 播面
播面 什么是 Kafka 数据截断(Truncation)机制?在什么情况下会发生?
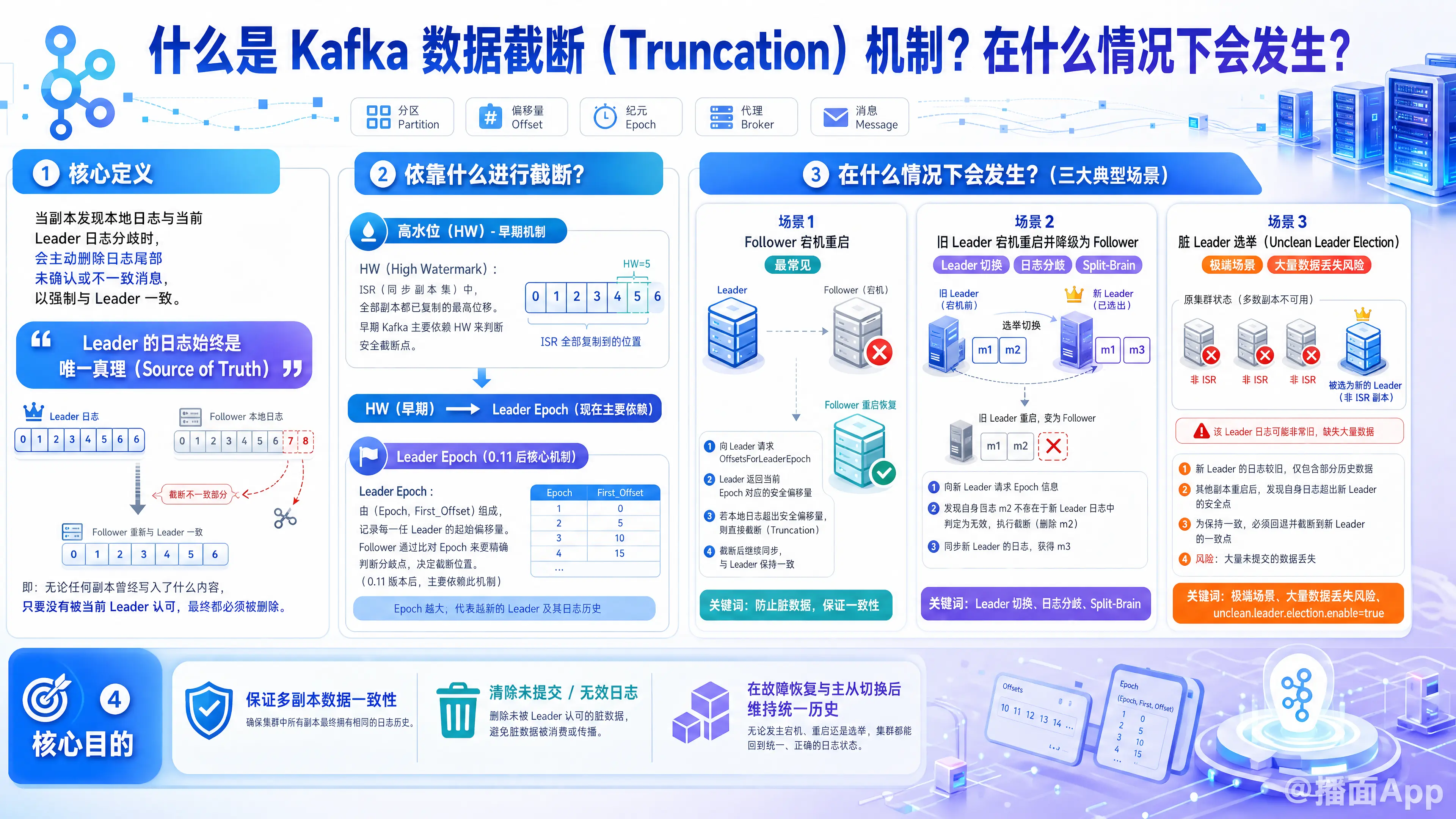
在 Kafka 中,数据截断(Data Truncation)是 Kafka 为了保证多副本之间数据一致性而采取的一种核心容错机制。
简单来说,数据截断是指:当副本(Replica)发现自己的本地日志(Log)与当前 Leader 的日志出现分歧时,它会主动删除(截断)自己日志尾部那些未被确认或与 Leader 不一致的消息,以强制和当前的 Leader 保持一致。
在 Kafka 中,Leader 的日志始终被视为“唯一真理(Source of Truth)”。
以下是关于数据截断机制的详细解析以及它发生的具体场景:
一、 核心概念:依靠什么进行截断?
