 播面
播面 生产者的重试机制(Retries)底层是如何工作的?
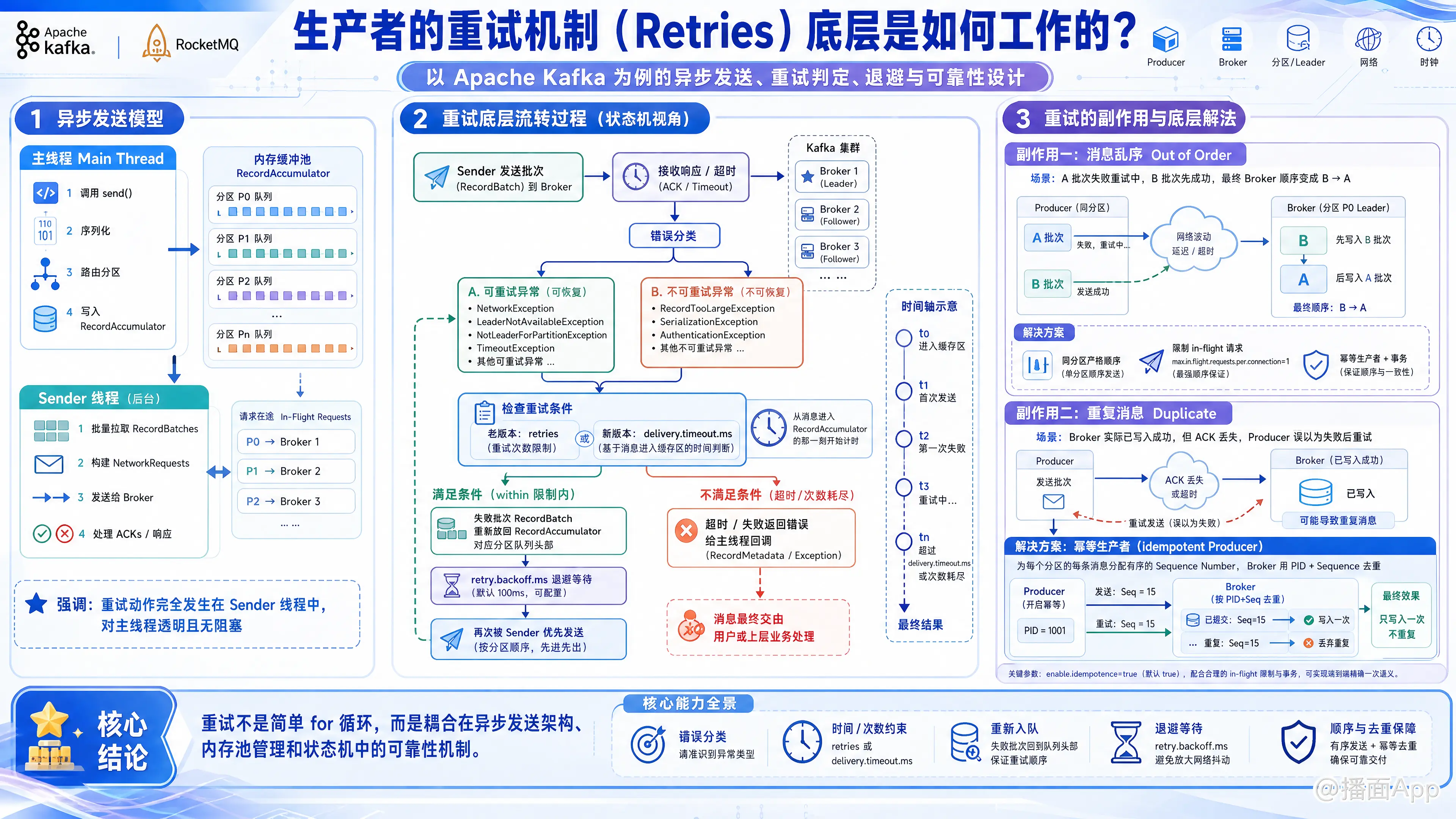
在分布式消息队列(以业界最典型的 Apache Kafka 为例,RocketMQ 等也有类似机制)中,生产者的重试机制(Retries)是保证消息可靠性的核心设计。
它的底层工作原理并非简单地“用个 for 循环重新发一次”,而是深度耦合在生产者的异步发送架构、内存池管理以及状态机之中的。
以下是生产者重试机制底层工作原理的深度解析:
一、 底层架构基础:异步发送模型
要理解重试,首先要了解生产者的内部架构。生产者通常分为两个线程:
- 主线程(Main Thread): 负责调用
send()方法,将消息序列化、路由后,放入内存缓存区(RecordAccumulator)。 - Sender 线程(后台 I/O 线程): 负责从缓存区中批量拉取消息(Batches),构建网络请求(NetworkRequests)发送给 Broker,并处理响应(ACKs)。
重试动作完全发生在 Sender 线程中,对主线程是透明且无阻塞的(除非缓存区被打满)。
二、 重试的底层流转过程
当 Sender 线程将一批消息发送给 Broker 后,底层会按照以下步骤决定是否重试:
1. 接收响应与错误分类
Broker 响应请求或发生网络超时后,Sender 线程会解析结果。如果发生异常,底层会对异常进行严格分类:
- 可重试异常(Transient Errors): 认为是瞬时的网络抖动或集群状态变化。例如:
NetworkException(网络连接断开)LeaderNotAvailableException(正在进行 Leader 选举)NotLeaderForPartitionException(Leader 已经切换,路由缓存过期)TimeoutException(请求超时)
- 不可重试异常(Fatal Errors): 认为是配置错误或数据本身的问题,重试多少次都没用。例如:
RecordTooLargeException(消息体积超过 Broker 限制)SerializationException(序列化失败)AuthenticationException(认证失败)
2. 检查重试条件
如果判定为“可重试异常”,底层会继续检查是否满足重试的配置条件:
- 在老版本 Kafka 中:主要检查
retries参数(最大重试次数,默认 0,现推荐设为Integer.MAX_VALUE)。 - 在新版本 Kafka 中(Kafka 2.1+):引入了基于时间的重试机制
delivery.timeout.ms(默认 2 分钟)。底层会计算:当前时间 - 消息进入缓存区的时间。如果超过了这个超时时间,即使没达到最大重试次数,也会直接抛弃并报错。
3. 重新入队(Re-enqueue)
如果满足重试条件,Sender 线程不会立即发起网络请求,而是将失败的这个批次(RecordBatch)重新放回 RecordAccumulator(缓存区)对应分区的队列头部(保证它下一次优先被发送)。
4. 退避等待(Backoff)
为了防止在 Leader 选举期间疯狂重试导致 Broker 乃至网络雪崩,底层会触发退避机制。
重试的批次会处于锁定状态,等待 retry.backoff.ms(默认 100ms)。时间一到,Sender 线程才会再次将其打包发送。
三、 重试带来的副作用及其底层解决方案
重试机制虽然提高了可靠性,但在分布式系统中必然引入两个极其棘手的副作用。消息队列底层针对这两个问题有精妙的设计。
