 播面
播面 Transformer能够实现高度并行化计算的根本原因是什么?
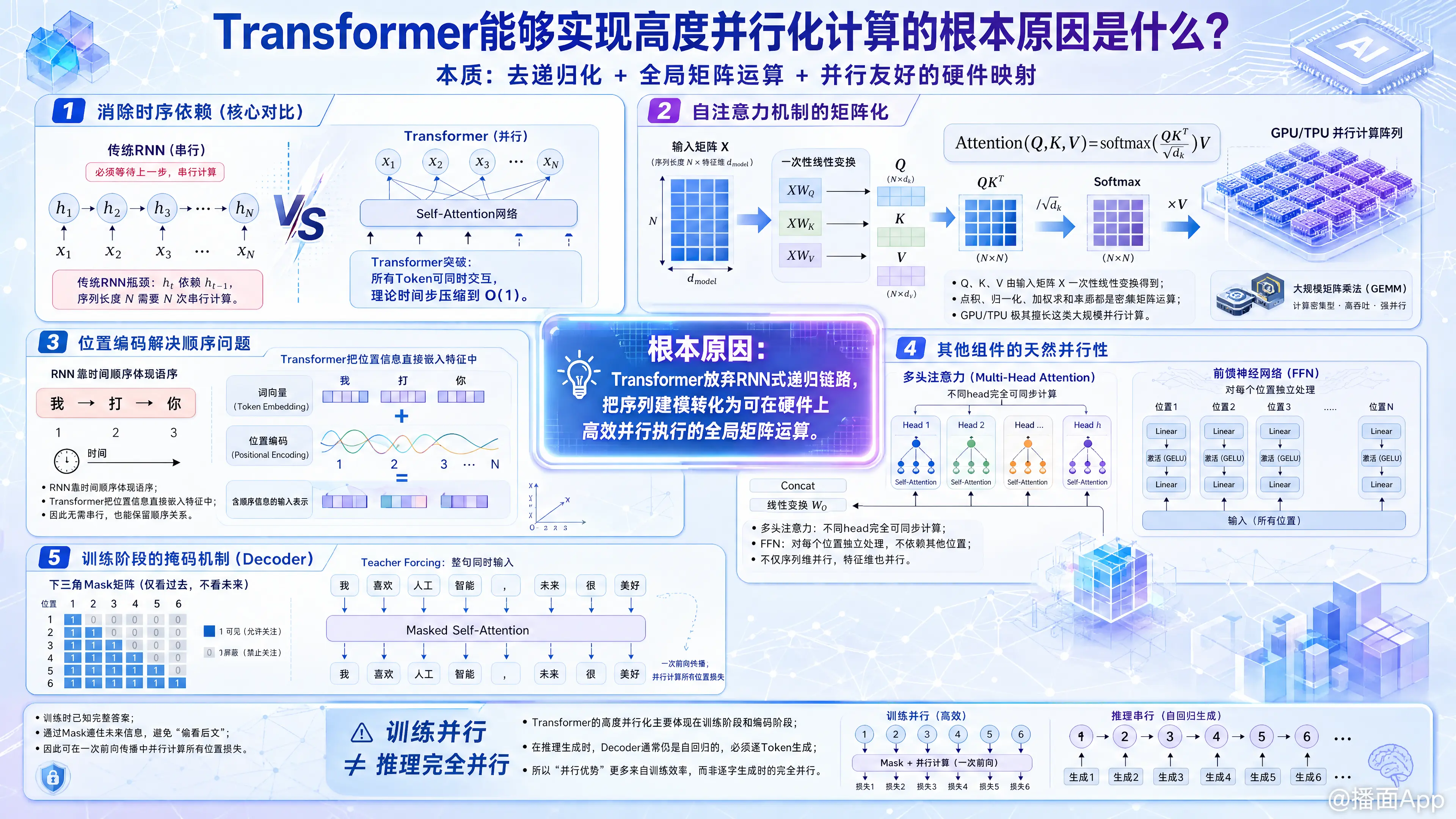
Transformer能够实现高度并行化计算的根本原因,在于它彻底摒弃了传统序列模型(如RNN、LSTM)的递归(时序)依赖结构,将序列内部的关联计算转化为了全局的矩阵乘法运算。
具体来说,这种高度并行化是由以下几个核心机制共同决定的:
1. 消除时序计算的依赖(核心对比)
- 传统RNN的瓶颈: 在RNN中,计算当前时刻的隐藏状态 必须依赖前一时刻的隐藏状态 (即 )。这意味着对于长度为 的序列,必须进行 次串行计算,后一个词必须等待前一个词处理完毕。
- Transformer的突破: Transformer完全抛弃了这种链式结构。在处理一个序列时,序列中的每一个词(Token)都可以同时与其他所有词进行交互,不存在“先后等待”的关系。序列长度 的处理时间在理论上被压缩到了 的时间步。
2. 自注意力机制(Self-Attention)的矩阵化
Transformer的核心是自注意力机制。它通过查询(Query)、键(Key)和值(Value)来计算词与词之间的相关性。
公式为:
- 在实际计算中,整个输入序列的 、、 是通过将输入矩阵 (包含所有词的特征)与权重矩阵 、、 相乘一次性得出的。
- 随后的点积()、Softmax和加权求和(乘 ),全都是标准的密集矩阵乘法(Matrix Multiplication)。现代GPU/TPU的设计极其擅长处理大规模矩阵运算,包含了成千上万个计算核心,能够将这些矩阵乘法分配到各个核心上同时执行。
3. 位置编码(Positional Encoding)巧妙解决了顺序问题
既然所有词语是同时处理的,模型怎么知道“我打你”和“你打我”的区别呢?
- RNN通过计算的时间先后来体现顺序。
