 播面
播面 为什么原始Transformer选择正弦和余弦函数作为位置编码,而不是直接传入绝对索引数字?
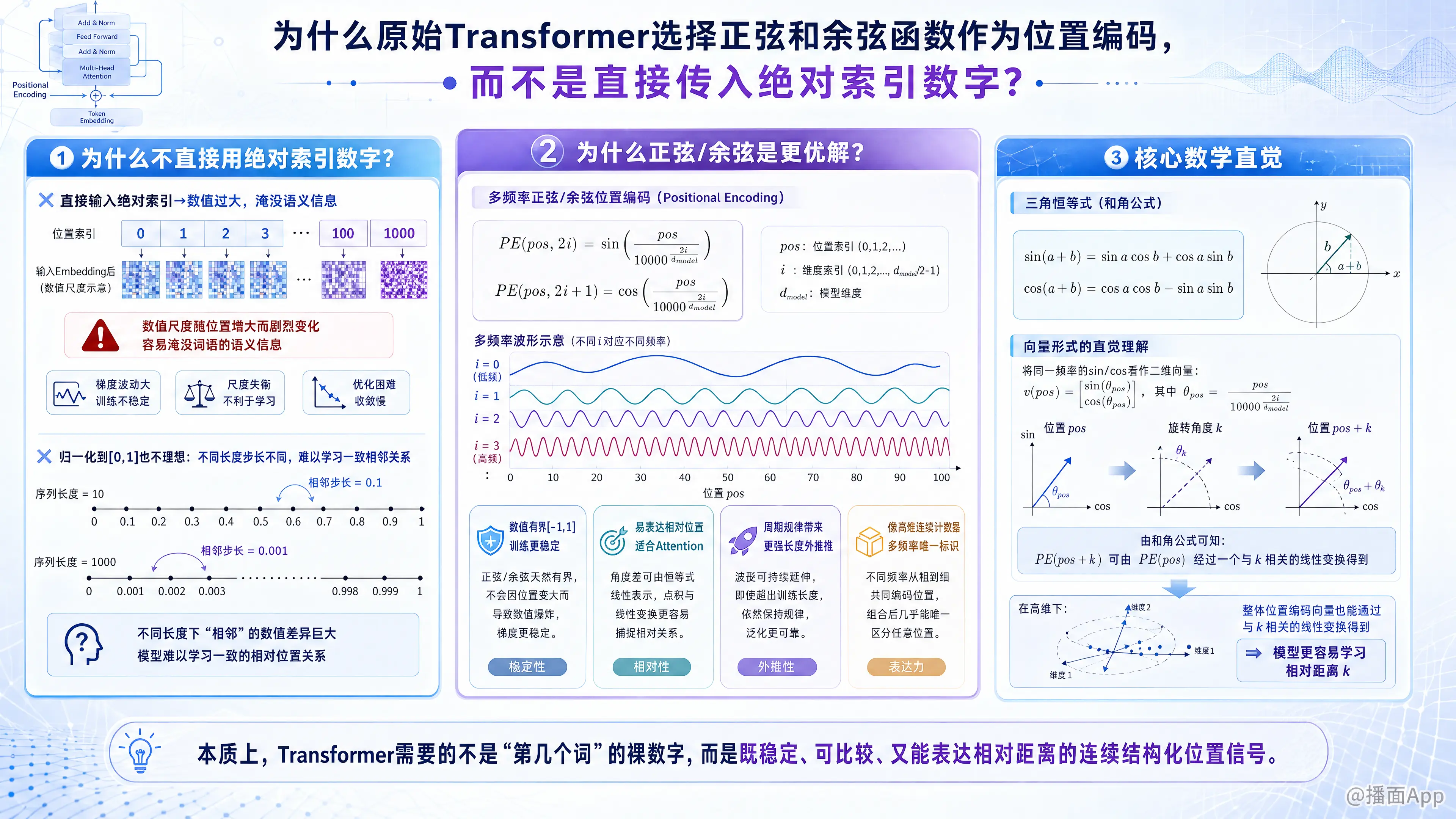
原始的 Transformer(在《Attention Is All You Need》论文中提出)之所以选择正弦和余弦函数(Sinusoidal Positional Encoding),而不是直接传入绝对索引数字(如 0, 1, 2, 3...),是出于对数值稳定性、泛化能力以及注意力机制数学特性的深刻考量。
我们可以通过对比“为什么不用绝对索引”和“为什么用正余弦”来彻底理解这个问题。
一、 为什么不直接用绝对索引数字(0, 1, 2, 3...)?
