 播面
播面 相比于传统的RNN/LSTM和CNN,Transformer的核心优势和劣势分别是什么?
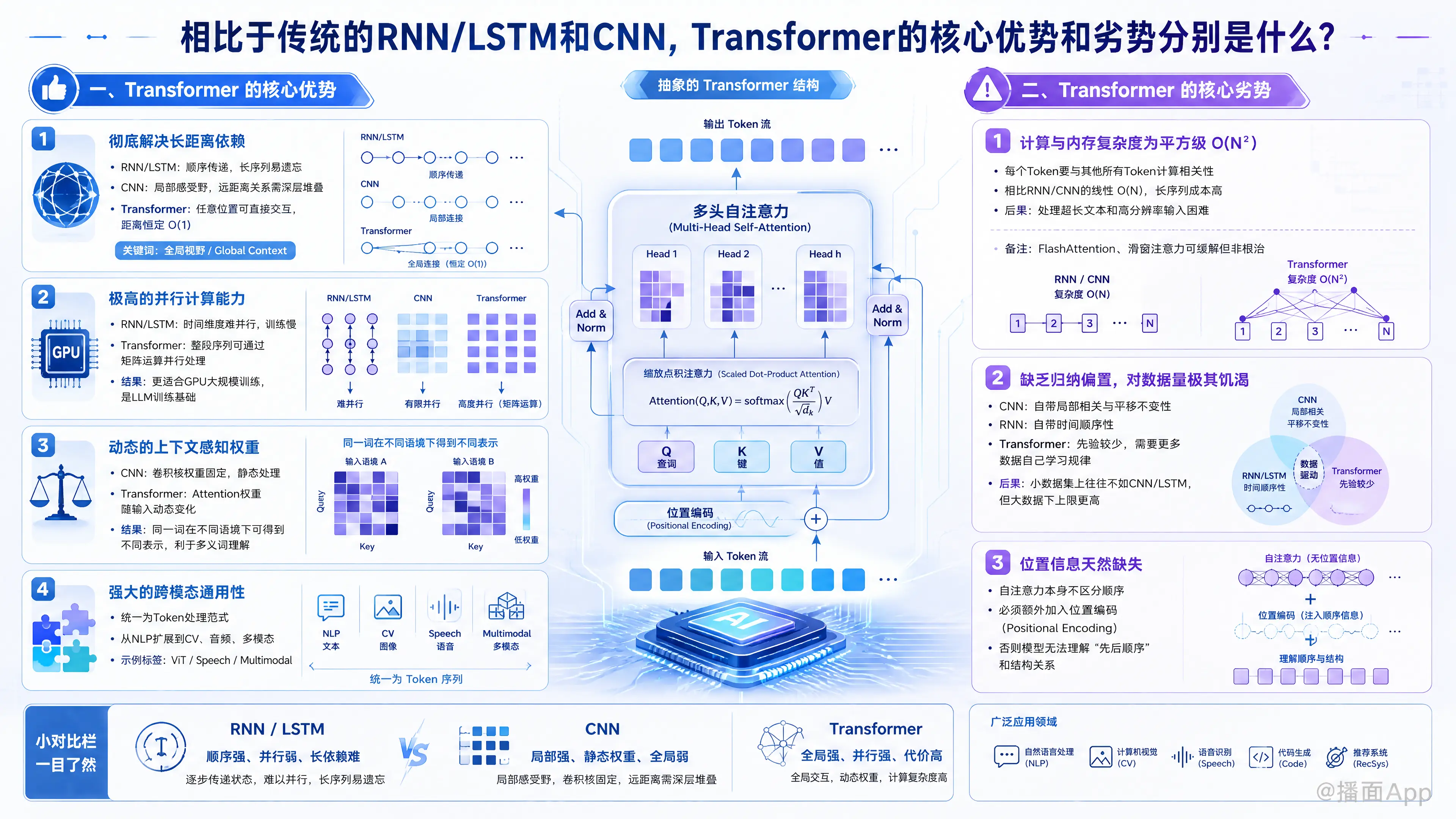
相比于传统的 RNN/LSTM 和 CNN,Transformer 凭借其核心的自注意力机制(Self-Attention),彻底改变了深度学习(尤其是自然语言处理和计算机视觉)的格局。
以下是 Transformer 相比于 RNN/LSTM 和 CNN 的核心优势与劣势的详细对比:
一、 Transformer 的核心优势
1. 彻底解决“长距离依赖”问题(相比 RNN/LSTM 和 CNN)
- RNN/LSTM 的痛点:信息是线性、顺序传递的()。即使是 LSTM 引入了门控机制,当序列很长时,早期的信息仍然会衰减或丢失(记忆瓶颈)。
- CNN 的痛点:卷积核每次只能看到局部的窗口(Local Receptive Field)。要捕捉相距较远的两个词的关系,需要堆叠非常深的卷积层。
- Transformer 的优势:自注意力机制让序列中的任意两个位置的距离恒定为 。无论两个词相隔多远,它们都可以直接进行“对话”并计算关联度,拥有真正的全局视野(Global Context)。
2. 极高的并行计算能力(主要相比 RNN/LSTM)
- RNN/LSTM 的痛点:由于必须等待前一个时间步计算完成才能计算当前步,无法在时间维度上并行,导致训练速度慢,无法充分利用现代 GPU 的强大算力。
- Transformer 的优势:在训练阶段,Transformer 不需要顺序输入。它可以通过矩阵乘法,一次性、并行地处理整个序列。这极大提升了训练效率,也是支撑当前大语言模型(LLM)能够在海量数据上训练的物理基础。
3. 动态的、上下文感知的权重(主要相比 CNN)
- CNN 的痛点:卷积核的权重在训练完成后是固定的(静态权重),无论输入什么图像或文本,同一个卷积核的操作是一样的。
- Transformer 的优势:Attention 矩阵是根据当前的输入动态计算出来的。这意味着同一个词在不同的句子中,会动态地被赋予完全不同的表示(彻底解决了多义词问题)。
4. 强大的跨模态通用性
- RNN 适合文本/时间序列,CNN 适合图像。而 Transformer 提供了一种更通用的架构(将一切视为 Token),它不仅统一了 NLP 领域,还通过 ViT(Vision Transformer)等模型成功拿下了 CV、音频、多模态等领域。
二、 Transformer 的核心劣势