在了解场景之前,需要知道 Kafka 是如何判断“该从哪里截断”的:
- 高水位(High Watermark, HW):
HW 表示该分区中所有处于 ISR(同步副本集合)中的副本都已成功复制的最高位移。在 Kafka 0.11 版本之前,副本主要依靠 HW 来进行数据截断。 - Leader Epoch(领导者纪元):
由于单纯依靠 HW 截断在某些极端宕机场景下会导致数据丢失或副本数据不一致,Kafka 从 0.11 版本引入了Leader Epoch。它由一对值组成:(Epoch, First_Offset),即(Leader的任期号,该任期写入的第一条消息的位移)。现在的 Kafka 主要通过 Follower 与 Leader 交换 Leader Epoch 信息来决定精确的截断点。
二、 在什么情况下会发生数据截断?
数据截断通常发生在Broker 宕机重启或Leader 发生切换的场景下。具体包括以下几种典型情况:
场景 1:Follower 宕机重启(最常见)
当一个 Follower 节点崩溃并重新启动时,它本地的日志可能包含了一些尚未被整个集群提交(即大于本地 HW 或 Leader Epoch 指定位移)的数据。
- 过程: Follower 恢复后,不会立刻开始向 Leader 拉取数据。它会先向当前的 Leader 发送请求(
OffsetsForLeaderEpoch),询问自己最后一个 Epoch 在 Leader 端的最高偏移量。 - 截断: 如果 Follower 发现自己本地的最新消息超出了 Leader 返回的安全偏移量,它就会将超出的部分直接截断(删除),然后再开始从 Leader 同步数据。
- 目的:防止 Follower 包含了未被最终确认的脏数据。
场景 2:旧 Leader 宕机重启并降级为 Follower
这是多副本架构中最典型的“分歧”场景。
- 背景: 假设 Broker A 是 Leader,接收了消息
m1和m2。m1同步给了 Follower,但m2还没来得及同步,Broker A 就宕机了。 - Leader 切换: Broker B 成为新的 Leader。B 继续接收客户端的新消息
m3。此时,全局数据没有m2。 - 发生截断: 当旧 Leader(Broker A)重启后,它会变成 Follower。它本地有
m1和m2,但现任 Leader (B) 是m1和m3。为了保持一致,A 会向 B 请求最新的 Leader Epoch 信息,发现m2是无效分歧数据。 - 结果: Broker A 会将
m2截断,然后从 B 同步m3。 - 目的:解决主备切换导致的历史日志分歧(Split-Brain 现象)。
场景 3:脏 Leader 选举(Unclean Leader Election)
这是一种极端且会导致大量数据丢失的场景。
- 背景: 当参数
unclean.leader.election.enable=true时,如果 ISR(同步副本组)中的所有副本都宕机了,Kafka 允许从非 ISR(落后很多)的副本中选出一个新的 Leader,以保证集群的可用性。 - 发生截断: 假设 落后副本 C 当选了新 Leader。随后,原本拥有最新数据的 A 和 B 重启了。由于 C 现在是 Leader,C 的日志就是绝对真理。
- 结果: A 和 B 会被迫进行大规模的数据截断,把它们比 C 多出来的那部分(其实是原本已经提交的有效数据)全部删除,以强行与 C 保持一致。
- 目的:为了牺牲数据一致性(丢失数据)来换取集群的高可用性。
三、 总结:截断的本质是什么?
- 一致性 > 保留所有数据: Kafka 在多副本复制中,宁可删掉 Follower 尾部未达成共识的数据,也绝不允许不同的副本拥有不同内容的历史记录。
- Leader 是绝对权威: 所有的截断动作,都是 Follower 为了向现任 Leader “看齐” 而做出的妥协。
- Leader Epoch 的重要性: 现代 Kafka 依靠 Leader Epoch 机制,使得数据截断变得极其精准,彻底解决了旧版本中单纯依赖高水位(HW)可能导致的数据无故截断或数据发散(Divergence)的 Bug(即著名的 KIP-101 提案解决的问题)。