如果直接把位置索引当作特征加到词向量里,会带来几个致命问题:
- 数值范围不受限,导致梯度不稳定
- 词向量(Token Embedding)的值通常在一个很小的范围内(比如均值为0,方差为1)。如果序列很长(比如长度为 1000),位置编码的值会大到 1000,这会完全淹没词向量本身的语义信息。
- 神经网络对输入特征的尺度(Scale)非常敏感,绝对数值过大会导致训练时梯度不稳定。
- 缺乏长度泛化能力(外推性差)
- 假设模型在训练时见过的最长句子是 512 个词。如果在推理阶段遇到了长度为 600 的句子,模型从来没见过 513~600 这样的位置数值,它将不知道如何处理这些没见过的大数字。
追问:那如果把绝对索引归一化到 [0, 1] 之间呢?
比如第一个词是 0,最后一个词是 1。
- 缺点: 步长(Step size)不固定。在一个长度为 10 的句子中,相邻词的距离是 ;但在长度为 1000 的句子中,相邻词的距离变成了 。模型很难学习到“相邻”或“相隔特定距离”的一致性概念,因为同样的距离在不同长度的句子中代表的数值完全不同。
二、 为什么正弦和余弦函数是完美的解决方案?
作者设计了不同频率的正弦和余弦函数组合作为位置编码。它的公式如下:
这种设计带来了以下极其重要的优势:
1. 数值域有界且规范(Boundedness)
正弦和余弦函数的值域始终严格在 [-1, 1] 之间。无论句子有多长( 有多大),位置编码的数值大小永远保持在与词向量相似的量级,不会出现“位置信息淹没语义信息”的情况,保证了模型训练的稳定。
2. 能够轻易表达“相对位置”(核心数学属性)
Transformer 的核心是自注意力机制(Self-Attention),它通过点积(Dot Product)和线性变换来计算词与词之间的关系。
正余弦函数有一个奇妙的三角恒等式:
这意味着,对于任意固定的偏移量 , 都可以表示为 的线性组合。
翻译成白话就是: 模型在计算 Attention 时,可以通过简单的线性变换,非常容易地学到“词 A 和词 B 之间相隔了 个位置”这种相对距离关系。这对于理解自然语言(如主谓宾的关系通常受相对距离影响)至关重要。
3. 极强的外推性(Extrapolation / 泛化到更长的序列)
因为正余弦函数是周期性函数,即使测试时遇到了比训练时更长的序列,新的位置编码也会按照已有的周期规律继续生成。模型在训练中已经熟悉了这些频率的波动规律,因此能够较好地处理超出训练长度的位置信息(尽管在实际应用中这种绝对的外推能力有一定局限,但理论上比绝对索引强得多)。
4. 高维空间的“连续二进制计数器”
你可以把这种多频率的正弦/余弦编码想象成一个连续的二进制计数器。
- 在二进制中,数字 0-7 是:
000, 001, 010, 011, 100... - 你会发现,最低位交替最快(0,1,0,1...),次低位交替慢一点(0,0,1,1...),最高位交替最慢。
- 正余弦位置编码也是同样的逻辑!公式中的 代表维度,低维度使用高频的正余弦(变化极快,区分相邻词),高维度使用低频的正余弦(变化极慢,区分宏观位置)。这样,每一个位置 都有一个独一无二的连续高维向量表示。
总结
原始 Transformer 不用绝对索引是因为它数值大、会变化、难泛化;
而选用正余弦函数,是因为它巧妙地利用了三角函数的特性,做到了数值有界、尺度统一、能通过线性变换表达相对距离,并且像一个优美的多维时钟,为序列中的每一个词烙上了精准且平滑的时间戳。
(注:现代的大模型如 BERT 后来使用了可学习的绝对位置编码,而最新的开源大模型如 LLaMA、Qwen 等则普遍走向了旋转位置编码 RoPE,但它们底层的核心思想依然是对正余弦周期性与相对位置关系的运用。)