 播面
播面 PostgreSQL 是如何检测和处理死锁的?
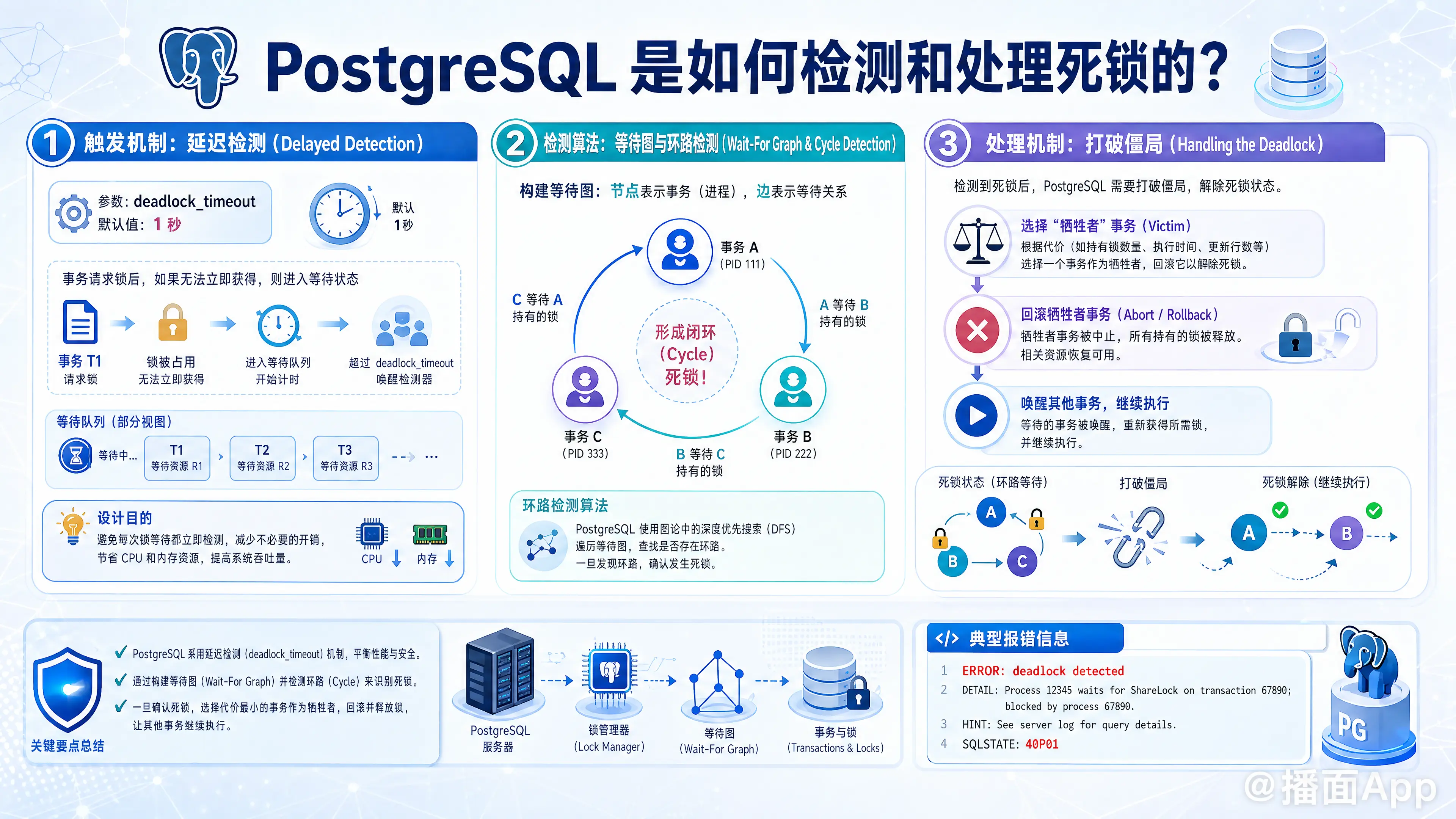
在 PostgreSQL 中,死锁(Deadlock)是指两个或多个事务在执行过程中,因争夺资源而造成的一种互相等待的现象。若无外力干涉,它们都将无法继续执行。
PostgreSQL 拥有一套成熟的机制来延迟触发、检测并处理死锁。以下是其底层原理和处理流程的详细解析:
1. 触发机制:延迟检测 (Delayed Detection)
PostgreSQL 不会在每次发生锁等待时立即进行死锁检测,因为死锁检测(构建图、寻找环)是一个消耗 CPU 和内存的昂贵操作。
- 依赖参数
deadlock_timeout:
PostgreSQL 使用一个名为deadlock_timeout的配置参数(默认值为 1 秒)。 - 工作原理:
当一个事务请求锁并被阻塞时,它只会安静地等待。只有当等待时间超过了deadlock_timeout指定的时间后,PostgreSQL 的死锁检测器才会被唤醒。 - 设计哲学:
绝大多数的锁等待都会在几毫秒到几十毫秒内解决。等待超过 1 秒(默认值)意味着系统可能出现了死锁,或者出现了严重的性能瓶颈。此时付出代价去检测死锁是值得的。
2. 检测算法:等待图与环路检测 (Wait-For Graph & Cycle Detection)
一旦死锁检测器被唤醒,PostgreSQL 就会在内部构建并分析当前的锁等待关系。
- 构建等待图 (Wait-For Graph, WFG):
数据库会将当前的事务和锁状态抽象成一个有向图。- 节点 (Nodes):代表正在运行的事务(进程)。
- 有向边 (Edges):代表“等待关系”。如果事务 A 正在等待事务 B 释放某个锁,图中就会有一条从 A 指向 B 的边 (A -> B)。
- 环路检测 (Cycle Detection):
PostgreSQL 使用图论中的算法(类似深度优先搜索 DFS)在这个“等待图”中寻找闭环(Cycle)。- 例如:如果图中存在
A -> B -> C -> A的路径,这就形成了一个死循环,意味着死锁确实发生了。 - 如果没有发现环路,说明只是单纯的长事务阻塞(比如某个事务占着锁在执行慢查询),检测器会进入睡眠,事务继续等待。
- 例如:如果图中存在
3. 处理机制:打破僵局 (Handling the Deadlock)
如果检测器在等待图中发现了闭环,PostgreSQL 必须打破这个僵局,让其他事务得以继续。
- 选择“牺牲者” (Victim Selection):
PostgreSQL 需要选择一个事务将其回滚(Rollback)。通常情况下,PostgreSQL 会选择当前触发死锁检测的那个事务(即刚刚醒来发现死锁的事务),或者是在环路中导致死循环的那个操作所属的事务作为“牺牲者”。 - 终止与回滚:
