 播面
播面 什么是HDFS的Pipeline(管道)写入机制?
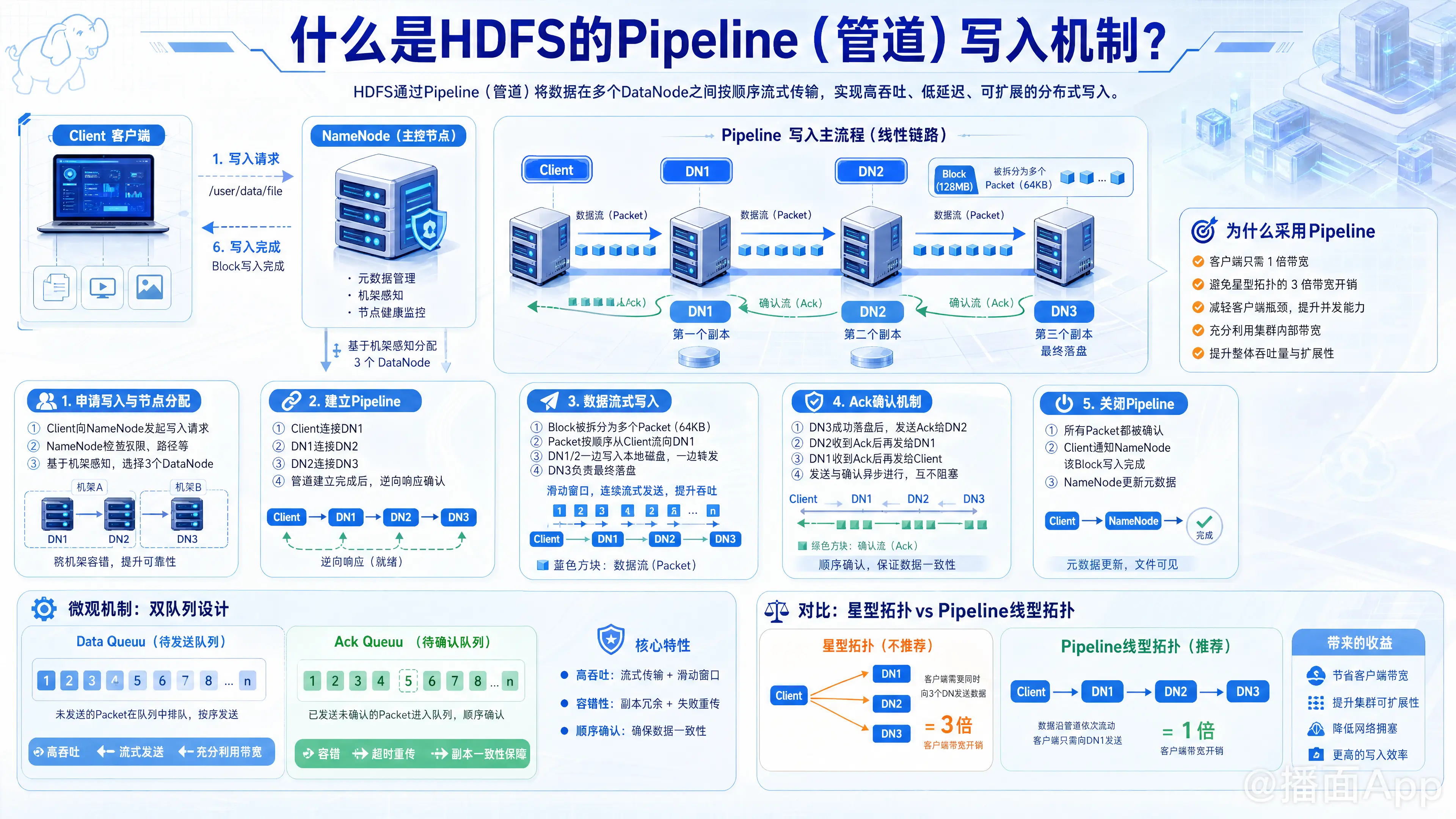
HDFS的Pipeline(管道)写入机制是Hadoop分布式文件系统(HDFS)中用于高效、可靠地将数据写入多个数据节点(DataNode)的核心机制。
简单来说,当客户端需要将一个数据块(Block,默认128MB)写入HDFS并保存多个副本(默认3个)时,客户端不会分别单独向这3个DataNode发送数据,而是将这3个DataNode串联成一条“管道”(Pipeline)。数据像水流一样,从客户端流向第一个节点,第一个节点在本地存储的同时继续流向第二个节点,以此类推。
以下是该机制的详细原理解析:
一、 为什么采用 Pipeline 机制?(设计初衷)
如果客户端直接向3个DataNode分别发送数据(星型拓扑):
- 客户端需要消耗 3倍的网络带宽。
- 客户端会成为严重的网络瓶颈。
采用Pipeline(线型拓扑)后:
- 客户端只需要消耗 1倍的网络带宽 将数据发给第一个DataNode。
- 利用了集群内部节点间的高速网络进行数据传递,大大减轻了客户端的压力,提高了整体吞吐量。
二、 Pipeline 写入的完整流程
假设我们要写入一个Block,副本数为3,流程如下:
1. 申请写入与节点分配
- 客户端向 NameNode 发起写文件请求。
- NameNode 检查权限和目录状态后,根据“机架感知(Rack Awareness)”策略,为该Block分配 3 个 DataNode(假设为 DN1、DN2、DN3),并将这三个节点的列表返回给客户端。
2. 建立 Pipeline 管道
- 客户端与列表中距离最近的 DN1 建立TCP连接。
- DN1 收到连接请求后,主动与 DN2 建立连接。
- DN2 再与 DN3 建立连接。
- 至此,
Client -> DN1 -> DN2 -> DN3的通信管道(Pipeline)正式建立,并逆向返回准备就绪的响应(DN3 -> DN2 -> DN1 -> Client)。
3. 数据流式写入(Packet级别)
- HDFS并非等整个128MB的Block都在内存准备好才发,而是将Block拆分成一个个 Packet(默认64KB)。
- 发送过程:
- 客户端将 Packet 发送给 DN1。
- DN1 收到 Packet 后,一边将其写入本地磁盘,一边同时将其推送到管道的下一个节点 DN2。
- DN2 收到后同样一边落盘,一边推给 DN3。
- DN3 收到后写入本地磁盘(因为是最后一个节点,不需要再往后传)。
4. 接收确认(Ack 机制)
- 当 DN3 成功写入一个 Packet 后,会向 DN2 发送一个确认包(Ack)。
