 播面
播面 GPT系列为什么只使用Transformer的Decoder结构?
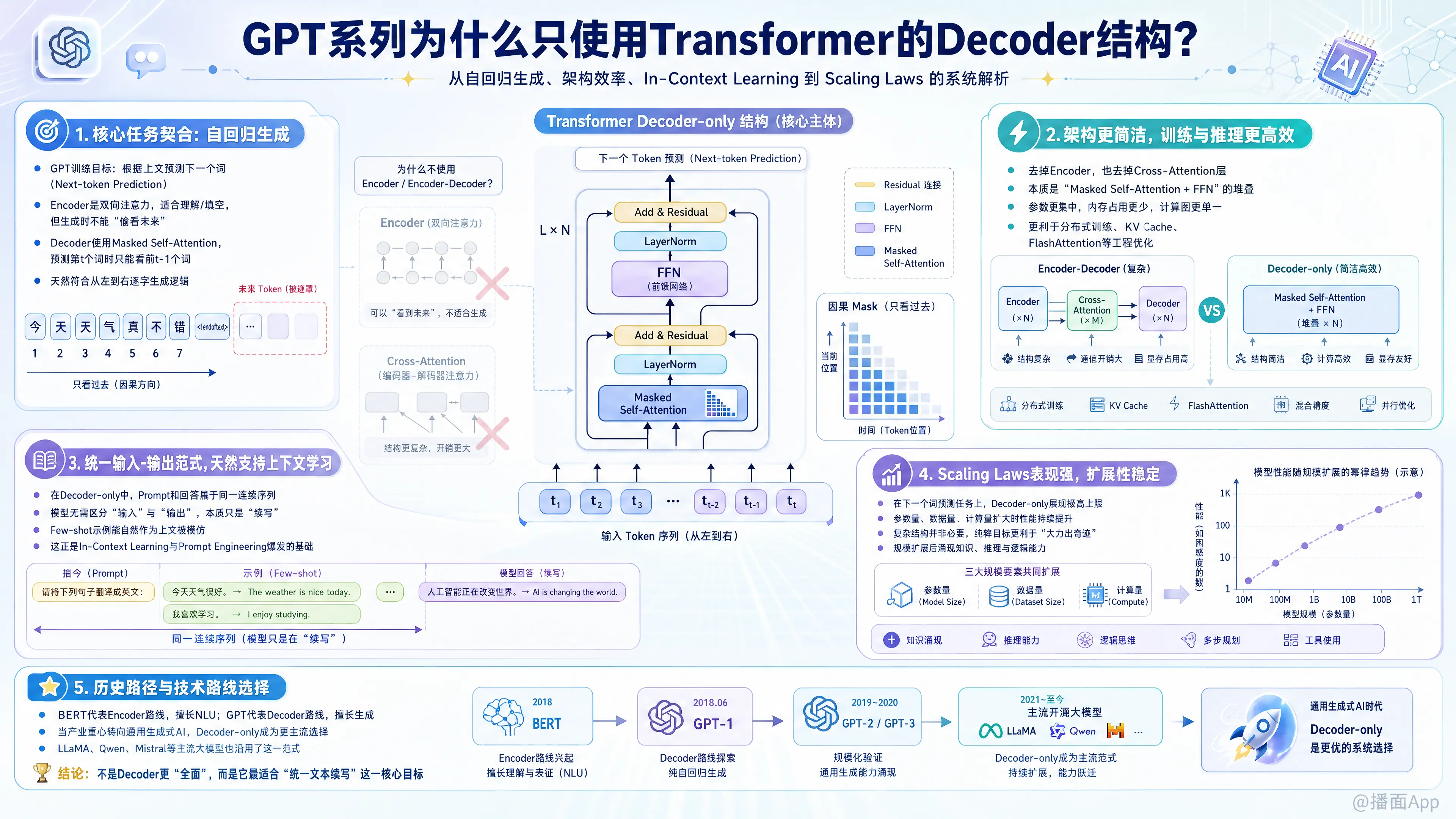
GPT系列(以及目前市面上绝大多数大语言模型,如LLaMA、Qwen、Mistral等)之所以只选择使用 Transformer 的 Decoder(解码器) 结构,主要是由其 核心任务目标(自回归生成)、架构的简洁性 以及 对“上下文学习(In-Context Learning)”的天然支持 等多方面因素决定的。
具体来说,可以归结为以下几个核心原因:
1. 核心任务的契合:自回归生成(Autoregressive Generation)
GPT的核心训练目标非常简单:“根据上文,预测下一个词(Next-token prediction)”。
- Encoder(编码器)的特点:如 BERT,使用的是双向注意力机制(Bidirectional Attention),模型在处理一个词时能同时看到它前面和后面的词。这非常适合“阅读理解”或“填空”任务,但无法用于顺畅的文本生成,因为生成文本时,未来的词是未知的,不能“提前偷看”。
- Decoder(解码器)的特点:自带 掩码自注意力机制(Masked Self-Attention)。它强制模型在预测第 个词时,只能看到前 个词,未来的信息被屏蔽(Mask掉了)。这完美契合了人类说话和写作时“从左到右、逐字生成”的逻辑,天然适合自回归任务。
2. 架构的简化与计算效率
原版的 Transformer 包含 Encoder 和 Decoder,且 Decoder 中包含一个 交叉注意力层(Cross-Attention),用于接收 Encoder 提取的信息(常用于机器翻译:Encoder看源语言,Decoder生成目标语言)。
- GPT 舍弃了 Encoder,也就顺理成章地去掉了 Cross-Attention 层。
- GPT 所谓的“Decoder-only”架构,实际上就是单纯的 “掩码自注意力层 + 前馈神经网络(FFN)” 的不断堆叠。
- 效率优势:由于没有了复杂的交叉注意力机制,模型的参数分配更加集中,内存占用更少,计算图更加单一。这在后期进行大规模分布式训练(如流水线并行、张量并行)和推理优化(如 KV Cache 管理、FlashAttention)时,工程实现极其简洁且高效。
3. 统一的“输入-输出”范式(In-Context Learning的温床)
