 播面
播面 如何在 PostgreSQL 集群中实现故障转移(Failover)?
在 PostgreSQL 集群中实现故障转移(Failover)是构建高可用性(High Availability, HA)架构的核心环节。
需要明确的是:PostgreSQL 原生原生支持主从流复制(Streaming Replication)和手动提升备库(Promote),但并不自带“自动故障转移(Automatic Failover)”功能。要实现自动故障转移,必须依赖第三方高可用组件。
以下是实现 PostgreSQL 故障转移的完整指南,分为基础原理、主流自动故障转移工具、客户端路由以及最佳实践四个部分。
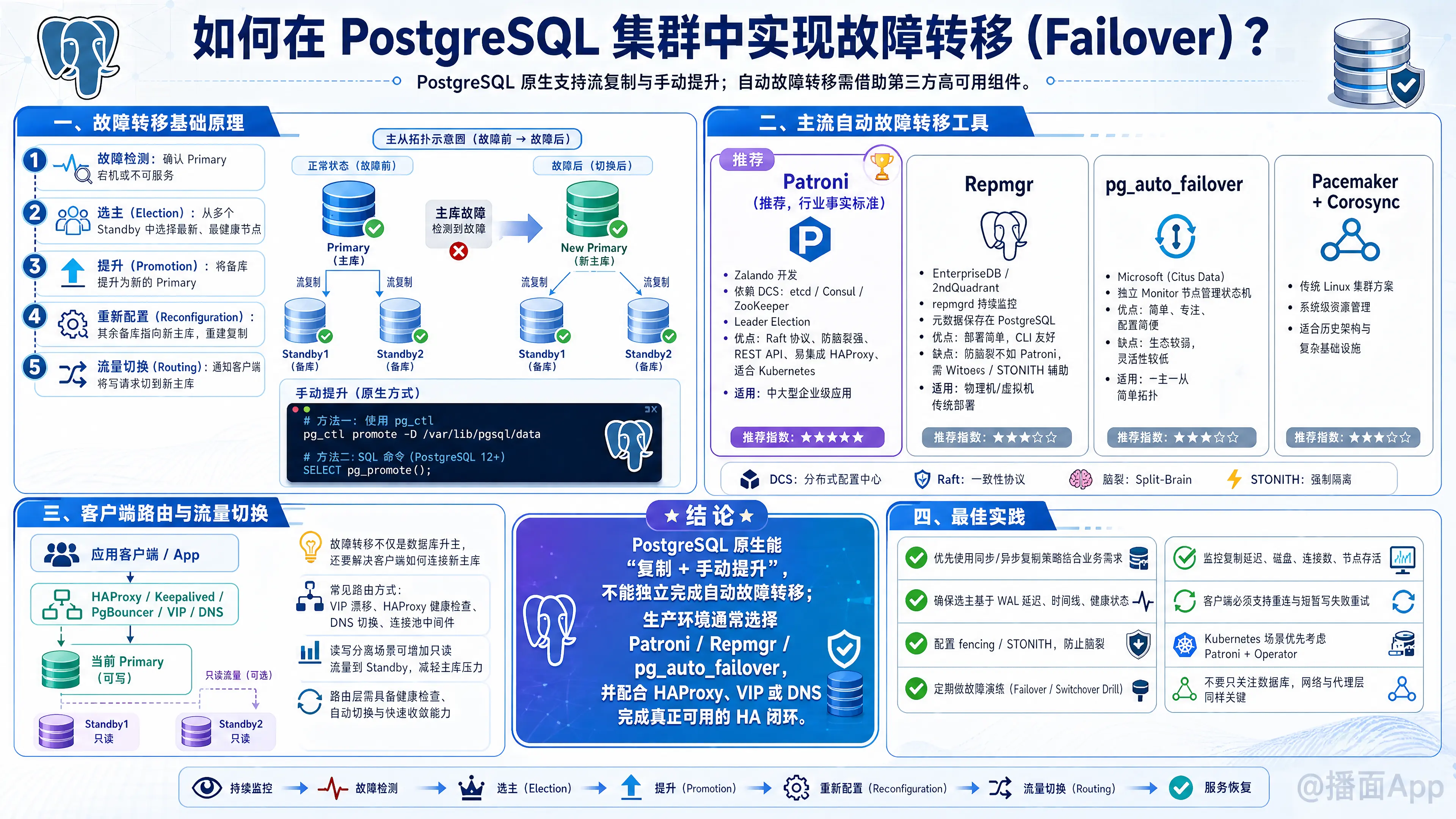
一、 故障转移的基础原理
故障转移的核心步骤如下:
- 故障检测:确认主节点(Primary)已经宕机或无法提供服务。
- 选主(Election):在多个备节点(Standby)中,挑选出一个数据最新、状态最健康的节点。
- 提升(Promotion):将选出的备节点提升为新的主节点,使其可读可写。
- 重新配置(Reconfiguration):将其他存活的备节点指向新的主节点,重新建立复制关系。
- 流量切换(Routing):通知应用端(客户端)将写请求发送到新的主节点。
手动提升(原生命令):
如果是手动进行故障转移,可以在备库上执行以下命令之一:
bash
# 方式一:使用 pg_ctl
pg_ctl promote -D /var/lib/pgsql/data
# 方式二:在 psql 中执行 SQL 函数(PG 12+)
SELECT pg_promote();二、 主流的自动故障转移工具
为了实现自动化,业界有几种主流的解决方案:
1. Patroni(目前最推荐、行业事实标准)
由 Zalando 开发,是目前最流行、最健壮的 PG 高可用解决方案。
- 工作原理:它依赖分布式配置存储(DCS,如 etcd, Consul, 或 ZooKeeper)来保存集群状态和进行领导者选举(Leader Election)。
- 优点:
- 依靠 DCS 的 Raft 协议,彻底解决了脑裂(Split-brain)问题。
- 支持自定义回调脚本,集成度高。
- 自带 REST API,方便与 HAProxy 等负载均衡器集成。
- 适用场景:中大型企业级应用、Kubernetes 环境(Zalando 的 Postgres Operator 就是基于 Patroni)。
2. Repmgr (Replication Manager)
由 EnterpriseDB (2ndQuadrant) 开发和维护。
- 工作原理:它有一个后台守护进程
repmgrd,持续监控节点状态。它不需要额外的 etcd,而是将集群元数据存储在 PostgreSQL 自己的数据库中。 - 优点:部署相对简单,不需要引入额外的 etcd/Consul 组件。命令行工具非常友好。
- 缺点:防脑裂机制不如 Patroni 强(通常需要配置 Witness 见证节点或依赖外部 STONITH 机制)。
- 适用场景:传统物理机/虚拟机部署,不希望引入复杂基础架构的团队。
3. pg_auto_failover
由 Microsoft (Citus Data 团队) 开发。
- 工作原理:引入了一个名为 Monitor(监控节点)的独立 PostgreSQL 实例来充当状态机,管理 Primary 和 Standby。
- 优点:设计极其简单,专注于“只做一件事并做好”,配置极其简便。
- 缺点:生态不如 Patroni 丰富,架构灵活性较低。
- 适用场景:一主一从的简单拓扑结构。
4. Pacemaker + Corosync (传统架构)
- 工作原理:利用 Linux 系统级别的集群资源管理器。
