 播面
播面 HDFS的机架感知(Rack Awareness)
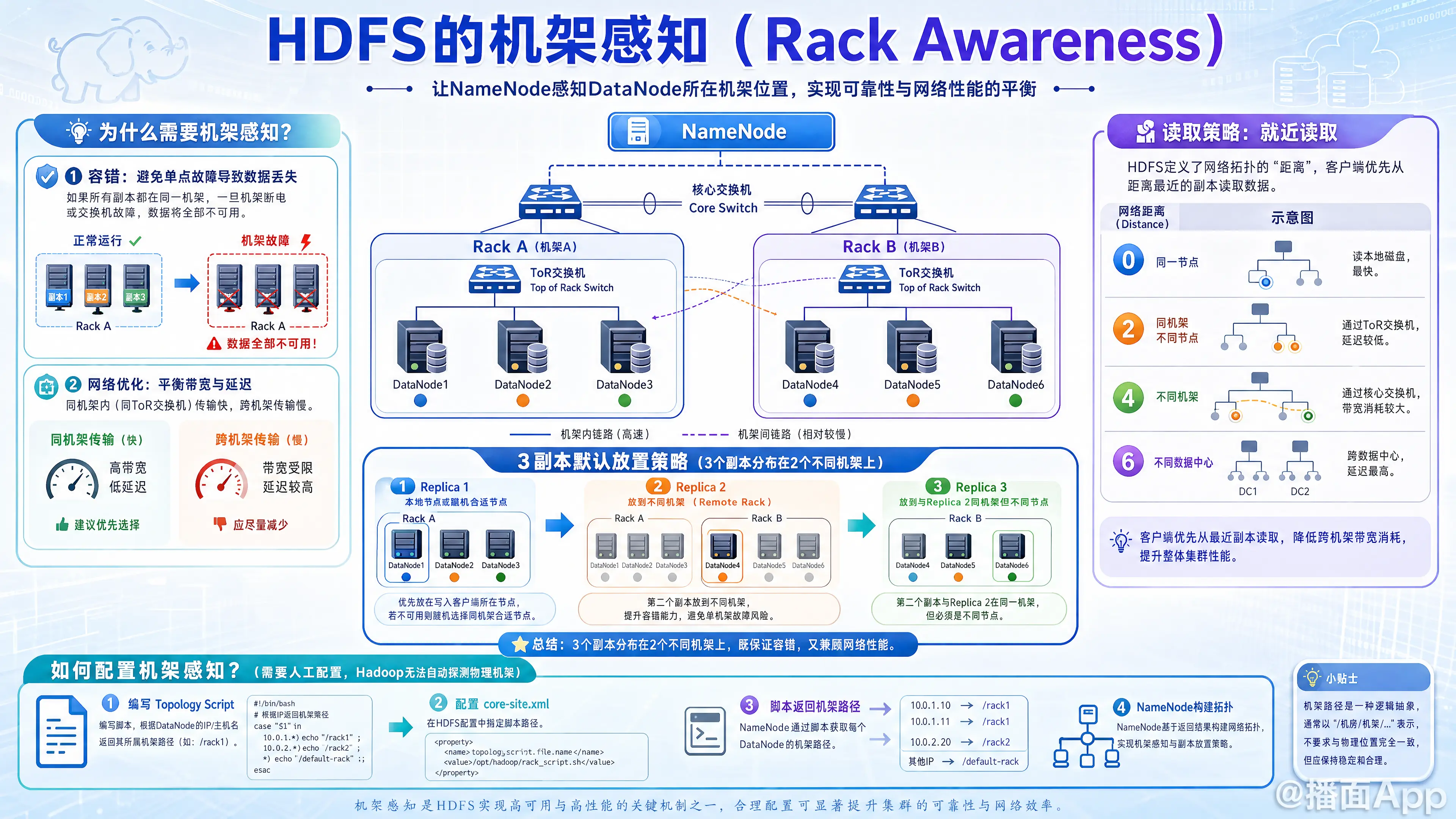
HDFS的机架感知(Rack Awareness)是Hadoop分布式文件系统(HDFS)中一个非常核心的机制。简单来说,它就是让HDFS的NameNode“知道”集群中各个DataNode(数据节点)所处的物理机架(Rack)位置,从而在存放数据副本和读取数据时做出最优的决策。
如果没有机架感知,HDFS会默认所有节点都在同一个机架上(/default-rack)。
1. 为什么需要机架感知?(核心目的)
机架感知的引入主要是为了在数据可靠性(容错)和网络性能(读写效率)之间找到最佳平衡。
- 防范机架/交换机单点故障: 通常一个物理机架上的所有服务器共享一个顶层交换机(Top of Rack switch, ToR)和一个电源。如果机架断电或交换机坏了,整个机架的节点都会失联。如果所有数据副本都在同一个机架上,数据就会暂时或永久丢失。
- 优化网络带宽:
- 同机架内的节点间通信(经过一个交换机)速度快,带宽充足。
- 跨机架的节点间通信(需要经过机架交换机 -> 核心交换机 -> 目标机架交换机)速度相对较慢,且占用宝贵的核心网络带宽。
- 机架感知可以尽量减少跨机架的非必要数据传输。
2. HDFS 的默认副本放置策略(写数据)
以最常见的3个副本(Replication Factor = 3)为例,在开启了机架感知的情况下,HDFS的副本存放策略如下(经典面试题):
- 第一个副本(Replica 1):
- 如果客户端(Client)本身就是一个DataNode,那么第一个副本直接存放在本地节点(节省网络带宽)。
- 如果客户端在集群外部,NameNode会在集群中随机选择一个负载不高、空间充足的节点来存放。
- 第二个副本(Replica 2):
- 存放在与第一个副本不同机架(Remote Rack)的任意一个节点上。
- 目的: 保证当第一个机架发生故障(如断电、交换机损坏)时,数据依然可用(容错)。
- 第三个副本(Replica 3):
- 存放在与第二个副本相同机架,但是不同节点上。
- 目的: 为什么不放在第三个机架?因为跨机架写数据会消耗大量的核心交换机带宽。把第三个副本放在和第二个副本同一个机架,可以通过机架内部的高速交换机快速完成复制,既保证了容错性,又大大提高了写入性能(权衡)。
- 更多副本(如果有):
- 随机放置在集群中,但系统会尽量避免在一个节点上放太多副本,或者在一个机架上放超过
