 播面
播面 HDFS中的短路本地读取(Short-Circuit Local Read)是什么?
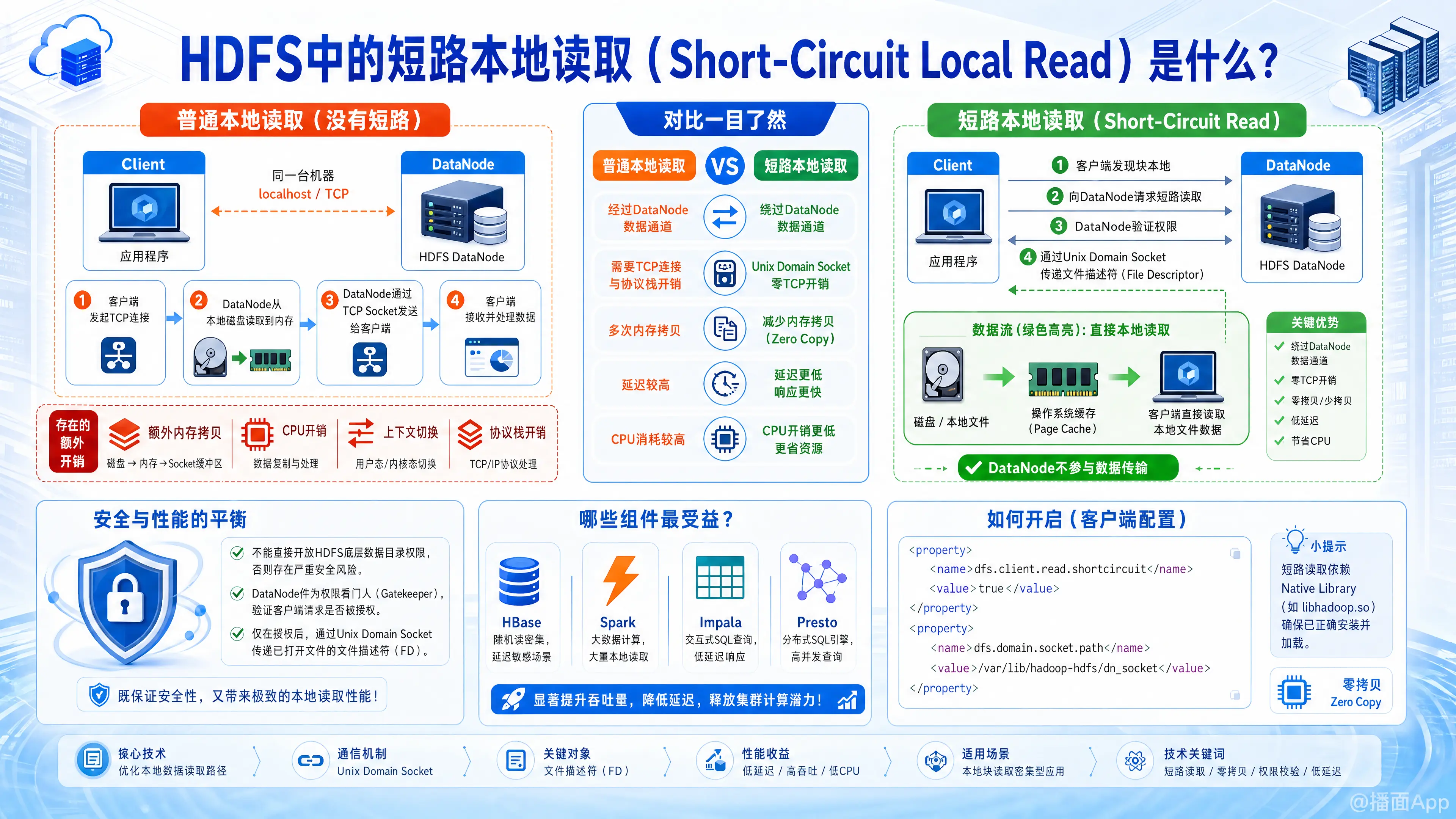
HDFS中的短路本地读取(Short-Circuit Local Read)是Hadoop中的一项重要性能优化技术。
简单来说,当HDFS客户端(Client)和它想要读取的数据块(Block)恰好在同一台物理机器上时,客户端可以直接绕过DataNode进程,直接从本地操作系统的文件系统中读取数据。这就是所谓的“短路”(Short-Circuit)。
为了更好理解,我们可以对比一下“普通读取”和“短路读取”的区别:
1. 普通的本地读取(没有短路)
在默认情况下,即使客户端和数据在同一台机器上,读取流程也是这样的:
- 客户端向DataNode发起TCP连接(通过本地回环地址 localhost)。
- DataNode从本地磁盘读取数据到自己的内存中。
- DataNode通过TCP Socket将数据发送给客户端。
- 客户端接收数据并进行处理。
缺点:
- 额外的内存拷贝: 数据需要先从磁盘拷贝到DataNode进程,再拷贝到Client进程。
- CPU和上下文切换开销: 即使是本地网络,走TCP协议栈也会带来不小的系统调用和上下文切换开销。
2. 短路本地读取(Short-Circuit Read)
开启短路读取后,流程变成了这样:
- 客户端发现自己和数据在同一台机器上,向DataNode请求短路读取。
- DataNode验证客户端的权限。
- 验证通过后,DataNode通过Unix Domain Socket(一种进程间通信机制),直接把该数据块对应在本地文件系统上的文件描述符(File Descriptor)传递给客户端。
- 客户端拿到文件描述符后,直接通过操作系统读取本地磁盘上的文件。
数据流向:磁盘 -> 操作系统缓存 -> 客户端(DataNode完全不参与数据传输)
为什么要这样设计?(安全与性能的平衡)
早期人们想过,既然都在同一台机器上,直接让客户端去HDFS的数据目录里找文件读不就行了?
但这样有严重的安全隐患:你必须给所有客户端开放HDFS底层数据目录的Linux读取权限,这意味着恶意用户可以读取或篡改任意数据。
现代的“短路读取”利用了传递文件描述符的技术。客户端依然没有底层目录的权限,DataNode依然是权限的“看门人”。DataNode确认你有权读这个文件后,才把打开的文件描述符交给你,既保证了安全,又实现了最高效的读取。
带来的好处
- 极大提升读取性能: 零TCP开销,减少了内存拷贝(Zero Copy)。
- 降低延迟: 对于对延迟极其敏感的应用(如HBase)效果显著。
- 节省CPU资源: DataNode不再需要花费大量CPU去处理数据的读取和网络发送。
哪些组件最受益?
凡是采用计算与存储共存(Co-located)架构的组件,都是短路读取的最大受益者:
- HBase: RegionServer通常和DataNode部署在一起,开启短路读能大幅降低查询延迟。
- Impala / Presto: 内存级SQL引擎,对IO速度要求极高。
- Apache Spark: Executor在DataNode节点上执行任务时,直接读取本地数据。
如何开启?
在 hdfs-site.xml 中通常需要如下配置:
xml
<!-- 开启短路本地读取 -->
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<!-- 指定Unix Domain Socket的路径 -->
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>注意:底层依赖Hadoop的本地库(Native Library,如 libhadoop.so),因此必须确保Hadoop本地库已正确安装并被加载。