 播面
播面 讲讲Kafkar的消费者重平衡(Rebalance)及其过程
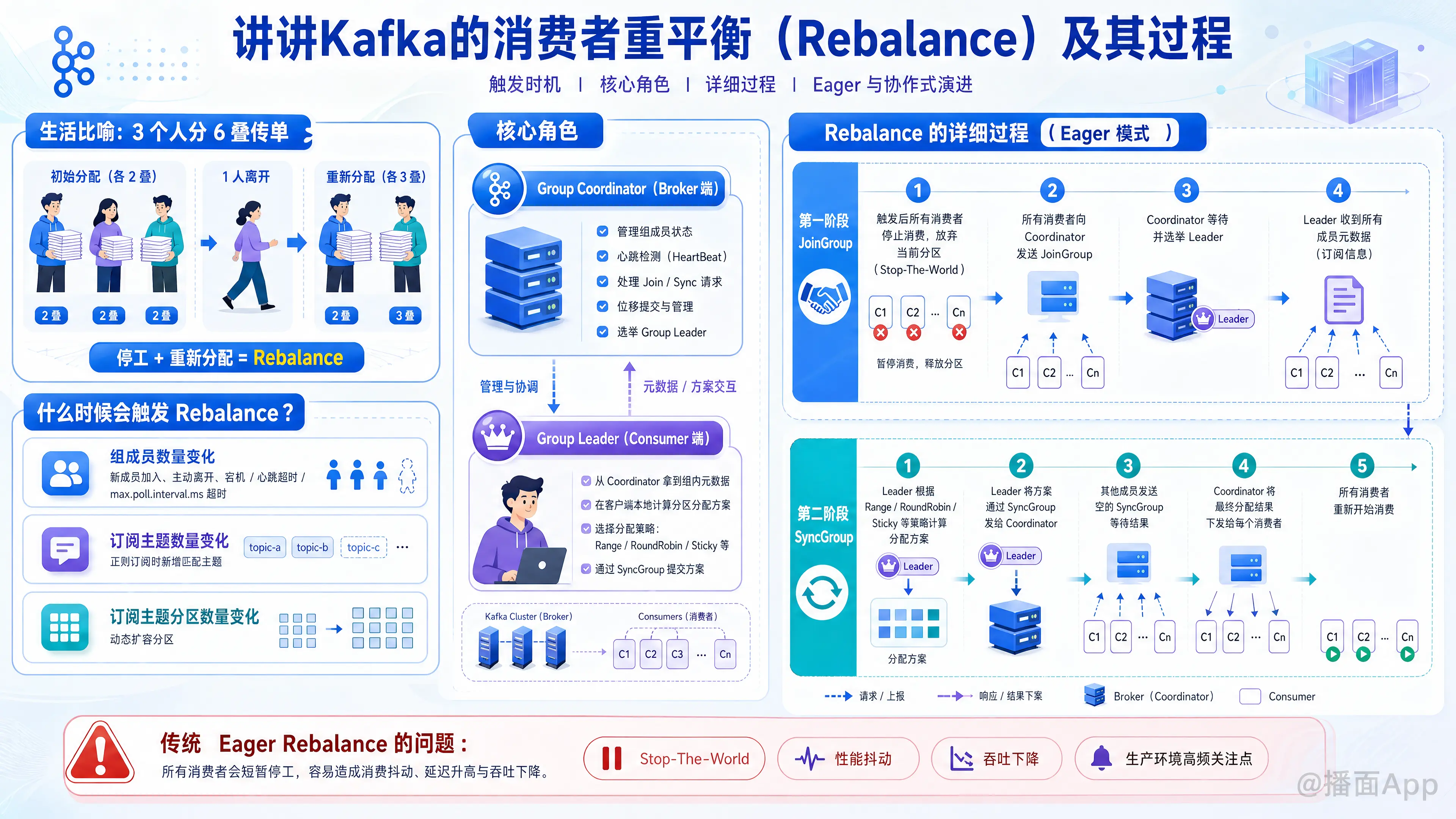
在 Kafka 中,重平衡(Rebalance)是消费者端最核心、最复杂,同时也是在生产环境中经常引发性能问题的一个机制。
简单来说,重平衡就是 Kafka 规定一个消费者组(Consumer Group)下的所有消费者,如何达成一致来分配订阅主题下每个分区的过程。
打个比方:假设有一个小组(消费者组)在分发传单(分区里的消息)。一开始有 3 个人分 6 叠传单,每人 2 叠。突然有 1 个人请假了,剩下的 2 个人必须停下手头的工作,重新分配这 6 叠传单(每人 3 叠),这个“停工+重新分配”的过程就是 Rebalance。
下面为你详细拆解 Kafka 消费者重平衡的触发时机、核心角色、详细过程以及它的演进。
一、 什么时候会触发 Rebalance?