- DN2 收到 DN3 的 Ack,结合自己本地也写入成功,再向 DN1 发送 Ack。
- DN1 收到 DN2 的 Ack,结合自己本地写入成功,最后向客户端发送 Ack。
- 注意:数据的发送和Ack的接收是异步的。客户端不需要等第一个Packet的Ack回来才发第二个Packet,而是源源不断地发送(滑动窗口机制)。
5. 关闭 Pipeline
- 当整个 Block 的所有 Packet 都发送完毕,且客户端收到了所有 Packet 的 Ack 后,客户端向 NameNode 汇报该 Block 写入完成。
- Pipeline 关闭,准备写入下一个 Block。
三、 微观机制:Data Queue 与 Ack Queue
为了保证高吞吐和容错,客户端内部维护了两个队列:
- Data Queue(数据队列):准备发送给 DataNode 的 Packet 会先放入这里,按顺序发送入管道。
- Ack Queue(确认队列):一旦 Packet 发送出去,就会从 Data Queue 移入 Ack Queue。只有当客户端收到管道传回来的 Ack 确认该 Packet 已成功写入所有节点时,才会将该 Packet 从 Ack Queue 中彻底删除。
四、 容错机制:如果 Pipeline 写入中途节点宕机怎么办?
HDFS对Pipeline中的故障有极强的容错能力。假设在写入过程中,DN2 突然宕机,会触发以下恢复流程:
- 管道中断与队列回滚:管道断开,客户端没有收到 Ack。此时,Ack Queue 中那些还没被确认的 Packet 会全部退回到 Data Queue 的头部,确保数据不丢失。
- 剔除坏节点:正在写入的正常节点(DN1、DN3)会向 NameNode 申请一个新的“数据块版本号(Generation Stamp)”,这样 DN2 恢复后,它上面写了一半的旧数据会被识别为过期数据并被删除。
- 重建 Pipeline:将死掉的 DN2 从管线中剔除。剩下的 DN1 和 DN3 重新建立管道(此时副本数暂时降为 2)。
- 恢复写入:客户端继续沿着新的 Pipeline 把剩下的数据写完。
- 异步补齐副本:该 Block 写入完成后,NameNode 会发现它的副本数只有 2 个(不足配置的 3 个)。NameNode 会在后台异步挑选一个新的 DataNode(例如 DN4),将数据复制过去,最终恢复到 3 个副本。
总结
HDFS 的 Pipeline 机制是一个结合了 流式处理(Streaming)、数据块分片(Packet)、异步确认(Ack) 和 动态容错重构 的精妙设计。它不仅解决了大文件分布式写入时的网络带宽瓶颈问题,还保证了在不可靠硬件上存储数据的高可靠性和强一致性。