 播面
播面 HDFS中的校验和(Checksum)是在读还是写的时候发生的?具体是如何工作的?
在 HDFS(Hadoop Distributed File System)中,校验和(Checksum)的计算和验证在读数据和写数据时都会发生。不仅如此,HDFS 还在后台定期进行校验和检查。
HDFS 引入校验和的核心目的是为了保证数据的完整性,防止因网络传输错误、磁盘损坏(Bit Rot / 坏道)等硬件原因导致的数据损坏。
以下是校验和在 HDFS 中具体的工作机制详解:
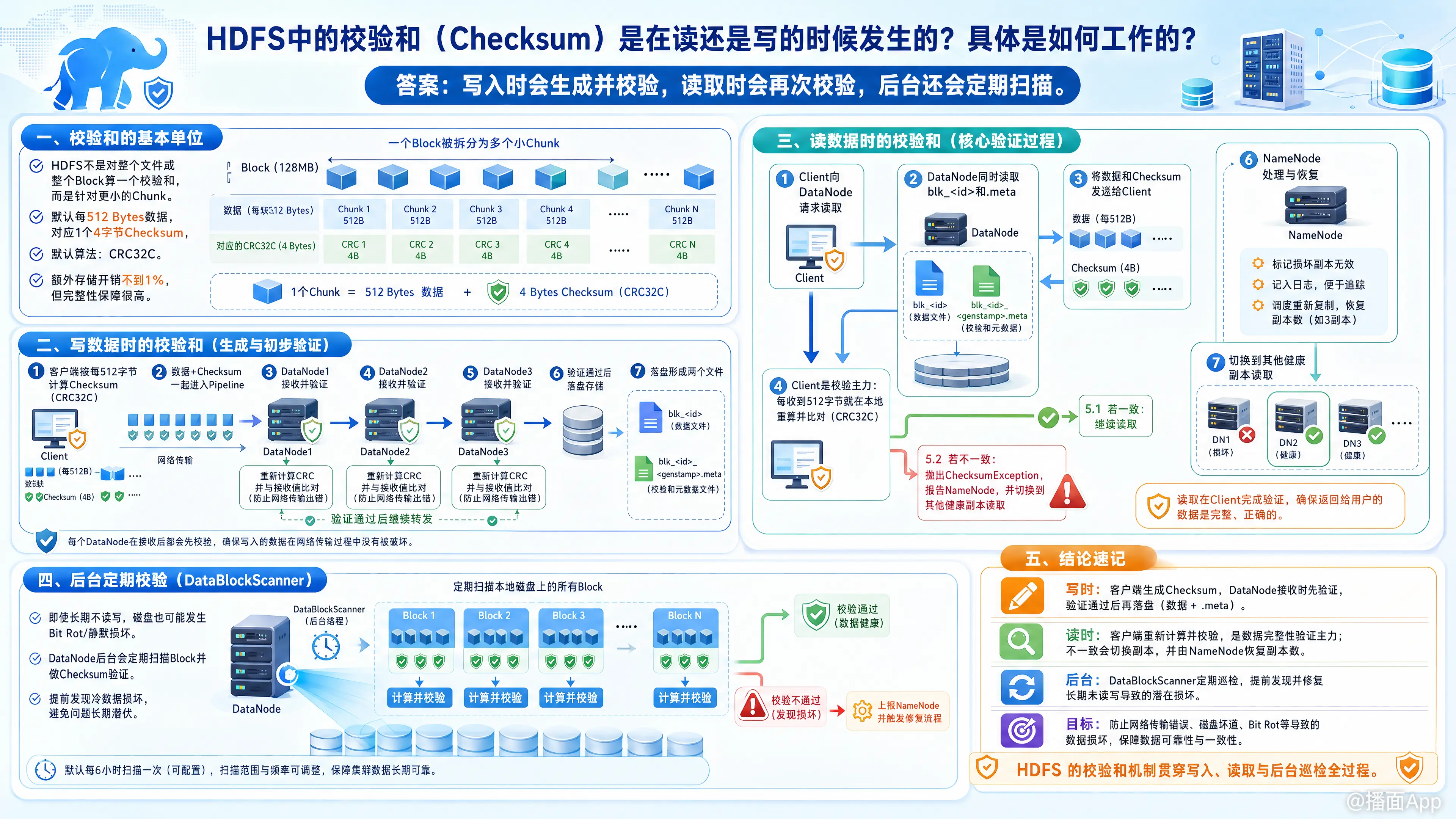
一、 校验和的基本单位
在了解读写流程之前,需要先知道 HDFS 计算校验和的粒度:
- HDFS 并不是针对整个文件或整个 Block(默认 128MB)计算一个校验和,而是针对更小的数据块(称为 Chunk)来计算。
- 默认情况下,每 512 字节(Bytes)的数据计算出一个 4 字节的校验和(默认采用 CRC32C 算法)。
- 这种设计带来的额外存储开销不到 1%,但能提供极高的数据完整性保障。
二、 写数据时的校验和(生成与初步验证)
当客户端(Client)向 HDFS 写入数据时,流程如下:
- 客户端生成校验和:
客户端在将数据发送到 DataNode 之前,会按每 512 字节为一个 Chunk,计算出 4 字节的校验和。 - Pipeline 传输:
客户端将数据和校验和一起,通过 Pipeline(管道)发送给第一个 DataNode,第一个 DataNode 再传给第二个,依此类推。 - DataNode 接收并验证:
DataNode 在接收到数据和校验和后,会先进行一次验证。它会重新计算接收到的数据的校验和,并与客户端传来的校验和进行对比。这一步是为了防止网络传输过程中发生的数据位翻转或损坏。 - 落盘存储(分离存储):
验证通过后,DataNode 会将数据保存到磁盘上。在 Linux 文件系统中,一个 HDFS Block 实际上对应磁盘上的两个文件:blk_<id>:存储实际的数据。blk_<id>_<genstamp>.meta:存储该 Block 的元数据,其中就包含了所有的校验和(Checksum)信息。
三、 读数据时的校验和(核心验证过程)
