 播面
播面 生产环境中遇到 Kafka 消息积压(Lag 持续增大),应该如何排查和解决?
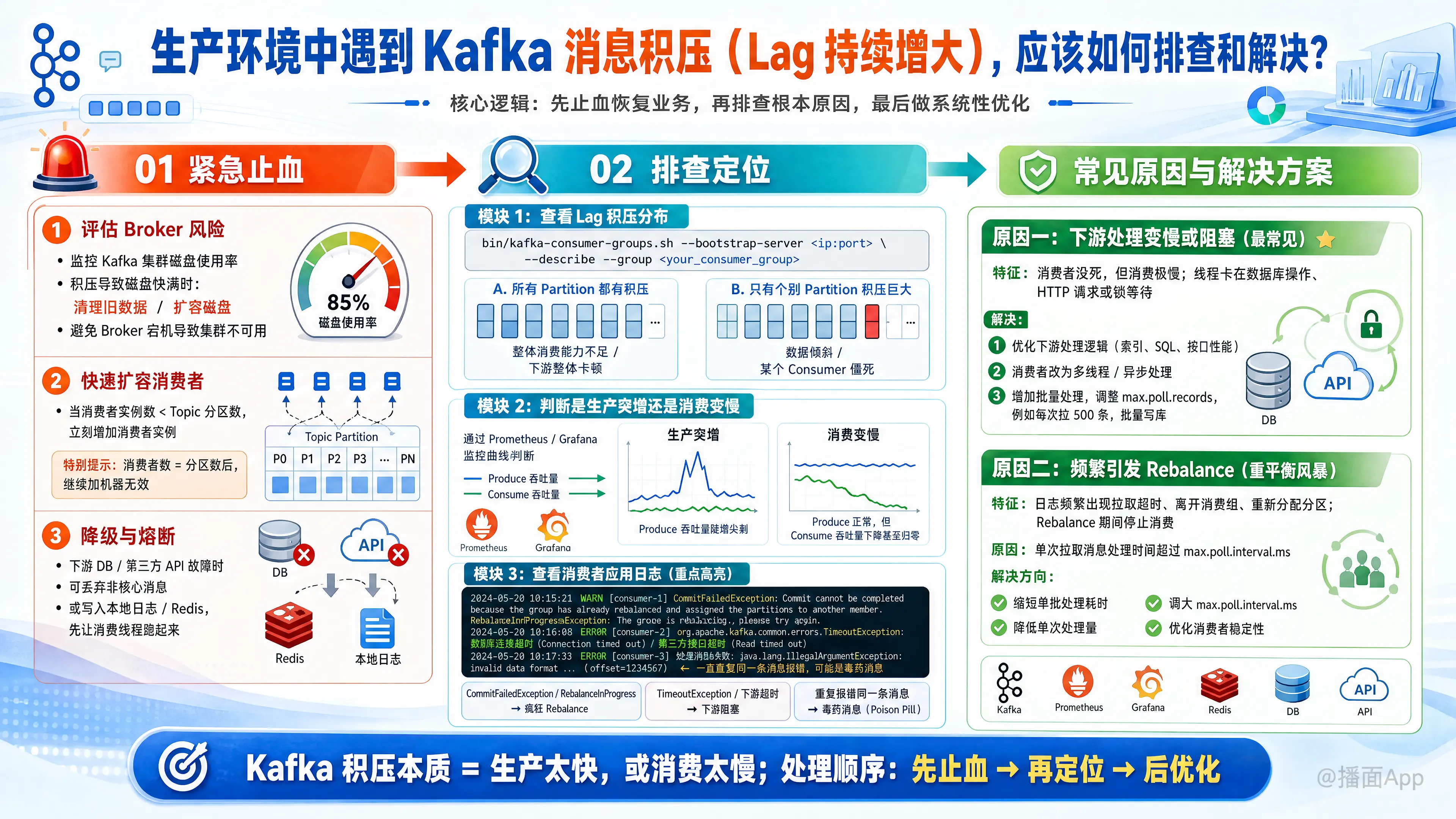
在生产环境中遇到 Kafka 消息积压(Lag 持续增大)是一个非常典型的线上故障。解决这个问题的核心逻辑是:先止血恢复业务,再排查根本原因,最后做系统性优化。
Kafka 消息积压的本质只有两个原因:生产速度突然飙升,或者 消费速度变慢/停滞。
以下是标准排查和解决全流程:
第一阶段:紧急止血(如果业务已受严重影响)
- 评估 Broker 风险:监控 Kafka 集群的磁盘使用率。如果积压导致磁盘快满了,必须立刻采取行动(如清理旧数据、扩容磁盘),否则 Broker 宕机会导致整个集群不可用。
- 快速扩容消费者:如果当前消费者实例数 < Topic 的 Partition(分区)数,立刻增加消费者实例。
- 注意:Kafka 的一个 Partition 只能被同一个 Consumer Group 中的一个 Consumer 消费。如果消费者数量已经等于分区数,继续加机器是无效的。
- 降级与熔断:如果是因为下游服务(如 DB、第三方 API)故障导致消费变慢,评估是否可以开启服务降级,直接丢弃非核心消息,或将消息写入本地日志/Redis,先让消费线程跑起来。
第二阶段:排查定位(寻找瓶颈点)
1. 查看 Lag 积压分布情况
使用 Kafka 自带脚本或可视化工具(如 Kafka-Eagle, CMAK, Grafana)查看积压情况:
bash
bin/kafka-consumer-groups.sh --bootstrap-server <ip:port> --describe --group <your_consumer_group>- 现象 A:所有 Partition 都有积压。 -> 说明整体消费能力不足,或者整体下游服务卡顿。
- 现象 B:只有个别 Partition 有巨大积压。 -> 说明存在数据倾斜(某一个特定 Key 的消息激增),或者消费那个 Partition 的特定 Consumer 僵死。
2. 判断是“生产突增”还是“消费变慢”
查看监控大盘(Prometheus/Grafana):
- 生产突增:Produce 吞吐量曲线出现陡增的尖刺。
- 消费变慢:Produce 正常,但 Consume 吞吐量下降,甚至跌零。
3. 查看消费者应用日志(最重要的一步)
去消费者所在的服务器查看日志,重点搜索以下几种报错:
CommitFailedException/RebalanceInProgress:说明消费者组在疯狂触发 Rebalance(重平衡)。这是最常见的导致积压的原因。TimeoutException/ 数据库连接超时 / 第三方接口超时:说明下游业务逻辑阻塞了消费线程。- 一直在打印同一条消息的报错:说明遇到了毒药消息(Poison Pill),导致消费逻辑无限重试,卡死了 Offset 提交。
第三阶段:常见原因与解决方案
根据排查结果,对症下药:
原因一:下游处理变慢或阻塞(最常见)
- 特征:消费者没死,但消费极慢。线程 dump 显示线程卡在数据库操作、HTTP 请求或获取锁上。
- 解决:
- 优化下游处理逻辑(加索引、优化 SQL、提升接口性能)。
- 消费者内部改用多线程/异步处理(从 Kafka 拉取消息后,丢进线程池处理,注意处理好并发下的 Offset 提交,避免丢数据)。
- 增加批量处理:调整