- 优点:可以不仅管理 PG,还能管理 VIP(虚拟 IP)、存储等系统级资源。
- 缺点:配置极其复杂,学习曲线陡峭,对 PG 的特性感知不如专门的 PG HA 工具敏感。
三、 客户端流量路由(应用如何连新主库?)
数据库完成 Failover 后,最关键的是应用程序必须能自动连接到新的主库。常见的实现方案有三种:
方案 A:使用连接池 + 代理(HAProxy + PgBouncer)
这是搭配 Patroni 最经典的架构。
- HAProxy 作为入口,暴露一个统一的写端口和一个读端口。
- HAProxy 定时通过 HTTP 请求检查 Patroni 的 REST API(例如
/master接口)。 - 如果发生 Failover,Patroni 接口状态改变,HAProxy 会自动将写流量路由到新晋升的主库。
- PgBouncer 部署在 PG 节点上或 HAProxy 后面,用于连接池复用。
方案 B:使用虚拟 IP (VIP)
- 通过 Keepalived 或 Patroni 的回调脚本,在主库绑一个浮动的 VIP。
- 发生 Failover 时,VIP 从旧主库解绑,漂移并绑定到新主库。
- 缺点:跨网段漂移困难,且可能会有 ARP 缓存更新延迟导致短时间连不上。
方案 C:使用智能客户端驱动 (Multi-host Connection String)
现代的 PostgreSQL 驱动程序(如 JDBC、libpq、psycopg2)支持在连接字符串中配置多个 IP,并自动寻找可写的主库。
- JDBC 示例:plaintext
jdbc:postgresql://host1:5432,host2:5432,host3:5432/mydb?targetServerType=primary - 原理:应用尝试连接 host1,如果是只读备库,则断开并尝试 host2,直到找到
primary(主库)为止。 - 优点:不需要任何中间件,架构最简单。
- 缺点:应用端需要感知数据库的所有节点 IP。
四、 实施 Failover 的最佳实践与挑战
- 防止脑裂(Split-Brain Fencing)
脑裂是指由于网络分区,旧主库和新主库都认为自己是老大,同时接受写入,导致数据严重冲突。- 对策:必须使用具备 Quorum(多数派)机制的工具(如 Patroni + etcd集群)。当旧主库与 etcd 集群失联时,必须强制将其降级(Demote)或关闭(Fencing/STONITH)。
- 同步复制 vs 异步复制(数据零丢失 RPO=0)
- 如果业务要求绝对不能丢数据,必须配置 PostgreSQL 的同步复制(
synchronous_commit = on和synchronous_standby_names)。 - 注意:同步复制会降低写入性能。如果不使用同步复制,Failover 可能会导致最后几毫秒/几秒的数据丢失。
- 如果业务要求绝对不能丢数据,必须配置 PostgreSQL 的同步复制(
- 防止备库数据落后太多
- 在选主时,HA 工具通常会选择 LSN(日志序列号)最大的备库。
- 设置
wal_keep_size(PG 13+)或使用复制槽(Replication Slots),防止主库把备库还没应用的 WAL 日志给删除了。
- 灾难恢复(结合备份)
- Failover 只是高可用,不能代替备份。
- 强烈建议结合 pgBackRest 或 WAL-G 进行连续归档(PITR),以防误删数据或集群全面崩溃。
总结建议
如果你现在需要搭建一个新的 PostgreSQL 集群并实现自动故障转移,首推架构是:
Patroni + etcd(用于管理和选主) + HAProxy(用于读写分离路由) + PgBouncer(用于连接池)。
这是目前全球众多大厂(如 GitLab、Zalando)都在使用的企业级标准架构。