 播面
播面 如何处理 Kafka生产者发送消息时出现的 TimeoutException 或网络瞬断异常?
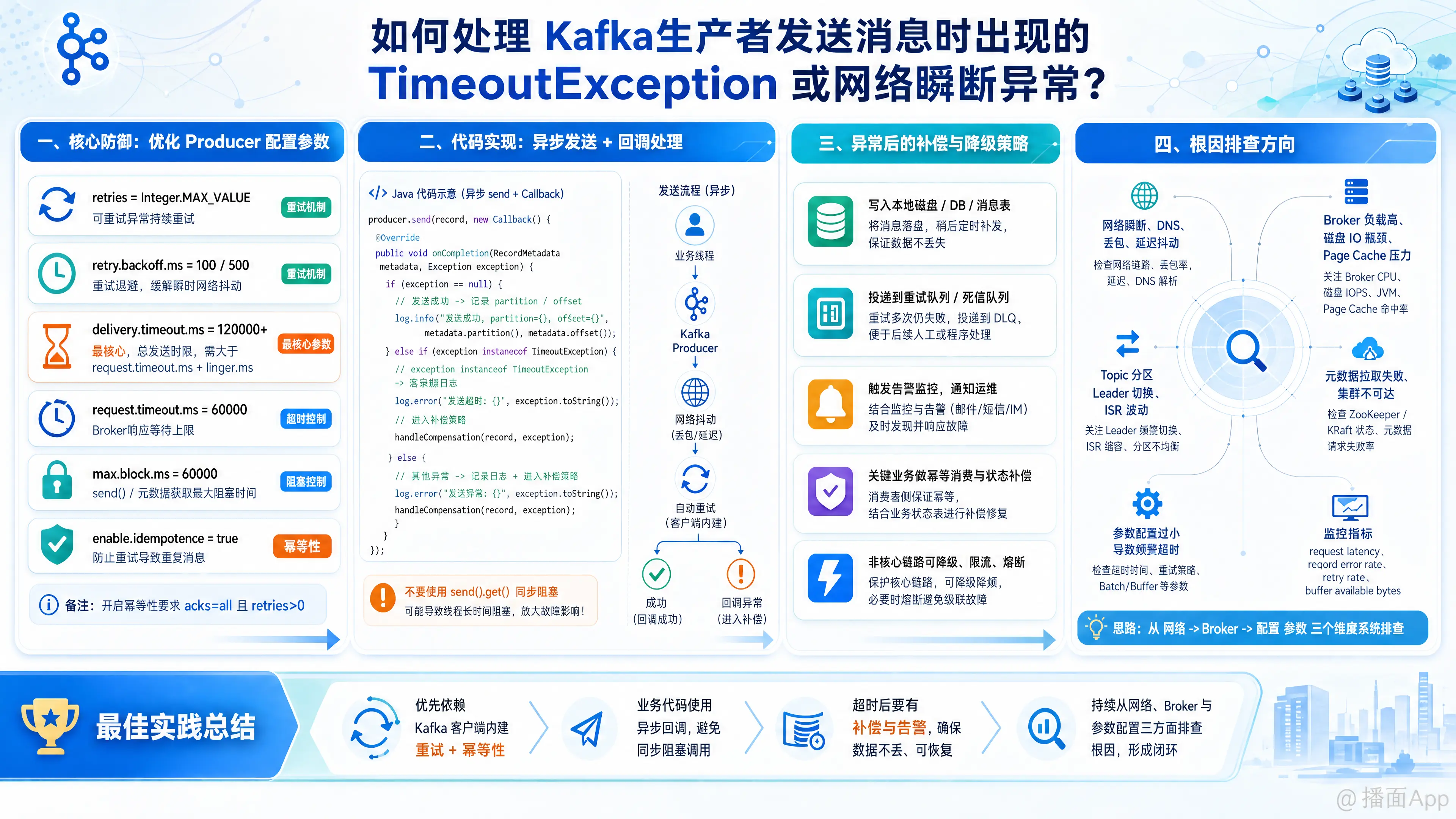
处理 Kafka 生产者在发送消息时遇到的 TimeoutException 或网络瞬断异常,是构建高可用分布式系统的常见挑战。解决这类问题通常需要从客户端配置优化、代码层面的异常捕获与重试、降级/补偿策略以及排查根本原因四个维度来综合处理。
以下是标准的处理指南和最佳实践:
一、 核心防御:优化 Producer 配置参数
Kafka 客户端内置了非常强大的重试机制,应对网络瞬断最好的方法是让 Kafka 客户端自己去重试,而不是在业务代码里写 while(true)。
建议调整以下关键配置(基于 Kafka 2.1及以上版本):
开启重试(应对网络瞬断最有效)
retries: 设置为Integer.MAX_VALUE(默认就是这个)。让客户端在遇到可重试异常时一直重试。retry.backoff.ms: 设置为100或500(默认 100ms)。每次重试之间的退避时间,如果是网络偶尔抖动,稍微拉长一点退避时间效果更好。
配置合理的超时时间(防止无休止的等待)
delivery.timeout.ms: (最核心参数) 消息从发送到最终成功或失败的总时间上限。建议设置为120000(2分钟) 或更大。它必须大于request.timeout.ms+linger.ms。如果超过这个时间还没发成功,就会抛出TimeoutException。request.timeout.ms: 客户端等待 Broker 响应的最大时间(默认 30000ms / 30秒)。如果网络延迟大或 Broker 负载高,可以适当调大到60000。max.block.ms: 调用send()方法或获取元数据时的最大阻塞时间(默认 60000ms / 60秒)。如果 Kafka 彻底连不上,send()会阻塞这么久然后抛出TimeoutException。
开启幂等性(防止重试导致消息重复)
enable.idempotence: 务必设置为true。开启后,即使因为网络瞬断导致客户端进行了重试,Broker 端也能保证消息不重复。- 注意:开启此项要求
acks=all且retries > 0。
二、 代码实现:异步发送与回调处理
千万不要使用同步阻塞发送(即 producer.send(record).get()),这会极大地降低吞吐量,并且在网络抖动时直接卡死业务线程。应使用异步发送 + 回调函数。
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// 发送成功
System.out.println("Message sent successfully to partition " + metadata.partition());
} else {
// 发生异常
if (exception instanceof TimeoutException) {
log.error("Kafka发送超时 (可能是网络瞬断或Broker繁忙): {}", exception.getMessage());
// 执行补偿策略(见第三部分)
handleFailedMessage(record);
} else if (exception instanceof RetriableException) {
// 理论上客户端会自动重试,如果走到这里说明超过了 delivery.timeout.ms