Rebalance 不会无缘无故发生,通常由以下三种情况触发:
- 组成员数量发生变化(最常见)
- 新成员加入: 新启动了一个消费者实例。
- 成员主动离开: 消费者实例正常关闭。
- 成员崩溃/被踢出: 消费者实例发生宕机,或者处理消息的时间太长(超过了
max.poll.interval.ms),或者心跳超时(超过了session.timeout.ms),被 Kafka 认为已经挂掉。
- 订阅的主题数量发生变化
- 消费者组使用正则表达式订阅主题(例如
test-*),当新建了一个匹配该正则的主题时。
- 消费者组使用正则表达式订阅主题(例如
- 订阅主题的分区数量发生变化
- 管理员使用命令行工具动态增加了某个主题的分区数。
二、 Rebalance 中的核心角色
在了解过程之前,必须明确两个关键角色:
- Group Coordinator(组协调者): 位于 Broker 端。每个消费者组都会被分配给一个特定的 Broker 作为 Coordinator,负责管理组内成员的状态、心跳检测以及位移提交。
- Group Leader(组长): 位于 Consumer 端。它是消费者组内的某一个消费者实例(通常是第一个加入组的消费者)。Kafka 将具体的分区分配逻辑放在了客户端的 Leader 身上,而不是 Broker 端,这样做是为了解耦,支持客户端自定义分配策略。
三、 Rebalance 的详细过程
传统的 Rebalance 过程(Eager 模式)主要分为两个核心阶段,对应两个 Kafka 协议请求:JoinGroup 和 SyncGroup。
第一阶段:加入组(JoinGroup)
- 挂起消费: 一旦触发 Rebalance,组内所有的消费者会立即停止消费,并放弃当前拥有的所有分区(这就是所谓的 Stop-The-World)。
- 发送请求: 所有消费者向 Group Coordinator 发送
JoinGroup请求,申请加入消费者组。 - 选举 Leader 并收集信息: Coordinator 收到请求后,会等待一段时间(让尽量多的消费者赶来),然后从申请者中选出一个消费者作为 Group Leader。
- 下发元数据: Coordinator 响应所有消费者的
JoinGroup请求。对于普通成员,只告诉它“加入成功”;但对于 Leader,Coordinator 会把组内所有成员的元数据(包含大家各自订阅了什么)都发给它。
第二阶段:同步组(SyncGroup)
- Leader 计算分配方案: Leader 拿到所有成员的信息后,根据配置的分配策略(如 Range、RoundRobin、Sticky 等),在本地计算出“谁应该消费哪个分区”的最终方案。
- 发送方案: Leader 将计算好的分配方案封装在
SyncGroup请求中,发给 Coordinator。同时,其他普通消费者也会发送空的SyncGroup请求给 Coordinator(为了等待结果)。 - 分发方案: Coordinator 收到 Leader 的分配方案后,把具体的分配结果塞进
SyncGroup的响应中,发给对应的各个消费者。 - 恢复消费: 所有消费者收到自己最新的分配结果,重新开始拉取消息并消费。Rebalance 结束。
四、 消费者分配策略(Partition Assignors)
在上述 SyncGroup 阶段,Leader 计算分配方案时会用到分配策略。Kafka 提供了几种常见的策略:
- RangeAssignor(默认): 按主题划分。把主题的若干分区按数字排序,消费者按字典序排序。前面的消费者分到前面的分区。(容易造成前面的消费者负载过重,即数据倾斜)。