- 选定的受害事务会被强制中止(Abort),它所持有的所有锁会被自动释放。
- 数据库会向该受害事务的客户端返回一个死锁错误信息。
- 唤醒其他事务:
受害事务的锁释放后,原本等待这些锁的其他事务(在死锁环中的其他节点)就会被唤醒,获取到锁并继续执行。
死锁的报错信息通常如下:
plaintext
ERROR: deadlock detected
DETAIL: Process 12345 waits for ShareLock on transaction 67890; blocked by process 54321.
Process 54321 waits for ShareLock on transaction 09876; blocked by process 12345.
HINT: See server log for query details.(错误代码 SQLSTATE 类别通常为 40P01)
4. 监控与日志记录 (Monitoring & Logging)
为了帮助 DBA 和开发者排查死锁,PostgreSQL 提供了监控和日志记录功能:
- 记录死锁日志:
如果开启了log_lock_waits = on(强烈建议在生产环境开启),当锁等待时间超过deadlock_timeout时,数据库会将详细的死锁等待图和涉及的 SQL 语句写入 PostgreSQL 的运行日志中。 - 统计视图:
可以通过查询pg_stat_database视图来查看某个数据库发生过多少次死锁:sqlSELECT datname, deadlocks FROM pg_stat_database;
5. 开发者如何预防死锁?
死锁通常不是数据库本身的问题,而是应用程序的逻辑(SQL 访问顺序)导致的。预防死锁的最佳实践包括:
- 保持一致的加锁顺序:
这是最重要的规则。如果事务 1 总是先更新表 A 再更新表 B,那么事务 2 也应该按照表 A -> 表 B的顺序操作。 - 批量更新时先排序:
对于行级死锁(非常常见),如果在同一个事务中要更新多行记录,先对主键(ID)进行排序,然后再依次更新。
错误做法:更新 ID=5,再更新 ID=3。
正确做法:ORDER BY id,先更新 ID=3,再更新 ID=5。 - 缩短事务的执行时间:
事务越短,持有锁的时间越短,发生死锁的概率就越低。尽量将耗时的非数据库计算逻辑放在事务之外。 - 避免在事务中进行用户交互:
绝对不要在开启事务后,等待用户点击“确认”或调用耗时的第三方 API 再提交事务。 - 合理使用锁级别:
尽量依赖 MVCC,避免不必要地使用LOCK TABLE等高表级排他锁。如果必须使用SELECT ... FOR UPDATE,要确保操作范围尽可能小。