max.poll.records(比如每次拉 500 条),然后批量插入数据库,而不是一条条插。
原因二:频繁引发 Rebalance(重平衡风暴)
- 特征:日志中频繁出现拉取消息超时、离开消费组、重新分配分区的日志。整个 Consumer Group 在 Rebalance 期间会停止消费。
- 原因:单次拉取的消息处理时间,超过了
max.poll.interval.ms的配置值。Kafka 误以为该消费者挂了,将其踢出集群。 - 解决:
- 减小单次拉取数量:调低
max.poll.records(例如从 500 降到 100)。 - 增加处理超时时间:调大
max.poll.interval.ms(默认 5 分钟,可以调大到 10 分钟或更高)。 - 检查心跳:确保
session.timeout.ms和heartbeat.interval.ms设置合理(通常 heartbeat 是 session 的 1/3)。
- 减小单次拉取数量:调低
原因三:遇到“毒药消息”(Poison Pill)
- 特征:某条坏数据导致代码抛出未捕获异常,业务框架(如 Spring Kafka)默认开启无限重试,导致一直卡在这条消息上。
- 解决:
- 代码中加入
try-catch包裹消费逻辑。 - 引入 死信队列 (DLQ, Dead Letter Queue):重试 3 次失败后,将消息转发到专门的 DLQ Topic,然后当前消费者提交 Offset 并继续处理下一条。人工后续介入处理 DLQ 中的脏数据。
- 代码中加入
原因四:消费者数量达到了分区数瓶颈
- 特征:消费者机器 CPU、内存都满负荷了,但积压依然在增加。并且 消费者数量 == Partition 数量,无法再通过加机器扩容。
- 解决:
- 终极方案:同时增加 Kafka Topic 的 Partition 数量,并增加 Consumer 实例数。(注意:改变分区数可能会影响根据 Key 保证顺序的业务逻辑)。
- 临时方案(二级转发):原消费者什么都不干,只负责把消息拉下来,立刻转发给另外一个拥有几十个分区的“临时 Topic”,然后由一个庞大的新消费组去消费临时 Topic。
原因五:数据倾斜
- 特征:某个特定的 Partition 积压几百万,其他 Partition 正常。
- 解决:
- 检查 Producer 端的发送逻辑,是否对同一个 Key 发送了过多的数据(热点 Key 问题)。
- 如果不需要严格保证局部顺序,可以修改 Producer 发送策略,改用轮询(Round-Robin)随机发送。
第四阶段:预防与最佳实践(复盘改造)
解决问题后,为了防止再次发生,需要做以下建设:
- 完善监控与告警:
- 监控 Consumer Lag,设置合理的阈值告警(如 Lag 超过 5万,或持续增长超过 5 分钟触发电话告警)。
- 监控 Consumer Group 的存活实例数。
- 消费端熔断降级机制:
- 消费端调用外部 RPC 必须设置 Timeout 超时时间,严禁无限等待。
- 标配死信队列 (DLQ):
- 严禁在主消费线程中死磕“坏数据”。
- 压测与容量规划:
- 上线前压测消费者的极限 TPS,根据线上峰值流量(甚至按峰值的 2-3 倍)提前规划好 Partition 数量。通常 Partition 的数量建议至少是预估消费者数量的 2 到 3 倍。
- 消费逻辑幂等性:
- 消费代码必须保证幂等(通过数据库唯一索引、Redis 防重 Token 等),这样在遇到积压、重平衡等问题时,可以放心大胆地重启、重推数据而不怕数据重复。