1. 副作用一:消息乱序 (Out of Order)
场景: 批次 A 发送失败,正在重试(Backoff 中)。此时 Sender 线程把批次 B 发送出去了且成功。随后批次 A 重试成功。此时 Broker 端接收的顺序变成了 B -> A。
底层解决方案:
- 控制飞行中的请求数: 通过参数
max.in.flight.requests.per.connection(每个连接最多缓存的未响应请求数)。 - 如果设为
1:A 失败没收到 ACK,B 根本不被允许发送,严格保证顺序,但吞吐量极低。 - 现代方案(幂等性开启状态下): 即使该参数设为
5,Kafka 也能保证顺序。因为底层引入了 Sequence Number(序列号)。Broker 知道 A 的序列号是 0,B 的序列号是 1。如果 Broker 先收到 B(1),发现 A(0) 没收到,会直接抛弃 B(1) 并返回OutOfOrderSequenceException,强制 B 也跟着 A 一起重试。
2. 副作用二:消息重复 (Duplication)
场景: 消息实际已经写入 Broker,但是 Broker 返回 ACK 给生产者时网络断了。生产者以为没发送成功,触发重试,导致 Broker 存了两份一模一样的数据(At-Least-Once 语义)。
底层解决方案:幂等性(Idempotence)
Kafka 0.11 版本后引入了 enable.idempotence=true(现代版本默认开启)。底层通过 PID 和 SeqNum 实现:
- PID (Producer ID): 生产者启动时,向 Broker 申请一个唯一的 PID。
- SeqNum (Sequence Number): 生产者发送的每一条消息,底层都会为其分配一个递增的序列号。
- Broker 端去重: Broker 会在内存中维护
<PID, Partition>对应的最新 SeqNum。当重试的请求到达时,Broker 发现这个请求的 SeqNum 小于或等于自己缓存的 SeqNum,就会知道这是重试的重复消息。Broker 会默默丢弃重复数据,但依然向生产者返回成功的 ACK,从而完美解决重复问题。
四、 核心参数总结与最佳实践
理解了底层原理,我们看相关的底层参数配置就豁然开朗了:
| 参数 | 作用 | 最佳实践 / 现代默认值 |
|---|---|---|
retries |
允许重试的最大次数 | 设为无限大 (MAX_VALUE),交由时间控制 |
delivery.timeout.ms |
消息从产生到发送成功/失败的绝对时间上限 | 默认 120000ms (2分钟)。这是决定重试多久的最终 Boss |
retry.backoff.ms |
每次重试前的退避等待时间 | 默认 100ms。遇到瞬间网络抖动时给系统缓冲时间 |
enable.idempotence |
是否开启底层幂等去重 | 务必设为 true(解决重试导致的重复和乱序) |
max.in.flight.requests.per.connection |
单连接最大并发未确认请求数 | 设为 <= 5(配合幂等性,既能高并发,又不会乱序) |
总结
生产者的重试机制底层是通过异步后台线程拦截异常、过滤可重试错误、基于时间轮的退避重回队列来实现的。同时,为了擦除重试带来的“乱序”和“重复”副作用,底层深度集成了幂等状态机(PID + 序列号校验),最终向开发者提供了一个既高可用又精确(Exactly-Once 语义基石)的发送抽象。