 播面
播面 消费者的 max.poll.records 和 max.poll.interval.ms 参数的作用是什么?
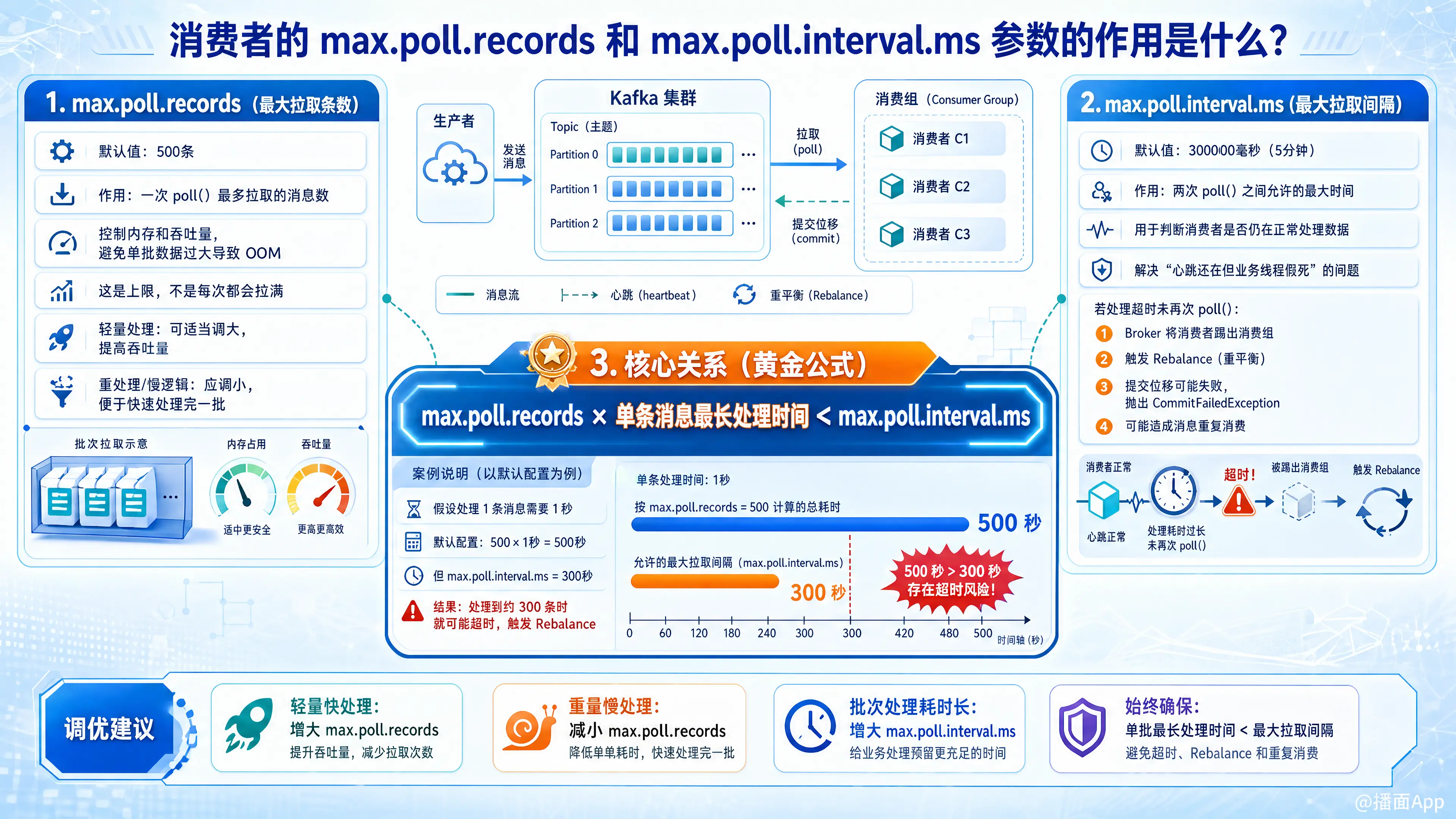
在 Kafka 消费者(Consumer)配置中,max.poll.records 和 max.poll.interval.ms 是两个非常核心的参数。它们共同决定了消费者的处理能力、系统吞吐量以及集群的稳定性(避免不必要的 Rebalance)。
下面为你详细解释这两个参数的作用及它们之间的关系:
1. max.poll.records(最大拉取条数)
- 默认值: 500(条)
- 作用:
控制消费者在一次poll()方法调用中,最多能从 Kafka Broker 拉取到的消息记录数。 - 详细解析:
- 控制内存和吞吐量: 它限制了应用程序一次需要处理的数据量。如果单条消息非常大,或者消费者的处理逻辑非常占用内存,调小这个值可以防止消费者发生 OOM(内存溢出)。
- 并非每次都拉满: 这是一个“上限”值。如果 Broker 当前只有 10 条消息,即使你配置了 500,
poll()也会立即返回这 10 条消息,而不会一直干等。
- 如何调优:
- 如果你的处理逻辑非常轻量、快速(例如只是将数据写入 Redis 或内存计算),可以适当调大该值,以减少网络请求次数,提高吞吐量。
- 如果你的处理逻辑非常重、耗时(例如需要请求外部慢 API、复杂的数据库事务),应该调小该值,以确保能快速处理完这一批数据。
2. max.poll.interval.ms(最大拉取间隔)
- 默认值: 300,000 毫秒(即 5 分钟)
- 作用:
规定了消费者两次调用poll()方法之间的最大允许时间间隔。它被用来判断消费者是否还在正常处理数据(即“处理线程”的存活状态)。 - 详细解析:
- 防假死机制: 在 Kafka 0.10.1.0 版本之后,心跳(Heartbeat)由后台独立的线程发送(受
session.timeout.ms控制)。这意味着即使你的业务代码死锁了,心跳照常发送,Broker 依然认为消费者活着。为了解决这种“假死”问题,引入了max.poll.interval.ms。 - 超时后果(非常严重): 如果消费者拉取了一批消息,但处理这批消息的时间超过了
