 播面
播面 Redis IO多路复用深度解析
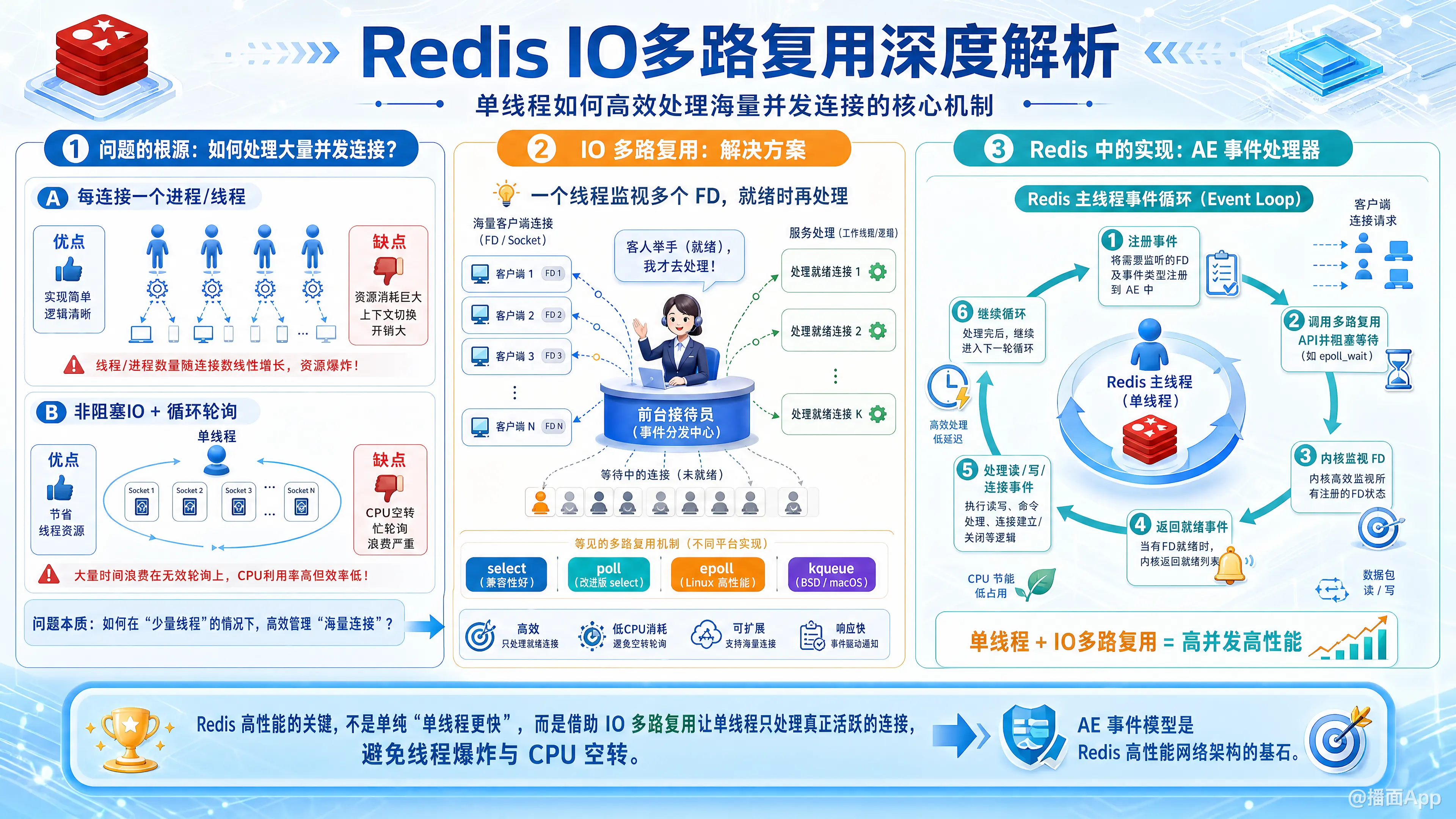
本文讲解 Redis 如何利用 IO 多路复用技术,让单线程高效处理海量并发连接,这是其高性能架构的基石。
我们来深入、系统地讲解一下 Redis 的 IO 多路复用(I/O Multiplexing)。这是理解 Redis 高性能核心机制的关键。
1. 问题的根源:网络服务如何处理大量并发连接?