当客户端从 HDFS 读取数据时,校验和用于确保读出的数据与当年写入的数据完全一致:
- 读取数据与校验和:
客户端向 DataNode 发起读请求。DataNode 会同时从磁盘上读取数据文件(blk_<id>)和校验和文件(.meta),并将它们一起发送给客户端。 - 客户端验证:
客户端是验证校验和的主力。客户端每接收到 512 字节的数据,就会在本地重新计算一次校验和,然后与 DataNode 发来的.meta文件中的校验和进行比对。 - 遇到损坏时的处理机制:
- 如果比对一致,说明数据完好,客户端继续读取。
- 如果比对不一致(抛出
ChecksumException),说明数据已损坏(可能是磁盘坏道导致)。此时客户端会做两件事:- 向 NameNode 汇报:报告这个 DataNode 上的这个 Block 损坏了。
- 自动切换:客户端会向 NameNode 获取该 Block 的其他副本所在的位置,然后去另一个健康的 DataNode 上读取数据,整个过程对上层应用是透明的。
- NameNode 收到损坏报告后,会将该损坏的副本标记为无效,并安排其他健康的 DataNode 重新复制一份该 Block,以恢复设定的副本数(通常是 3),最后删除损坏的副本。
四、 后台定期校验(DataBlockScanner)
除了读写时的校验,HDFS 还有一种防患于未然的机制:
由于磁盘随着时间推移可能会发生“静默损坏”(Bit Rot,即数据没被读写,但磁盘上的磁性介质发生了变化导致数据位翻转),如果某些冷数据长年不被读取,损坏了也发现不了。
- DataNode 后台扫描器:每个 DataNode 后台都运行着一个
DataBlockScanner线程。 - 定期巡检:它会定期(默认周期为 21 天,由
dfs.datanode.scan.period.hours配置)扫描该节点磁盘上的所有 Block。 - 主动修复:它读取数据和
.meta文件进行校验。如果发现损坏,主动通知 NameNode 进行副本的修复和重新调度,确保数据在被客户端读取之前就已经处于健康状态。
总结
- 写数据时:客户端生成校验和,DataNode 验证(防网络错误)并保存到
.meta文件。 - 读数据时:客户端读取并重新计算,与
.meta文件比对,完成验证(防磁盘错误)。 - 后台闲时:DataNode 定期自我巡检(防静默损坏)。