 播面
播面 什么是 Masked Self-Attention(掩码自注意力)?
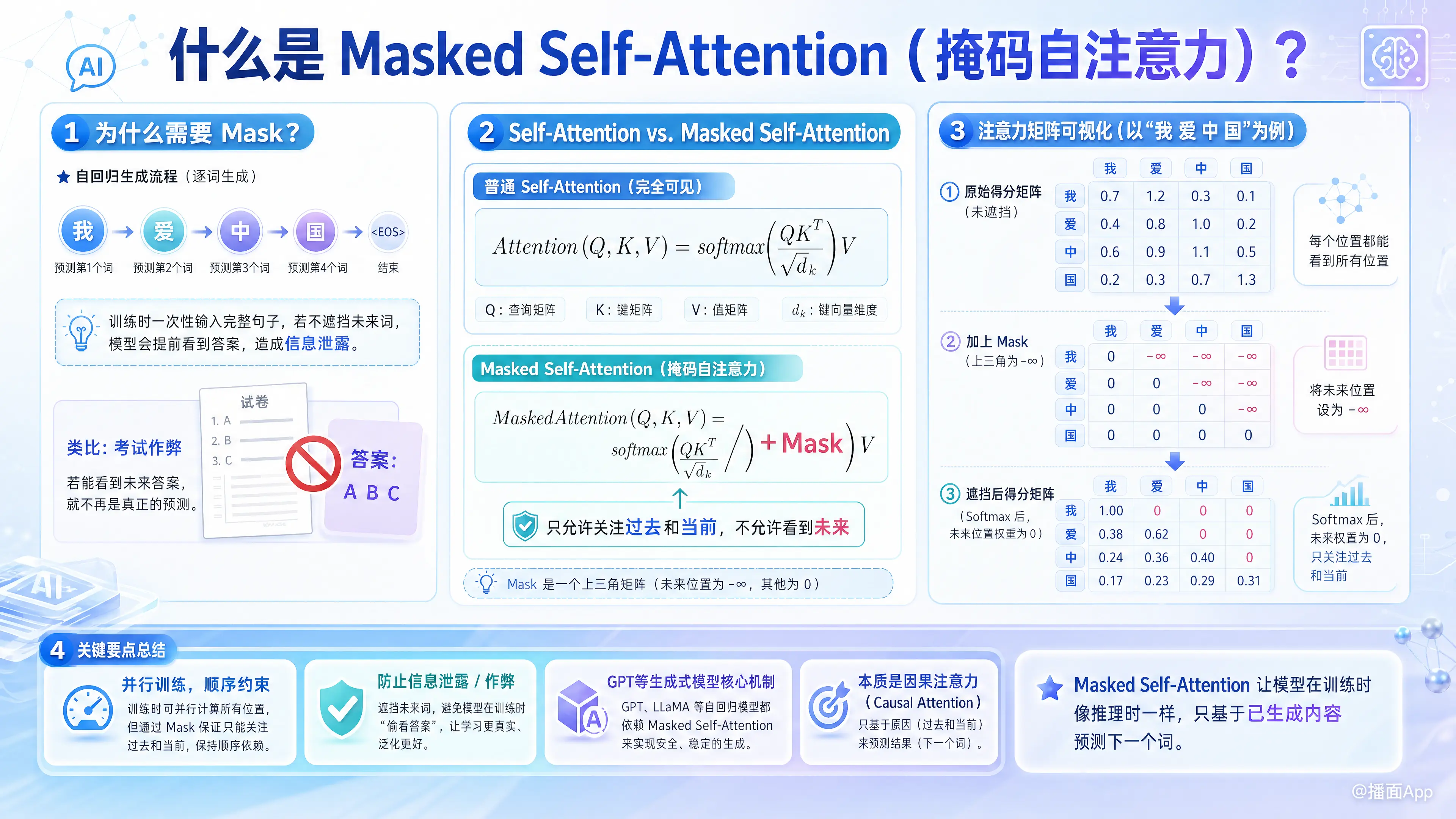
Masked Self-Attention(掩码自注意力) 是 Transformer 模型(特别是生成式模型如 GPT 系列)中的一个核心机制。
简单来说,它的作用是:在预测下一个词时,把“未来”的词遮挡住(Mask),让模型只能看到“过去”和“现在”的词,防止模型“作弊”。
为了让你彻底理解,我们可以从“为什么需要它”和“它是如何工作的”两个方面来拆解。
1. 为什么需要 Mask(掩码)?
