 播面
播面 Kafka KRaft 模式的架构及其解决的痛点问题
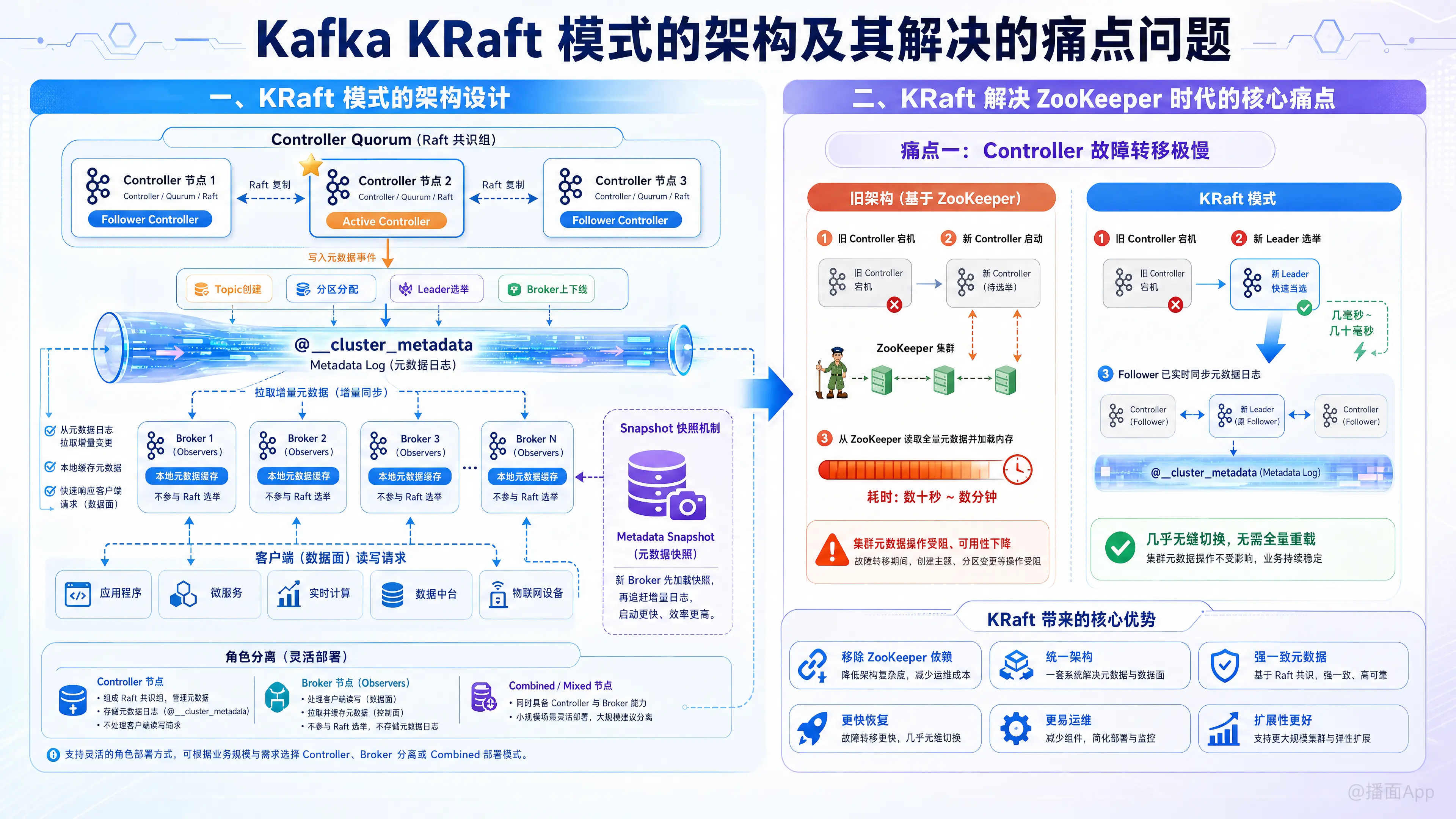
Kafka KRaft(Kafka Raft Metadata mode)是 Kafka 架构演进史上最重要的一次变革,最初在 KIP-500 中提出。它的核心思想是移除对 ZooKeeper 的依赖,将元数据管理内置到 Kafka 内部,使用基于 Raft 共识算法的变体来管理集群元数据。
下面将详细解析 KRaft 的架构设计,以及它究竟解决了 ZooKeeper 时代的哪些核心痛点。
一、 KRaft 模式的架构设计
在 KRaft 模式下,Kafka 的元数据不再存储在外部系统(ZooKeeper),而是存储在 Kafka 内部的一个特殊的内部主题(Topic)中,名为 @__cluster_metadata。
KRaft 架构的核心组件和运作机制如下:
1. 节点角色分离
在 KRaft 模式下,Kafka 进程(Node)可以承担不同的角色,通过 process.roles 参数配置:
- Controller(控制器): 负责管理集群元数据(Topic 创建、分区分配、Leader 选举等)。多个 Controller 节点组成一个 Quorum(仲裁核心),使用 Raft 算法选举出一个 Active Controller。
- Broker(数据代理): 负责处理客户端的读写请求(数据面)。它们不再连接 ZooKeeper,而是直接向 Active Controller 汇报状态,并拉取元数据。
- Combined / Mixed(混合节点): 一个节点既是 Controller 又是 Broker。通常用于小规模集群或开发测试环境。
2. 元数据日志(Metadata Log)
- Kafka 贯彻了“Eat your own dog food”(吃自己的狗粮)的理念,将元数据变更视为事件流。
- Active Controller 将所有的元数据状态变更(如 Broker 上线/下线、分区 Leader 切换)写入到内部的元数据日志(
@__cluster_metadata)中。 - Quorum 中的其他 Follower Controller 会通过 Raft 协议复制这部分日志,保持强一致性。
3. Broker 作为“观察者”(Observers)
- 普通的 Broker 节点不参与 Raft 选举,它们作为“观察者”从 Active Controller 拉取元数据日志(就像普通的 Kafka 消费者消费 Topic 一样)。
- 每个 Broker 都在本地内存中维护了一份完整的元数据缓存。当元数据发生变更时,Broker 只需拉取增量的日志事件并应用到内存中。
4. 元数据快照(Snapshot)
为了防止元数据日志无限期增长,KRaft 引入了快照机制。Controller 会定期将内存中的全量元数据状态打包成快照保存到磁盘。新的 Broker 启动时,可以直接读取最新的快照,然后再追赶增量日志,极大地加快了启动速度。
二、 KRaft 解决了旧架构(ZooKeeper)的哪些痛点?