max.poll.interval.ms,还没有发起下一次poll()请求,Kafka Broker 就会认为这个消费者已经“死掉”或“卡住”了。 - 接着会发生什么?
- Broker 会主动把这个消费者踢出消费组(Consumer Group)。
- 触发消费组的 Rebalance(重平衡),将该消费者负责的分区分配给其他消费者。
- 当原消费者终于处理完数据准备提交位移(Commit Offset)时,会抛出
CommitFailedException异常,因为它的分区已经被别人接管了。这通常会导致消息被重复消费。
- 防假死机制: 在 Kafka 0.10.1.0 版本之后,心跳(Heartbeat)由后台独立的线程发送(受
- 如何调优:
- 评估你的最长处理时间。如果你确实需要很长时间来处理一批消息,必须调大这个值。
3. 核心:这两个参数的“黄金关系”
这两个参数不是孤立的,它们之间必须满足一个严格的数学关系,才能保证消费者稳定运行:
max.poll.records× 单条消息的最长处理时间 <max.poll.interval.ms
场景举例:
假设你的消费者处理一条消息需要 1 秒钟(1000 ms)。
- 如果你保持默认配置(
max.poll.records = 500,max.poll.interval.ms = 300000):
处理完 500 条消息需要 500 秒。但是你的最大拉取间隔是 300 秒。 - 结果: 每次消费到第 300 条左右时,就会发生超时,触发 Rebalance,抛出异常,然后重复消费……系统陷入崩溃死循环。
解决方案:
面对上面的问题,你有三种选择:
- 减小
max.poll.records: 把每次拉取的条数降到 200 条。这样 200秒就能处理完,小于 300秒的限制。 - 增大
max.poll.interval.ms: 把超时时间设为 600000(10分钟)。这样 500秒的处理时间就在允许范围内了。 - 优化业务代码/引入异步处理: 提升单条消息的处理速度,或者将耗时的处理逻辑放入另外的线程池中异步执行(注意异步情况下的位移提交管理会变得复杂)。
总结
max.poll.records:控制每次吃多少(饭量)。max.poll.interval.ms:要求多久必须吃完(就餐限时)。- 调优目标:确保你的消费者能在“就餐限时”内,稳稳当当地把这碗饭“吃完”,否则就会被赶出餐厅(Rebalance)。