 播面
播面 Kafka Producer 的分区路由策略(Partitioner)有哪些?
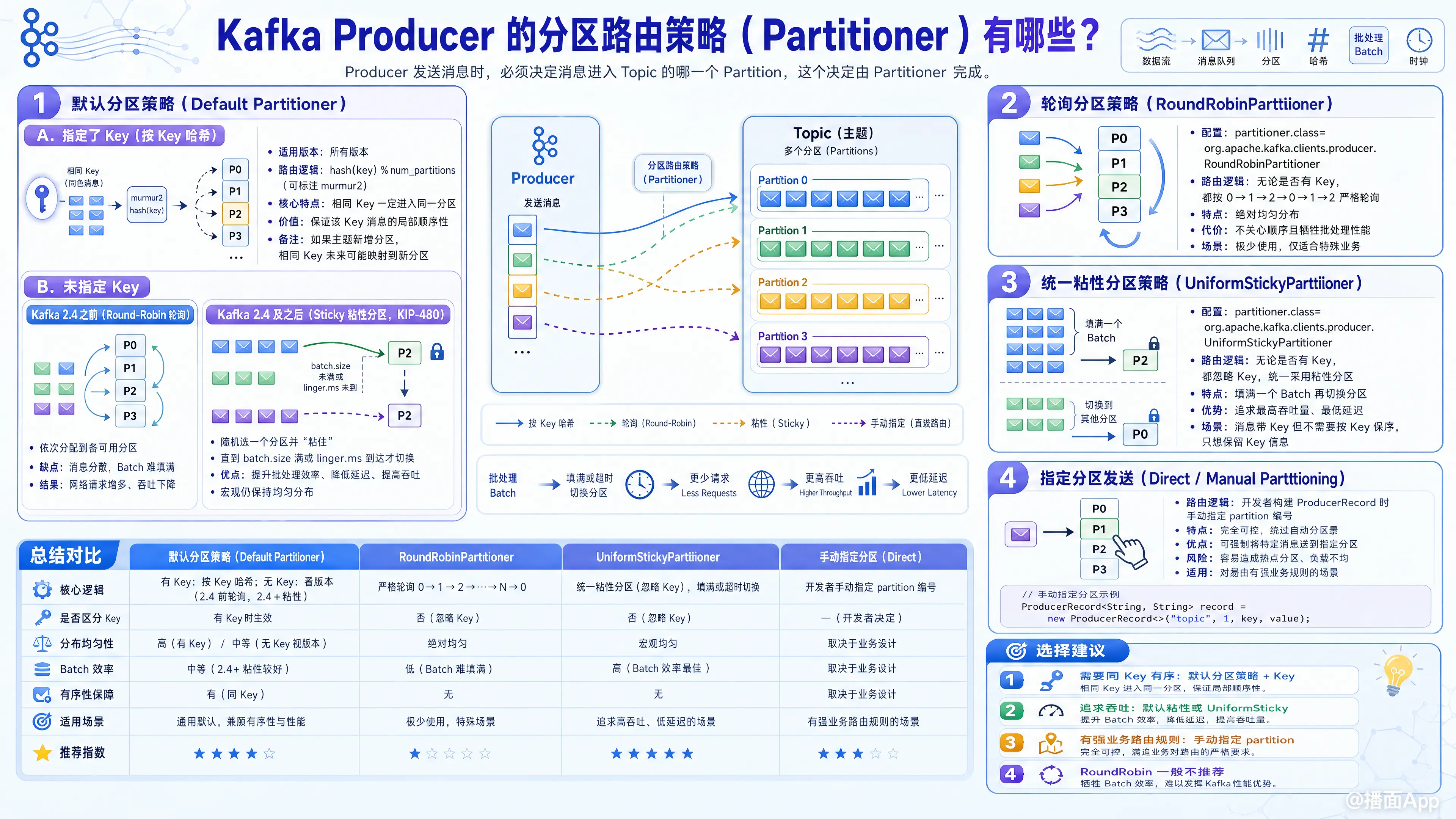
在 Kafka 中,生产者(Producer)在发送消息时,必须决定将消息发送到主题(Topic)的哪一个分区(Partition)。这个决定由 分区路由策略(Partitioner) 来完成。
Kafka 提供了多种内置的分区策略,并且允许用户自定义策略。以下是 Kafka Producer 支持的主要分区路由策略:
1. 默认分区策略(Default Partitioner)
这是 Kafka Producer 默认使用的策略。注意:在 Kafka 2.4 版本前后,默认策略发生了重大的改变。
A. 如果消息指定了 Key(按 Key 哈希)
- 适用版本: 所有版本
- 路由逻辑: 如果
ProducerRecord中指定了key,Kafka 会对该key进行哈希计算(通常使用 murmur2 算法),然后将哈希值对总分区数取模:hash(key) % num_partitions。 - 特点: 保证了相同 Key 的消息一定会被路由到同一个分区,从而保证了该 Key 对应消息的局部顺序性。
- 注意:如果主题增加了分区,相同 Key 可能会被路由到新的分区。
B. 如果消息没有指定 Key(无 Key 时的策略)
- Kafka 2.4 之前的版本(Round-Robin 轮询):
如果没有指定key,生产者会采用轮询(Round-Robin)的方式,将消息依次分配到各个可用分区中。
缺点: 这种方式会导致消息极其分散,无法有效填满一个批次(Batch),导致网络请求增多、吞吐量下降。 - Kafka 2.4 及之后的版本(Sticky 粘性分区策略):
为了解决轮询带来的批次效率低下的问题,Kafka 引入了 粘性分区器(Sticky Partitioner) (KIP-480)。
路由逻辑: 生产者会随机选择一个分区,并“粘”在这个分区上,直到该分区的批次(Batch)被填满(达到batch.size)或者等待时间耗尽(达到linger.ms)。批次发送出去后,再随机选择下一个分区进行“粘滞”。
优点: 极大地提升了 Batching(批处理)效率,降低了延迟,提高了吞吐量,同时在宏观上依然保持了数据的均匀分布。
2. 轮询分区策略(RoundRobinPartitioner)
- 配置方式:
partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner - 路由逻辑: 无论消息是否有
key,都严格按照轮询的方式(0, 1, 2, 0, 1, 2...)将消息依次发送到所有的分区中。 - 适用场景: 极少使用。只有当你完全不在乎消息顺序,且出于某种极其特殊的业务原因要求单条消息绝对均匀分布,而不考虑网络批处理性能时才会使用。
3. 统一粘性分区策略(UniformStickyPartitioner)
- 配置方式:
partitioner.class=org.apache.kafka.clients.producer.UniformStickyPartitioner - 路由逻辑: 无论消息是否有
key,都忽略 Key,强制采用“粘性分区”策略(即填满一个批次再换下一个分区)。 - 适用场景: 消息带有关联的 Key(例如想要在消费端记录这个 Key),但在 Kafka 路由阶段你不需要保证相同 Key 的顺序,只追求最高的吞吐量和最低的延迟。