在了解 KRaft 架构后,我们来看看它精准打击了旧架构的哪些致命弱点:
1. 痛点一:Controller 故障转移(Failover)极慢,导致集群可用性下降
- 旧架构: 当旧的 Active Controller 宕机时,新选举出的 Controller 需要从 ZooKeeper 中同步读取全量的元数据并加载到内存中。如果集群有几十万个分区,这个过程可能需要数十秒甚至几分钟。在此期间,集群无法进行任何元数据操作(如创建 Topic、处理 Broker 宕机),导致局部不可用。
- KRaft 解决: 在 KRaft 架构中,Follower Controller 已经通过 Raft 协议在内存中实时同步了最新的元数据日志。一旦 Active Controller 宕机,新的 Leader 选举在几毫秒到几十毫秒内即可完成,且无需重新加载元数据,实现了几乎无缝的故障转移。
2. 痛点二:集群规模的扩展瓶颈(分区数量上限)
- 旧架构: 由于上述的加载慢和 ZooKeeper 本身的性能限制,社区官方建议一个 Kafka 集群的分区数不要超过 20万个。超过这个数量,集群极不稳定。
- KRaft 解决: 因为元数据变成了事件流,且每个 Broker 都在内存中维护了元数据,分发效率极高。KRaft 模式将单集群支持的分区数量上限提升到了 百万级别,极大提升了 Kafka 的横向扩展能力。
3. 痛点三:运维复杂性与“双系统”负担
- 旧架构: 运维 Kafka 意味着必须同时运维 ZooKeeper。你需要掌握两套系统的配置、监控、调优、报警机制。更麻烦的是安全配置,Kafka 的认证机制(如 SASL)与 ZooKeeper 的认证机制(如 JAAS)不一致,配置极度繁琐。
- KRaft 解决: 彻底去中心化,移除 ZK。现在只需部署、监控、配置 Kafka 一套系统。安全模型统一,大大降低了运维成本。对于边缘计算(Edge)和本地开发,甚至可以单节点启动 Kafka(混合模式),极其轻量。
4. 痛点四:元数据不一致(Split-Brain 脑裂风险)
- 旧架构: 元数据分散在两个系统中(ZooKeeper 存一份,Controller 内存存一份,各个 Broker 内存存一份)。Broker 是通过 RPC 调用接收 Controller 的指令,在网络分区或高负载下,极易出现 Broker 状态与 ZooKeeper 中状态不一致的情况。
- KRaft 解决: 基于事件溯源(Event Sourcing)理念,所有的元数据变更都是有序的日志。每个节点(Controller 和 Broker)只需按相同的顺序回放(Replay)这条日志,就能确保各自内存中的状态达到最终绝对一致。彻底消除了元数据分歧的问题。
5. 痛点五:Broker 重启引发的元数据风暴
- 旧架构: 当一个 Broker 重启上线时,Controller 需要向该 Broker 发送它负责的所有分区的完整状态信息。如果该 Broker 负责大量分区,这个 RPC 请求会非常庞大,容易造成网络拥塞和 Controller 压力。
- KRaft 解决: Broker 采用“拉模式”(Fetch)主动向 Controller 同步元数据日志。Broker 重启后,只需从它上次停止的 Offset 处继续拉取增量元数据即可,极大地减轻了 Controller 的负担和网络传输量。
总结
Kafka KRaft 模式不仅仅是“换掉了一个组件”,而是对 Kafka 分布式协同机制的一次底层重构。它将元数据管理的数据结构从“树状目录(ZK)”变成了“追加日志(Kafka 强项)”,这不仅让 Kafka 变得更加自洽、轻量、易运维,更彻底打破了长期以来的分区数量扩展瓶颈,使 Kafka 真正成为了一个能够承载百万级分区的超大规模流处理平台。
(注:自 Kafka 3.3 版本起,KRaft 模式已被标记为生产可用;从 Kafka 3.7+ 版本开始,ZooKeeper 已被逐步弃用并最终移除。)