(副本数-1)/2个副本。
- 随机放置在集群中,但系统会尽量避免在一个节点上放太多副本,或者在一个机架上放超过
总结一句话:3个副本会分布在 2个不同的机架上。
3. HDFS 的数据读取策略(读数据)
在读取数据时,机架感知同样发挥着“就近原则”的作用。HDFS会将网络拓扑看作一棵树,并计算客户端到各个数据副本的“距离”。
距离的计算规则(节点间的跳数):
Distance = 0:同一节点(本地读取,最快)。Distance = 2:同一机架下的不同节点(经过1个交换机)。Distance = 4:不同机架下的节点(经过2个机架交换机和1个核心交换机)。Distance = 6:不同数据中心的节点。
读取顺序:
NameNode在响应客户端的读取请求时,会根据上述距离对拥有数据块副本的DataNode进行排序。客户端会优先从距离最近的节点读取数据。如果最近的节点挂了或者太忙,再尝试下一个节点。这极大地节省了跨机架的骨干网络带宽。
4. 如何配置机架感知?
Hadoop本身无法自动探测物理机架的拓扑结构(因为它不知道你是怎么插网线的)。需要系统管理员通过配置脚本来告诉Hadoop。
配置步骤:
编写拓扑脚本(Topology Script):
管理员需要编写一个脚本(可以是 Bash, Python, Java 等)。- 输入: HDFS会向这个脚本传入一个或多个DataNode的 IP 地址或主机名。
- 输出: 脚本需要返回这些节点对应的机架路径(例如
/rack1,/dc1/rack2)。
示例(简单的Python字典映射脚本思路):
如果输入192.168.1.10,脚本查询内部配置,返回/rack1。修改
core-site.xml:
在 Hadoop 的配置文件中指定该脚本的路径。xml<property> <name>net.topology.script.file.name</name> <value>/path/to/your/rack_topology.sh</value> </property>(可选) 还可以配置脚本执行的最大并发数等参数。
重启服务:
重启 NameNode。NameNode 启动后或者新的 DataNode 注册时,会调用这个脚本,在内存中构建出整个集群的网络拓扑树。
总结
HDFS的机架感知是一个极具智慧的设计。它通过“2个机架,3个副本”的经典策略,完美解答了分布式存储中的一个核心矛盾:既要数据绝对安全(跨机架容错),又要写入速度尽可能快(减少跨机架网络传输)。