 播面
播面 为什么建议 InnoDB 表必须建主键,并且推荐使用整型的自增主键?
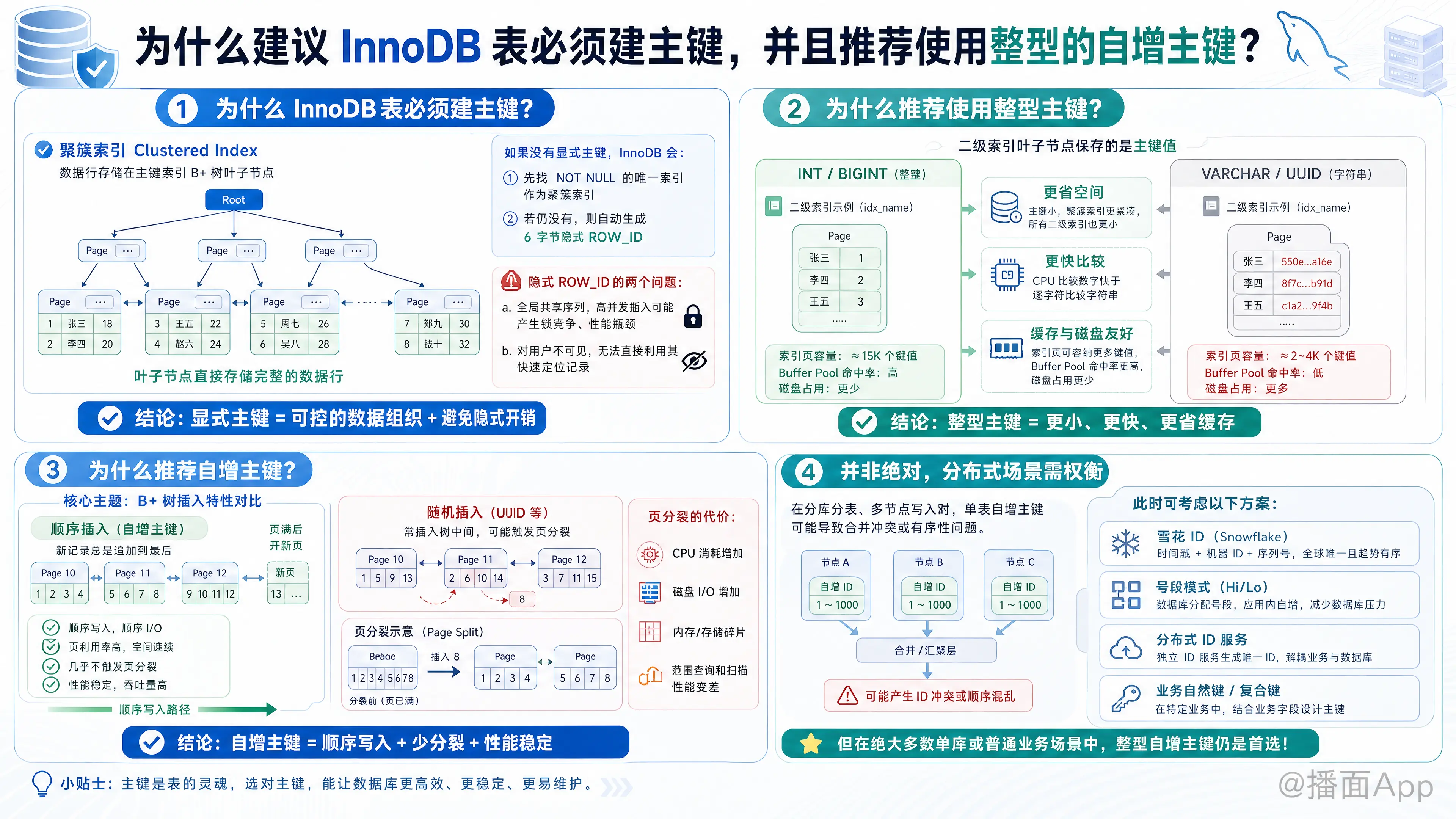
在 MySQL 中,关于 InnoDB 存储引擎表的设计,“必须建主键”和“推荐使用整型自增主键”是两条极其重要的底层优化原则。
这两个建议都与 InnoDB 的底层存储结构——B+树(B+ Tree)息息相关。以下是详细的原因剖析:
一、 为什么建议 InnoDB 表“必须”建主键?