4. 指定分区发送(Direct/Manual Partitioning)
- 路由逻辑: 开发者在构建
ProducerRecord对象时,直接硬编码指定partition的编号。java// 指定发送到编号为 2 的分区 ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", 2, "my-key", "my-value"); - 特点: 优先级最高。只要代码里指定了分区,Kafka 就会忽略所有的 Partitioner 策略,直接发往该分区。
- 适用场景: 开发者自己维护路由逻辑,或者有极其严格的特定消息发往特定分区的需求。
5. 自定义分区策略(Custom Partitioner)
如果内置的策略不能满足业务需求,Kafka 允许开发者编写自定义的分区规则。
- 实现方式: 实现
org.apache.kafka.clients.producer.Partitioner接口,重写partition()方法。 - 配置方式:
partitioner.class=com.yourcompany.MyCustomPartitioner - 常见业务场景:
- 处理数据倾斜(Data Skew): 比如某个 Key 的数据量特别大,按普通哈希会压垮单个分区。可以在自定义策略中把特定的热点 Key 散列到多个特定分区,其他的 Key 走普通哈希。
- VIP/多租户隔离: 根据消息 Key 或者 Value 中的某个字段,判断如果是 VIP 客户的数据,强制路由到拥有高性能磁盘的分区 0 和 1;普通用户数据路由到分区 2、3、4。
- 机房/地域就近路由: 根据生产者所在的机房,将消息路由到对应机房的 Broker 所在的分区。
自定义 Partitioner 代码示例(Java):
java
public class VipPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
String k = (String) key;
// 假设 VIP 客户的数据以 "VIP_" 开头,专门放到 0 号分区
if (k != null && k.startsWith("VIP_")) {
return 0;
}
// 非 VIP 客户走普通的哈希逻辑,分配到 1 到 numPartitions-1 的分区
return Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1) + 1;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}总结与选型建议
| 业务需求 | 推荐策略 | 策略描述 |
|---|---|---|
| 需要保证消息局部有序 (如按订单ID) | Default Partitioner | 必须指定 Key。Kafka 会按 Key 哈希路由。 |
| 无需保序,追求最高吞吐量 | Default Partitioner | 不要指定 Key,利用 Kafka 2.4+ 的粘性分区。 |
| 有 Key,但不想保序,只求高吞吐 | UniformStickyPartitioner | 强制忽略 Key 的哈希,采用粘性批次发送。 |
| 特殊的业务路由规则 (如隔离VIP数据) | Custom Partitioner | 实现 Partitioner 接口,编写自定义逻辑。 |
| 精准控制某条消息去哪个分区 | 指定 Partition | 在 ProducerRecord 中直接写入分区号。 |