“指路”。)
- 管理 DataNode(DataNode Management)
- 心跳机制(Heartbeat):定期接收所有 DataNode 发送的心跳信号,判断 DataNode 是否存活。如果某个 DataNode 超时未发送心跳,NameNode 会将其标记为宕机(Dead)。
- 块汇报(Block Report):接收 DataNode 汇报的其自身存储的所有数据块信息,以此来动态构建和更新“数据块 -> DataNode”的映射关系。
- 副本管理与故障恢复(Replica Management)
- HDFS 默认会对每个数据块保存多个副本(通常是3个)。NameNode 会持续监控每个数据块的副本数量。
- 如果某个 DataNode 宕机导致某些数据块副本数不足,NameNode 会指挥其他存活的 DataNode 复制该数据块(补全副本)。
- 如果某个 DataNode 恢复或系统扩容导致副本数超过规定值,NameNode 会指挥删除多余的副本。
二、 NameNode 内存中主要存储的元数据信息
为了保证文件系统极高的响应速度,NameNode 将所有的元数据(Metadata)都加载并驻留在物理内存中。这部分内存数据主要包含两大类映射关系及其附属信息:
1. 文件系统目录树及属性信息(文件级别元数据)
这部分记录了文件系统的逻辑结构和属性:
- 目录树结构:从根目录
/开始的所有文件和文件夹的层级关系。 - 文件/目录的属性(Attributes):
- 文件名 / 目录名。
- 权限信息(rwx,谁可读、写、执行)。
- 属主和属组(Owner & Group)。
- 创建时间、最后修改时间和最后访问时间。
- 文件的副本系数(Replication Factor,即该文件的数据块需要存多少份)。
- 磁盘配额(Quota,限制目录下的文件数或存储空间)。
2. 映射关系信息(核心映射)
这是 HDFS 寻址的核心,主要分为两个层面的映射:
- 映射 1:文件 -> 数据块的映射关系(File-to-Block Mapping)
- 记录某个具体文件被划分成了哪些数据块(Block IDs)。
- 例如:
file.txt-> 包含Block_1,Block_2,Block_3。
- 映射 2:数据块 -> DataNode 的映射关系(Block-to-DataNode Mapping / Block Location)
- 记录每个数据块实际存放在集群中的哪几个 DataNode 服务器上。
- 例如:
Block_1-> 存放在DataNode_A,DataNode_B,DataNode_C上。
💡 关键扩展知识点(面试常考):元数据的持久化机制
虽然上述信息都在 NameNode 的内存中,但一旦断电,内存数据就会丢失。因此 NameNode 必须将元数据持久化到本地磁盘。但是,并非所有内存中的元数据都会被保存到磁盘中。
- 持久化的数据(存入
fsimage镜像文件和edits编辑日志中):- 文件系统目录树、文件属性。
- 文件 -> 数据块的映射关系。
- 绝对不持久化到磁盘的数据:
- 数据块 -> DataNode 的物理位置映射关系。
- 原因:集群的节点状态是动态变化的(随时可能有 DataNode 宕机、加入或更换 IP)。如果把物理位置写死在磁盘里,重启后很可能已经失效。
- 如何恢复:NameNode 每次启动时,会先加载
fsimage和edits恢复目录树和文件块信息,然后进入安全模式(Safe Mode),等待各个 DataNode 主动进行“块汇报(Block Report)”。NameNode 根据这些汇报,在内存中动态重建“数据块 -> DataNode”的位置映射表。重建完成后,才会退出安全模式,对外提供服务。