在自然语言处理中,文本生成(比如 ChatGPT 说话)是一个自回归(Autoregressive)的过程,也就是逐词生成:
- 输入“我”,预测“爱”
- 输入“我 爱”,预测“中”
- 输入“我 爱 中”,预测“国”
在模型真正使用(推理)时,它是按顺序一个词一个词往外蹦的,自然看不到未来的词。
但是!在模型训练时,为了追求效率,我们通常会把完整的句子(如“我 爱 中 国”)一次性喂给模型。
如果不加限制(即使用普通的 Self-Attention),模型在处理“我”的时候,注意力机制会瞬间看到后面的“爱”、“中”、“国”。这就相当于考试时提前偷看了参考答案,导致模型学不到真正的预测能力。
Masked Self-Attention 的目的,就是为了在并行训练时,消除这种“信息泄露(未来看到过去)”。
2. 它是如何工作的?(原理解析)
普通的自注意力(Self-Attention)公式是:
Masked Self-Attention 只是在这个公式里加了一个掩码矩阵(Mask Matrix):
我们以句子 “我 爱 中 国” 为例,看看这个 Mask 矩阵是怎么起作用的:
第一步:计算原始的注意力得分(未遮挡)
如果没有 Mask,模型计算出的注意力得分矩阵是一个 的矩阵,每个词都会和所有的词计算相关性:
我 爱 中 国
我 [ 2.1, 1.5, -0.3, 0.8 ] <-- 处理"我"时,看到了后面的词
爱 [ 1.2, 3.0, 0.5, -0.1 ] <-- 处理"爱"时,看到了后面的词
中 [-0.5, 0.8, 2.5, 1.1 ]
国 [ 0.4, -0.2, 1.5, 3.2 ]第二步:加上 Mask 矩阵
我们创建一个上三角矩阵,把对角线右上角(代表未来的词)的值设为 负无穷大(),左下角(代表过去和现在的词)设为 0:
我 爱 中 国
我 [ 0, -inf, -inf, -inf ]
爱 [ 0, 0, -inf, -inf ]
中 [ 0, 0, 0, -inf ]
国 [ 0, 0, 0, 0 ]把这个 Mask 矩阵加到第一步的得分矩阵上:
我 爱 中 国
我 [ 2.1, -inf, -inf, -inf ] <-- "我" 只能看到 "我"
爱 [ 1.2, 3.0, -inf, -inf ] <-- "爱" 只能看到 "我", "爱"
中 [-0.5, 0.8, 2.5, -inf ] <-- "中" 可以看到 "我", "爱", "中"
国 [ 0.4, -0.2, 1.5, 3.2 ] <-- "国" 可以看到所有词第三步:经过 Softmax 激活函数
Softmax 函数的特性是:。
所以,那些负无穷大的地方,概率变成了绝对的 0。转换成注意力权重后变成了这样:
我 爱 中 国
我 [ 1.0, 0, 0, 0 ] (100%注意力在"我"上)
爱 [ 0.1, 0.9, 0, 0 ] (注意力分配给"我"和"爱",未来是0)
中 [ 0.1, 0.3, 0.6, 0 ]
国 [ 0.1, 0.1, 0.3, 0.5 ]结论: 通过这个巧妙的矩阵加法操作,模型在处理任何一个词时,赋予“未来词”的注意力权重永远是 0。
3. 应用场景对比
- 普通的 Self-Attention:用于 Encoder(编码器),比如 BERT。因为 BERT 的任务是理解整段文本(如情感分析),它需要结合上下文(既看左边也看右边),所以不需要 Mask。
- Masked Self-Attention:用于 Decoder(解码器),比如 GPT 系列(ChatGPT 等)。因为它们的任务是生成文本,必须严格遵守从左到右的时间顺序,所以必须用 Mask 遮挡未来。
总结打个比方
Masked Self-Attention 就像是你在一边看书一边做填空题。为了防止你作弊,老师拿了一块黑板擦(Mask 矩阵),挡住了你当前正在读的词后面的所有内容。你只能根据已经读过的内容,去推测下一个词是什么。