Redis 是一个典型的网络服务,它需要同时处理来自成千上万个客户端的连接和请求。我们先看看几种传统的网络模型以及它们的缺陷:
模型一:每个连接一个进程/线程 (Multi-process/Multi-thread)
- 工作方式:主进程监听端口,每当有新的客户端连接进来,就
fork一个子进程或创建一个新线程来专门处理这个连接。 - 优点:实现简单,逻辑清晰。每个连接的处理都是独立的,不会互相影响。
- 缺点:
- 资源消耗巨大:每创建一个进程/线程,操作系统都要分配内存、CPU 时间片等资源。当连接数达到成千上万时,系统资源会迅速耗尽。
- 上下文切换开销大:CPU 需要在不同的进程/线程之间频繁切换,这个切换过程本身是有成本的,会浪费大量 CPU 时间。
对于像 Redis 这样追求极致性能和低延迟的内存数据库来说,这种模型是完全不可接受的。
模型二:非阻塞IO + 循环轮询 (Non-blocking I/O + Busy-polling)
- 工作方式:将所有 socket 设置为非阻塞模式。用一个
while(true)循环,不断地遍历所有连接,依次询问每个连接:“你有数据要读吗?”(recv()),或者“你可以写数据了吗?”(send())。 - 优点:避免了为每个连接创建线程,节省了资源。
- 缺点:
- CPU 浪费:无论连接是否活跃,循环都会不停地遍历所有连接。当大部分连接都处于空闲状态时,这个循环做了大量的无用功,导致 CPU 占用率 100%,却没处理多少实际请求。
这种模型虽然解决了资源消耗问题,但带来了严重的 CPU 浪费问题。
2. 解决方案:IO 多路复用 (I/O Multiplexing)
IO 多路复用就是为了解决上述问题而生的。它的核心思想是:用一个线程/进程来监视多个文件描述符(File Descriptor, FD),一旦某个 FD 就绪(即可以进行读或写操作),就通知应用程序进行相应的处理。
可以把它想象成一个高效的“前台接待员”。
- 没有多路复用:
- 模型一:每个客人(连接)配一个专属服务员(线程),服务员大部分时间都在等客人开口,非常浪费人力。
- 模型二:一个服务员(线程)不停地问每一个客人:“您需要服务吗?”,即使客人不需要,也一遍遍地问,把自己累得半死。
- 有了多路复用:
- 所有客人(连接)都坐在大厅里。前台接待员(IO 多路复用机制)盯着大厅。哪个客人举手(数据就绪),接待员就通知服务员(线程)过去为他服务。服务员只在客人需要时才工作,非常高效。
这里的“前台接待员”就是操作系统内核提供的 select、poll、epoll、kqueue 等系统调用。
3. Redis 中的 IO 多路复用实现
Redis 的 IO 模型正是基于 IO 多路复用构建的。它自己封装了一个事件处理器,称为 AE(Ae Events)。这个事件处理器是对不同操作系统提供的 IO 多路复用技术的上层封装。
Redis 的事件循环 (Event Loop)
Redis 的主线程就是一个巨大的事件循环。这个循环不断地执行以下步骤:
- 注册事件:告诉内核需要监听哪些 socket(比如监听新的连接、监听已连接客户端的读/写事件)。
- 调用多路复用 API:调用
select/poll/epoll_wait/kevent等函数,将自己阻塞,等待内核的通知。此时,Redis 主线程不消耗 CPU。 - 内核监视:内核会监视所有被注册的 socket。
- 事件就绪:当某个或某些 socket 的数据准备好了(比如客户端发来了命令),内核会中断阻塞,唤醒 Redis 主线程。API 调用会返回一个“就绪列表”。