1. 计算与内存复杂度呈平方级增长()
- 劣势表现:自注意力机制需要让序列中的每一个 Token 都与其它所有 Token 计算相关性。如果序列长度为 ,其计算复杂度和内存消耗就是 。
- 对比:RNN 和 CNN 的计算复杂度随序列长度是线性增长()的。
- 后果:这导致原生 Transformer 极难处理超长文本(如十万字小说、高分辨率图像像素级处理)。虽然现在有 FlashAttention、滑窗注意力等技术缓解,但仍是核心理论瓶颈。
2. 缺乏“归纳偏置”,对数据量极其饥渴
- 归纳偏置(Inductive Bias):
- CNN 天生自带“平移不变性”和“局部相关性”(它假设相邻的像素通常是相关的)。
- RNN 天生自带“时间顺序性”(它假设数据是按时间发生的)。
- 劣势表现:Transformer 初始状态下把输入看作一个“无序的词袋”,没有任何先验假设。
- 后果:在小数据集上,Transformer 的表现通常不如 CNN 或 LSTM,因为它需要依赖极其庞大的数据量自己去“暴力顿悟”出这些规律(一旦数据量够大,这个劣势反而成了上限高的优势)。
3. 位置信息的缺失
- 劣势表现:因为自注意力运算本身是不区分顺序的(把句子倒过来输入,Attention 的输出只是换了个位置,值不变),Transformer 必须显式地注入位置编码(Positional Encoding)。
- 后果:相比于 RNN 自然流淌的时间步,Transformer 处理相对位置、绝对位置的机制显得不够自然。设计优秀的位置编码(如现在的 RoPE 旋转位置编码)一直是 Transformer 优化的重点。
4. 推理阶段(Generation)的内存与速度瓶颈
- 劣势表现:虽然 Transformer 训练时可以并行,但在自回归生成(如 ChatGPT 生成回答)时,仍然需要一个词一个词地吐出。
- 后果:为了避免重复计算,必须将前面所有词的 Key 和 Value 缓存下来(即 KV Cache)。随着生成文本越来越长,KV Cache 会占用极其恐怖的显存,导致推理成本远高于传统模型。
总结:何时该用谁?
- Transformer 是当前的绝对王者,适合算力充足、数据量庞大、需要捕捉复杂全局依赖的任务(如 LLM、大规模图像生成、多模态)。
- CNN 依然是视觉特征提取、边缘设备/低算力设备上的优秀选择,其局部特征提取能力和高效性不可替代。
- RNN/LSTM 虽然在 NLP 领域被取代,但在轻量级时间序列预测、实时控制流、极其注重严格时序且数据量小的任务中,依然有其用武之地。