在 Encoder-Decoder 架构(如 T5、BART)中,输入和输出是物理隔离的:提示词(Prompt)进入 Encoder,生成的回答由 Decoder 输出。
- Decoder-only 架构打破了这种隔离。在 GPT 中,所有的文本(无论是用户的 Prompt,还是模型自己生成的回答)都被视为同一个连续的序列。
- 模型不需要区分什么是“输入”,什么是“输出”,它只做一件事:续写。
- 这种统一的表示空间,使得模型能够极好地进行 上下文学习(In-Context Learning)。当你给它几个例子(Few-shot)时,它只是把这些例子当成上文,顺理成章地模仿着“续写”下去。这也是为什么 GPT-3 能够引发“提示词工程(Prompt Engineering)”浪潮的根本原因。
4. 强大的 Scaling Laws(缩放定律)表现
OpenAI 在早期的研究中发现,语言模型的性能与计算量、参数量和数据量之间存在精确的数学幂律关系(Scaling Laws)。
- 研究表明,在同等计算资源下,Decoder-only 架构在自监督的“下一个词预测”任务上展现出了极高的上限和最稳定的扩展性。
- 既然单靠“预测下一个词”就能让模型在参数量扩大后涌现出(Emergence)极强的推理、逻辑和知识储备能力,那么就没有必要保留复杂的 Encoder-Decoder 结构了。大力出奇迹的前提是方向必须极其纯粹。
5. 历史路径与技术路线的选择
- 2018年前后:Google 推出了基于 Encoder 的 BERT,在各类自然语言理解(NLU)榜单上大杀四方,当时的学术界几乎都在追捧双向模型。
- OpenAI的坚持:OpenAI 坚信“生成(Generation)”才是通往通用人工智能(AGI)的正确路径。他们认为,如果一个模型能完美地预测出任何语境下的下一个词,它就必须具备对人类世界的所有知识、常识、逻辑和语法的深刻理解。为了贯彻这个理念,他们从 GPT-1 到 GPT-4 一直死磕 Decoder-only 的自回归架构,最终证明了这条道路不仅走得通,而且潜力深不见底。
总结
GPT只使用 Decoder 结构,是因为 “掩码自注意力”是实现“预测下一个词”的最优解。去掉 Encoder 让模型结构极致简单、算力利用率极高,并且使得输入和输出融为一体,最终在庞大数据和算力的催化下,孕育出了今天我们所看到的强大通用能力。