- 事件分发:Redis 主线程拿到“就绪列表”后,开始遍历这些就绪的 socket。
- 事件处理:根据 socket 发生的事件类型(读事件或写事件),调用预先绑定好的事件处理器函数(handler)。
- 读事件:执行
readQueryFromClient,从 socket 读取客户端的命令,解析并执行。 - 写事件:执行
sendReplyToClient,将命令执行的结果返回给客户端。
- 读事件:执行
- 循环往复:处理完所有就绪事件后,回到第 2 步,再次阻塞,等待下一次事件的发生。
关键实现:select, poll, epoll, kqueue
Redis 的 AE 模块会根据编译时所在的操作系统,自动选择最高效的 IO 多路复用实现:
select:- 优点:POSIX 标准,跨平台性最好。
- 缺点:
- 数量限制:单个进程能监视的 FD 数量有限制(通常是 1024),由
FD_SETSIZE宏定义。 - 性能开销:每次调用
select,都需要把整个 FD 集合从用户空间拷贝到内核空间。 - 线性扫描:
select返回后,程序需要遍历整个 FD 集合,才能找出哪些 FD 是就绪的,时间复杂度为 O(n)。
- 数量限制:单个进程能监视的 FD 数量有限制(通常是 1024),由
poll:- 优点:解决了
select的数量限制问题,它使用一个链表结构,没有最大连接数限制。 - 缺点:依然存在拷贝和线性扫描的问题,性能随连接数增多而下降。
- 优点:解决了
epoll(Linux 系统上的王牌):- 优点:
- 无数量限制:监视的 FD 数量只受限于系统内存。
- 无须重复拷贝:通过
epoll_ctl将 FD 注册到内核中的一个事件表里,这个操作只需要做一次。每次调用epoll_wait时,无需再拷贝 FD 集合。 - 无须线性扫描:
epoll_wait返回时,直接返回一个就绪 FD 的列表,程序只需遍历这个(通常很小的)列表即可。这是通过内核的回调机制实现的,效率极高,时间复杂度是 O(1)。
- 是 Linux 平台上 Redis 的首选。
- 优点:
kqueue(FreeBSD, macOS 上的王牌):- 与
epoll类似,也是一种高效的、事件驱动的 IO 多路复用机制,工作原理和性能优势与epoll相当。
- 与
Redis 在 ae.c 源码中,通过宏定义和条件编译,实现了对这些不同机制的适配,从而保证在各种主流平台上都能获得最佳性能。
4. 为什么 Redis 是单线程的?
现在我们可以回答这个经典问题了。
“Redis 的核心网络模型是单线程的,但它通过 IO 多路复用,实现了对大量并发连接的高效处理。”
- 单线程的好处:
- 避免了多线程的上下文切换开销。
- 避免了多线程的锁竞争问题。代码实现更简单,没有死锁等复杂问题。
- 单线程的底气:
- IO 多路复用:单线程可以在一个循环里处理成千上万的连接,IO 不会成为瓶颈。
- 纯内存操作:Redis 的绝大部分操作都在内存中完成,速度极快。CPU 不是性能瓶颈(瓶颈通常在网络 IO 或内存大小)。
注意:严格来说,现在的 Redis 并非完全是单线程。它在后台也使用了一些线程来处理耗时操作,比如文件持久化(bgsave)、AOF 重写、文件关闭(lazyfree)等,以避免阻塞主事件循环。但其核心的、处理客户端请求的模块,确实是单线程的。
总结
Redis IO 多路复用是 Redis 高性能架构的基石。它允许一个单线程的事件循环,通过与内核高效协作,非阻塞地处理成千上万个网络连接。它避免了多线程/多进程模型的巨大资源消耗和上下文切换开销,也避免了循环轮询模型的 CPU 浪费,是实现高并发网络服务的经典解决方案。