log.error("可重试异常最终失败: {}", exception.getMessage());
handleFailedMessage(record);
} else {
// 不可重试异常 (如 AuthException, RecordTooLargeException)
log.error("不可恢复的Kafka异常: {}", exception.getMessage());
// 记录日志或告警
}
}
}
});三、 兜底方案:失败消息的补偿与降级策略
如果在客户端用尽了 delivery.timeout.ms 指定的时间(比如重试了2分钟)依然失败,就会进入回调函数的 else 分支。此时业务不能丢数据,必须有兜底机制:
写入本地日志 / 降级文件 (最简单)
将失败的消息按特定格式使用 Log4j/Logback 打印到单独的kafka-fail.log文件中。后续通过 Filebeat 或定时脚本把数据捞回来重新发送。本地死信队列 / 内存缓存 (适用于轻量级应用)
把失败的 record 放入内存队列(如LinkedBlockingQueue),后台开一个单线程定时尝试重发。
缺点:应用重启会丢失内存中的数据。落库重试机制 (Outbox Pattern / 消息表)
将失败的消息存入关系型数据库(MySQL/PostgreSQL)的本地消息表中,状态标记为“待发送”。后台定时任务扫描该表并重新发送至 Kafka,发送成功后更改状态为“已发送”。这是金融级最稳妥的做法。
四、 根因排查:为什么会频繁超时?
如果偶尔出现一次 TimeoutException 是正常的(网络抖动),但如果频繁出现,通常是以下原因,需要针对性排查:
Broker 负载过高 (最常见)
- 现象:Kafka 集群 CPU 打满、磁盘 IO 瓶颈、或者 Broker 正在发生长时间的 JVM Full GC。导致无法及时返回 ACK。
- 排查:查看 Kafka Broker 的监控(Grafana),特别是
RequestHandlerAvgIdlePercent(处理线程空闲率)和NetworkProcessorAvgIdlePercent。
客户端缓冲池满了
- 现象:业务生产速度远大于发送网络速度,导致 Producer 的
buffer.memory(默认32MB)被填满。后续的send()调用会被阻塞,超过max.block.ms后抛出超时异常。 - 解决:增加
buffer.memory,或者排查为什么发送这么慢(网络带宽限制?)。
- 现象:业务生产速度远大于发送网络速度,导致 Producer 的
元数据获取失败
- 现象:网络防火墙拦截,或者 Broker 配置的
advertised.listenersIP 客户端无法访问。导致客户端获取不到 Topic 的 Leader 节点信息,阻塞直到超时。 - 排查:在生产端机器上
telnet <kafka-broker-ip> 9092测试网络连通性。
- 现象:网络防火墙拦截,或者 Broker 配置的
总结建议
- 将
acks设为all,enable.idempotence设为true,利用 Kafka 原生的重试机制抵御网络瞬断。 - 调大
delivery.timeout.ms,给网络恢复留出时间。 - 务必使用异步 Callback 处理发送结果,避免阻塞主业务流程。
- 在 Callback 中捕获
TimeoutException,并将消息写入数据库或本地日志作为最终的补偿方案,确保数据零丢失。