 播面
播面 在MySQL中,什么是“回表”?如何避免回表操作?
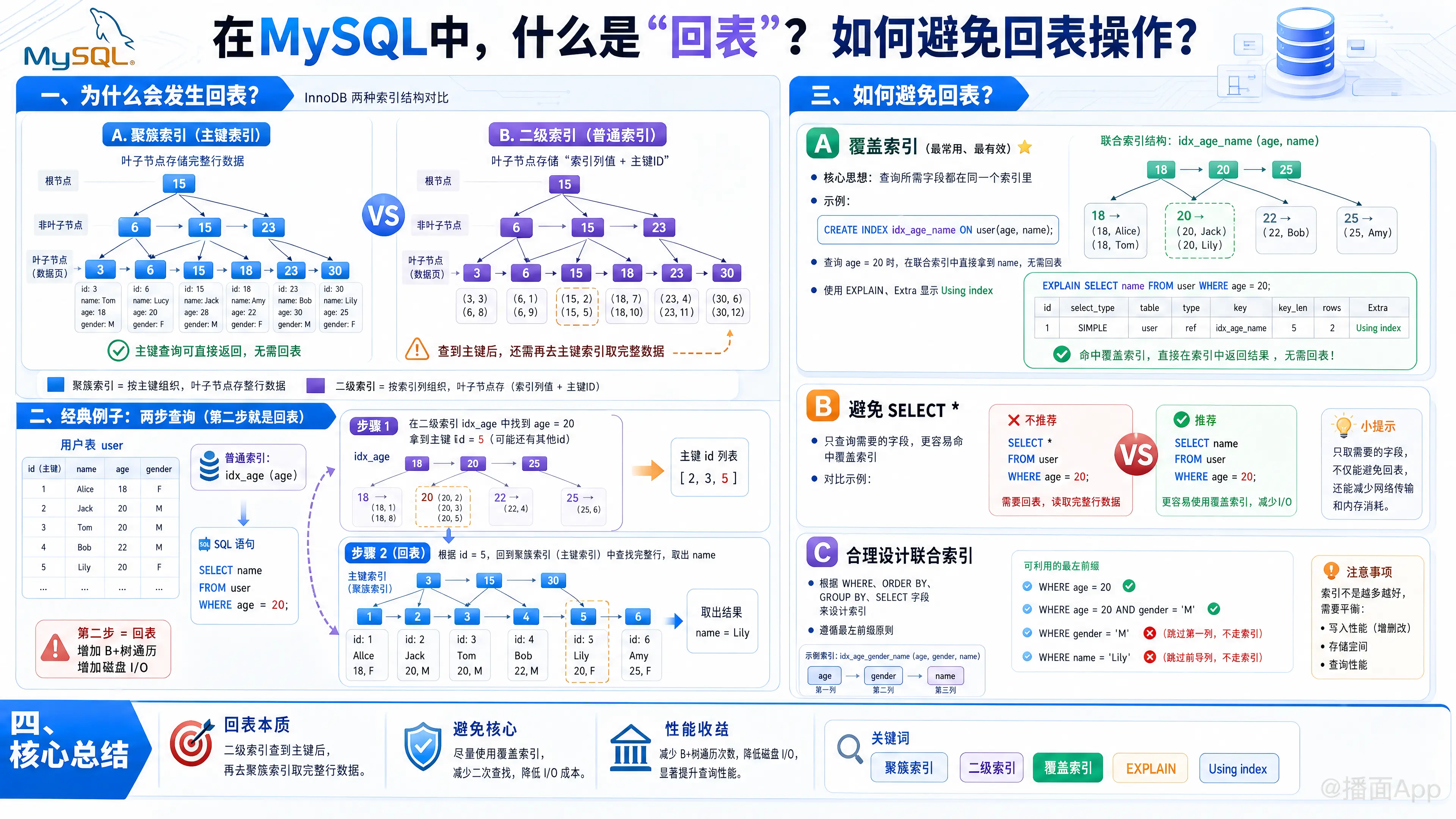
在 MySQL(特别是 InnoDB 存储引擎)中,“回表”(Table Lookup 或 Row Retrieval) 是一个非常重要的性能优化概念。
简单来说,“回表”就是数据库在使用普通索引(二级索引)查询到数据的对应主键后,还需要再次根据主键到主键索引(聚簇索引)中去获取完整的数据行的过程。
为了让你彻底明白,我们需要先了解 InnoDB 的两种索引结构,然后再探讨如何避免它。
一、 为什么会发生“回表”?