- Transformer通过在输入阶段直接加上位置编码(Positional Encoding),把“位置信息”作为一种特征直接嵌入到词向量中。这样,模型在做并行的矩阵乘法时,就已经包含了词语的相对或绝对位置关系,从而在不需要串行计算的前提下保留了序列的语序信息。
4. 其他组件的天然并行性
- 多头注意力(Multi-Head Attention): 模型不仅在序列长度的维度上并行,还在特征提取的维度上并行。多个“注意力头”各自独立计算,最后再拼接起来,这些头之间的计算毫无依赖,可以完全同步进行。
- 前馈神经网络(FFN): 在注意力层之后,Transformer对每一个位置的词向量都应用了一个相同的前馈神经网络。由于每个位置的FFN计算只依赖当前位置的输出,不依赖其他位置,因此这也是完全独立且可并行的。
5. 训练阶段的掩码机制(Masked Attention)
在训练阶段,解码器(Decoder)部分依然可以高度并行。
虽然文本生成本质上是从左到右的,但训练时我们已经知道了完整的标准答案(Ground Truth)。Transformer采用了Teacher Forcing配合Mask(掩码)机制(即遮蔽掉当前词之后的词,防止“看到未来”)。这使得解码器可以在一次前向传播的矩阵运算中,同时计算出所有位置的损失,而不需要像RNN那样一个词一个词地训练。
⚠️ 一个重要的补充说明(训练并行 vs 推理串行)
必须指出的是,Transformer的“高度并行化”主要体现在训练阶段(Training)和编码阶段(Encoding / 比如BERT)。
- 在训练时: 可以一次性输入整句话,全局并行计算。
- 在推理生成时(Inference / 比如ChatGPT生成回答): 解码器(Decoder)依然是自回归(Autoregressive)的,即必须先生成第一个词,再把第一个词作为输入生成第二个词。这部分本质上还是串行的(尽管现在有KV Cache等技术来加速计算,但无法改变逐字生成的串行本质)。