- RoundRobinAssignor: 轮询分配。把所有主题的所有分区列出来,依次发给每个消费者。
- StickyAssignor(粘性分配): 两个原则:1. 分配尽量均匀;2. 在发生 Rebalance 时,尽量保持原有的分配不改变。这能大大减少分区的转移开销。
五、 Rebalance 带来的问题(Stop-The-World)
传统的 Rebalance 机制(Eager Rebalance)被称为“简单粗暴”,因为它会带来严重的性能问题:
- Stop-The-World(STW): 在 Rebalance 期间,所有消费者必须停下手中的工作,交出所有分区。如果组内消费者很多,这个过程可能长达数秒甚至数分钟。这期间整个消费者组处于不可用状态,导致消息积压、消费延迟飙升。
- 重复消费: 消费者被强行剥夺分区时,如果有些已经处理完的消息还没来得及提交 Offset,Rebalance 结束后该分区被分配给别的消费者,这部分消息就会被重新消费一次。
六、 Kafka 的演进:增量协同重平衡(Cooperative Rebalance)
为了解决 STW 问题,Kafka 在 2.4 版本引入了 Cooperative Sticky Assignor(增量协同重平衡)。
它的核心思想是:不要一次性收回所有分区,而是进行多次小规模的 Rebalance。
改进后的过程简述:
- 第一次 Rebalance: 消费者不再交出当前正在消费的分区,而是带着自己现有的分区去发送
JoinGroup。Leader 计算出新方案后,发现有些分区需要从 A 转移到 B。Leader 不会直接把分区给 B,而是告诉 A:“请把你多出来的分区交还回来”。此时 A、B 依然可以正常消费自己合法拥有的分区。 - 第二次 Rebalance: A 将多出的分区交还(撤销操作)。此时这些被交还的分区处于无主状态。大家再次
JoinGroup,Leader 将这些无主分区正式分配给 B。
结果: 整个过程中,只有真正需要发生转移的分区所在的消费者会经历短暂的停顿,其他不需要改变分区的消费者全程不会中断消费。这极大地平滑了系统性能,消除了 STW 带来的延迟毛刺。
七、 生产环境如何避免不必要的 Rebalance?
在实际开发中,正常的新增/下线节点引发的 Rebalance 是不可避免的,但我们要尽量避免因为参数配置不当导致的异常 Rebalance。通常需要调整以下参数:
session.timeout.ms和heartbeat.interval.ms:
心跳超时时间。如果 Broker 太久没收到心跳,就会认为消费者挂了。
建议:heartbeat.interval.ms设为session.timeout.ms的三分之一。例如心跳 3 秒,超时 10 秒。max.poll.interval.ms:
两次poll()方法调用的最大间隔。如果你处理消息的业务逻辑太重、太耗时,超过了这个时间还没去拉取下一批消息,Kafka 会认为消费者陷入了死锁,主动将其踢出组引发 Rebalance。
建议: 评估业务逻辑耗时,适当调大该值;或者将耗时的业务逻辑放入异步线程池处理,保持主线程快速poll()(但要注意异步处理时的 Offset 提交管理)。max.poll.records:
每次拉取的最大消息数。如果处理慢,可以减小这个值,确保能在max.poll.interval.ms内处理完。
总结来说,理解 Rebalance 机制能帮助你在 Kafka 出现消费停滞、延迟突增或重复消费时,快速定位是否是因为频繁 Rebalance 引起的,并针对性地调优。