这与 InnoDB 的数据组织方式有关。InnoDB 使用的是聚簇索引(Clustered Index),这意味着数据行本身是存储在主键索引的 B+树的叶子节点上的。
- 确定数据的物理存储位置:
因为数据必须依附于某棵 B+ 树存在,所以 InnoDB 必须有一个聚簇索引来组织数据。 - 如果没有显式定义主键会发生什么?
- InnoDB 会首先去寻找一个所有的列都为
NOT NULL的唯一索引(Unique Index)来作为聚簇索引。 - 如果连符合条件的唯一索引都没有,InnoDB 会自动在底层生成一个隐式的、长 6 字节的行 ID(ROW_ID)来构建聚簇索引。
- InnoDB 会首先去寻找一个所有的列都为
- 为什么不依赖隐式的 ROW_ID?
- 性能瓶颈:这个隐式的
ROW_ID是全局共享的(所有没有主键的表共享同一个序列)。在高并发插入时,这个全局计数器会成为性能瓶颈(引发锁竞争)。 - 不可见性:这个字段对用户是透明的,你无法直接通过它来查询数据,失去了主键本身用于快速定位记录的意义。
- 性能瓶颈:这个隐式的
结论:显式指定主键,可以自己把控数据的物理组织形式,避免 MySQL 底层产生不必要的性能开销。
二、 为什么推荐使用“整型”?
主键的数据类型直接影响存储空间和查询性能。对比字符串(如 UUID、身份证号等),整型(INT / BIGINT)有以下巨大优势:
- 节省存储空间(不仅是主键索引,还包括二级索引)
- InnoDB 的二级索引(辅助索引)的叶子节点中存储的是主键的值。
- 如果使用
INT(4字节)或BIGINT(8字节),主键非常小。 - 如果使用
VARCHAR(36)存 UUID,那么不仅聚簇索引变大,表上的每一个二级索引都会因为存放了体积庞大的主键而急剧膨胀。这会导致磁盘占用大,且内存(Buffer Pool)能缓存的索引页变少,降低命中率。
- 比较速度更快
- B+树在查找时,需要进行大量的值比较。CPU 在处理整型数字的比较时,速度远远快于字符串(字符串需要逐字符对比,还涉及字符集排序规则)。
三、 为什么推荐使用“自增(Auto-Increment)”?
这是由 B+树的插入特性决定的。
- 顺序插入 vs 随机插入
- 自增主键(顺序插入):每次插入的新记录,主键值总是比上一条大。在 B+树中,新数据会被顺序地追加在当前节点的最后面。当一个数据页(Page,默认16KB)写满时,直接开辟一个新的页继续写。这种写盘方式是顺序 I/O,速度极快,且数据页的利用率极高。
- 非自增主键(如 UUID,随机插入):由于主键是随机生成的,新数据大概率需要插入到 B+树中间的某个节点。
- 避免“页分裂(Page Split)”和“内存碎片”
- 接着上面的随机插入说,如果目标数据页已经满了,但此时因为主键排序规则,必须把新数据插到这个页中间,InnoDB 就被迫将该页分裂成两个页,把部分数据移动到新页中。
- 页分裂是非常昂贵的操作,不仅消耗 CPU 和大量磁盘 I/O,还会导致物理存储上的内存碎片。原本可以紧凑存放的数据,变得松散(页的填充率降低),进而导致全表扫描或范围查询时性能下降。
💡 补充:有没有不适用“整型自增主键”的场景?
虽然“整型自增主键”是绝大多数情况下的首选,但在某些复杂架构中也会有局限性:
- 分库分表(分布式架构):如果多个表各自维护自己的自增主键,合并数据时一定会产生主键冲突。
- 业务安全要求极高的场景:自增主键容易暴露出业务的核心数据(例如,竞争对手注册两个账号,通过比较 ID 差值就能推算出你这一天的业务增量)。
在这些场景下,业界的主流解决方案是:
使用类似雪花算法(Snowflake ID)生成的分布式 ID。
这种 ID 本质上是 BIGINT(整型),且包含时间戳信息,整体上呈现趋势递增(满足了减少页分裂的要求,又解决了分库分表的主键冲突和数据泄露问题),完美契合了 InnoDB 的底层原理。