 播面
播面 讲讲Dubbo 协议的数据包结构(Header + Body),它是如何解决粘包拆包问题的?
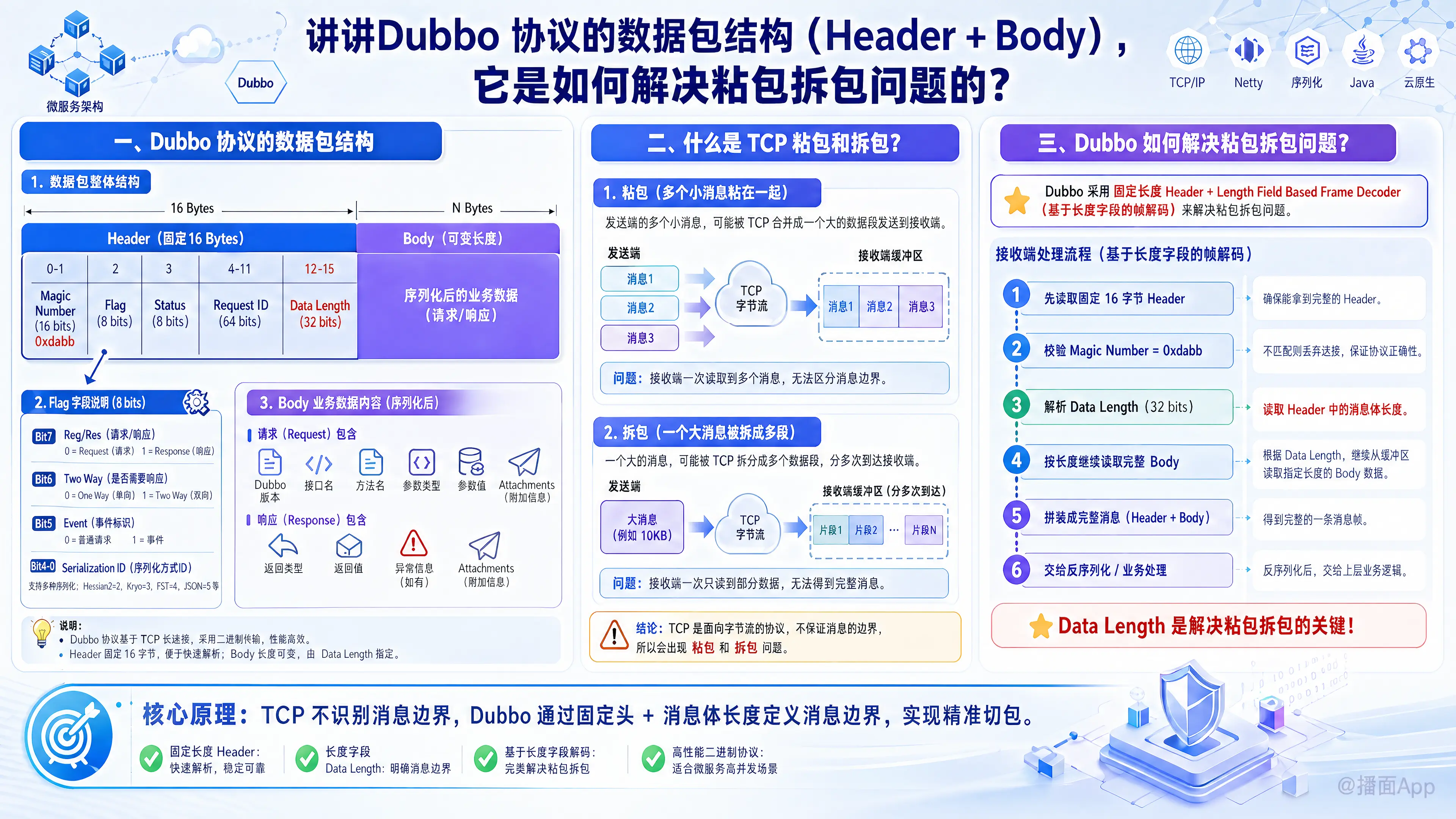
Dubbo 协议是 Dubbo 框架默认的高性能、基于 TCP 的自定义 RPC 协议。它的设计非常精简和高效。
为了讲清楚它是如何解决 TCP 粘包和拆包问题的,我们需要先深入了解它的数据包结构,因为解决粘包/拆包的核心机制就藏在它的 Header(协议头)里。
一、 Dubbo 协议的数据包结构 (Header + Body)
Dubbo 协议的数据包由两部分组成:固定长度的 Header(16 字节) + 可变长度的 Body。
1. Header(协议头)—— 固定 16 Bytes (128 bits)
无论请求还是响应,Header 的长度严格固定为 16 字节。它的内部结构被极其紧凑地划分:
| 字节位置 | 字段名称 | 长度 | 含义描述 |
|---|---|---|---|
| 0 - 1 | Magic Number | 16 bits | 魔数,固定值为 0xdabb。用于快速识别是否为 Dubbo 协议包,拦截非法流量。 |
| 2 | Flag | 8 bits | 标志位。包含多种信息: • Bit 7: Req/Res (1=请求, 0=响应)• Bit 6: Two Way (1=双向要求返回值, 0=单向单向调用)• Bit 5: Event (1=心跳包/事件包, 0=正常数据包)• Bit 4-0: Serialization ID (序列化方式,如 2=Hessian2, 6=FastJson 等) |
| 3 | Status | 8 bits | 状态码。仅在响应包中使用,表示 RPC 调用的结果(如 20=OK,30=Client Timeout,40=Bad Request 等)。请求包中该字节填 0。 |
| 4 - 11 | Request ID | 64 bits | 请求唯一标识。8字节的长整型(long)。Dubbo 是基于 TCP 长连接的异步复用模型,依靠这个 ID 来将客户端的响应和请求一一匹配。 |
| 12 - 15 | Data Length | 32 bits | 消息体长度。4字节的整型(int)。记录了后面 Body 究竟有多长。(这是解决粘包拆包的关键) |
2. Body(消息体)—— 长度可变
Body 里面装的是经过序列化(如 Hessian2、FastJSON 等)后的实际业务数据。
- 如果是 Request 消息:Body 里面包含:Dubbo 版本号、服务接口名、服务版本号、方法名、参数类型列表、实际参数值、Attachments(附加的隐式传参)。
- 如果是 Response 消息:Body 里面包含:返回值类型(如正常返回、抛出异常、返回 Null)以及实际的返回值对象。
二、 什么是 TCP 粘包和拆包?
TCP 是一个面向字节流的协议。它只负责把字节从一端传到另一端,不认识“业务消息”的边界。
- 粘包:发送方连续发送几个小数据包,TCP 底层为了优化性能(Nagle算法),把它们合并成一个大的 TCP 报文发送;或者接收方读取不及时,导致缓冲区积压了多个业务包。