在 InnoDB 中,索引分为两大类:
- 聚簇索引(Clustered Index / 主键索引):
- 通常是表的主键。
- 它的叶子节点(B+树的最底层)存储的是完整的行数据。
- 查询过程: 如果你通过主键查询(例如
SELECT * FROM table WHERE id = 1),直接扫描聚簇索引就能拿到这行的所有数据。这不需要回表。
- 二级索引(Secondary Index / 非主键索引 / 辅助索引):
- 你为普通列(比如
age、name)创建的索引。 - 它的叶子节点存储的不是完整的数据,而是当前索引列的值和对应的主键 ID。
- 查询过程: 如果你通过普通列查询,并且要获取非索引列的数据,就会发生回表。
- 你为普通列(比如
🚗 “回表”的生动例子
假设有一个用户表 user:
- 字段:
id(主键),name,age,gender - 索引:在
age字段上建了一个普通索引idx_age
现在执行查询:SELECT name FROM user WHERE age = 20;
MySQL 的执行步骤如下:
- 第一步(查二级索引): 引擎先在
idx_age这棵 B+ 树上找到age = 20的记录。在这个叶子节点上,它只获取到了age=20和对应的主键id(假设id=5)。注意,这里没有name字段的数据。 - 第二步(回表): 拿着拿到的
id=5,回到聚簇索引(主键索引) 的 B+ 树上再次进行查找,找到id=5的完整数据行,然后提取出name字段返回。
这“第二步”拿着主键去聚簇索引再次查询的过程,就叫作“回表”。
回表的代价: 相当于多遍历了一棵 B+ 树,增加了磁盘 I/O 操作。如果查询命中了大量数据,那么大量的回表操作会严重拖慢查询速度。
二、 如何避免“回表”操作?
避免回表的核心思想就是:让你要查询的数据,在第一步(查二级索引)时就能全部拿到。
主要有以下三种方法:
1. 使用“覆盖索引”(Covering Index)(最常用、最有效)
覆盖索引不是一种新的索引类型,而是一种效果:当一个索引包含了(或覆盖了)查询语句中需要的所有字段时,就叫覆盖索引。
- 解决思路: 创建联合索引,把
SELECT后面需要的列和WHERE后面作为条件的列,都包含在这个联合索引里面。 - 优化上面的例子:
为了避免SELECT name FROM user WHERE age = 20;产生回表,我们可以删除原来的idx_age,创建一个联合索引:CREATE INDEX idx_age_name ON user(age, name); - 优化后的执行过程: 引擎在
idx_age_name树上找到age=20的节点,发现该节点上已经包含了name的值,于是直接返回,不再需要去主键索引查找。回表被成功避免。 - 如何查看是否使用了覆盖索引: 使用
EXPLAIN查看执行计划,如果Extra列显示Using index,就说明用到了覆盖索引,没有发生回表。
2. 避免使用 SELECT *
- 解决思路: 只查询真正需要的列。
- 原因: 如果你写
SELECT *,意味着你要获取整行的所有字段。除非你把表中所有的列都建在一个超级联合索引里(这显然是不现实且极其影响写入性能的),否则只要使用二级索引查询,就一定会发生回表。 - 建议: 养成良好的习惯,需要什么字段就
SELECT什么字段,配合联合索引实现覆盖索引。
3. 利用“索引下推”(Index Condition Pushdown, ICP)(减少回表次数)
这是 MySQL 5.6 引入的一个优化特性。它不能完全消除回表,但能大幅减少回表的次数。
- 假设场景: 表有联合索引
(name, age)。查询:SELECT * FROM user WHERE name LIKE '张%' AND age = 20; - 没有 ICP 的时代(MySQL 5.6之前): 存储引擎只能用联合索引找到所有名字是“张”开头的记录的主键 ID,然后把所有满足条件的 ID 全部回表查出完整行,最后在 MySQL 的 Server 层再根据
age = 20去过滤这些数据。 - 有 ICP 的时代: 存储引擎在联合索引查到名字是“张”开头的记录后,会先在索引内部判断一下
age是否等于 20(因为联合索引里有age的数据)。只有满足age = 20的记录,才会拿着 ID 去回表。 - 效果: 把过滤条件“下推”到了存储引擎层,拦截了大量不符合条件的数据,极大地减少了回表的次数。
- 如何查看是否使用了索引下推: 使用
EXPLAIN,如果Extra列显示Using index condition,说明使用了索引下推。
总结
- 回表:普通索引查到主键后,再用主键去主键索引查完整数据的过程,会增加 I/O 开销。
- 避免回表的终极杀器:建立合理的联合索引以实现覆盖索引(
Using index),并坚决避免写SELECT *。