- 拆包:发送方发送的一个业务数据包太大了,超过了 MSS(最大报文段长度),TCP 底层会把它拆分成多个网络数据包进行传输。
这就导致接收方从网络缓冲区读到的数据,可能是一个半消息,也可能是两个半消息。
三、 Dubbo 是如何解决粘包拆包问题的?
目前业界解决粘包/拆包通用的方案有三种:固定长度、特定分隔符(如 HTTP 的 \r\n)、基于长度字段的帧解码(Length-Field Based Frame Decoder)。
Dubbo 采用的是最通用、最高效的第三种:Header 中的固定长度 + 长度字段。
具体在 Netty 接收端(Dubbo 底层默认使用 Netty),处理粘包拆包的流程如下(对应源码中的 ExchangeCodec / DubboCodec):
1. 拆包处理(等待完整数据)
当 Netty 收到一段字节流时,Dubbo 会按照以下步骤进行解码:
- 判断 Header 是否完整:首先检查当前缓冲区里有没有凑够 16 个字节。如果连 16 个字节都不够,说明 Header 都没传完(发生了拆包),直接 return 等待下一次网络数据到达。
- 校验魔数 (Magic Number):如果有了 16 个字节,读取前 2 个字节比对是否是
0xdabb。如果不是,说明是乱码或非法协议,进行特殊处理。 - 获取 Body 长度:读取 Header 的第 12 到 15 字节,解析出一个
int值,这就是Data Length(Body 的真实长度)。 - 计算总长度并判断包是否完整:计算当前一个完整的 Dubbo 消息需要的总长度 = 16 (Header) + Data Length (Body)。
- 检查此时缓冲区里的可读总字节数。
- 如果缓冲区可读字节数 < 总长度:说明 Body 数据还没传完(发生了拆包),重置读取指针(Reset ReaderIndex),什么也不做,继续等待剩下的网络数据。
- 如果缓冲区可读字节数 >= 总长度:说明一个完整的数据包已经就绪!
2. 粘包处理(精准截取完整消息)
在上一步中,如果发现 缓冲区可读字节数 >= (16 + Data Length):
- Dubbo 会从缓冲区中精准地读取
16 + Data Length个字节。这就算成功解析出了一个完整的 Dubbo 数据包。 - 读完这一个包之后,缓冲区里剩下的字节(如果有的话)完全不受影响,它们属于下一个数据包。
- 然后通过循环机制,继续用同样的逻辑处理缓冲区里剩下的字节。这就完美解决了多个包粘在一起的问题,因为每次只按规定的长度切走一块。
总结
Dubbo 协议通过设计 16 字节的固定请求头,并在请求头中专门拿出了 4 个字节(第12-15字节)来记录消息体的长度(Data Length)。
在接收端,利用 Header定长 + 读取消息体长度 = 完整数据包总长度 的公式,配合 Netty 的字节缓冲区,只要当前缓冲区数据不够总长度就等待(解决拆包),够了就严格按总长度截取一段(解决粘包)。这种机制不仅完美的解决了 TCP 字节流的边界问题,而且由于不需要像 HTTP 那样去遍历扫描分隔符,性能极高。