 播面
播面 如何在发送请求前精准估算(或计算)组装好的上下文Token数量?如果超限,兜底截断策略是什么?
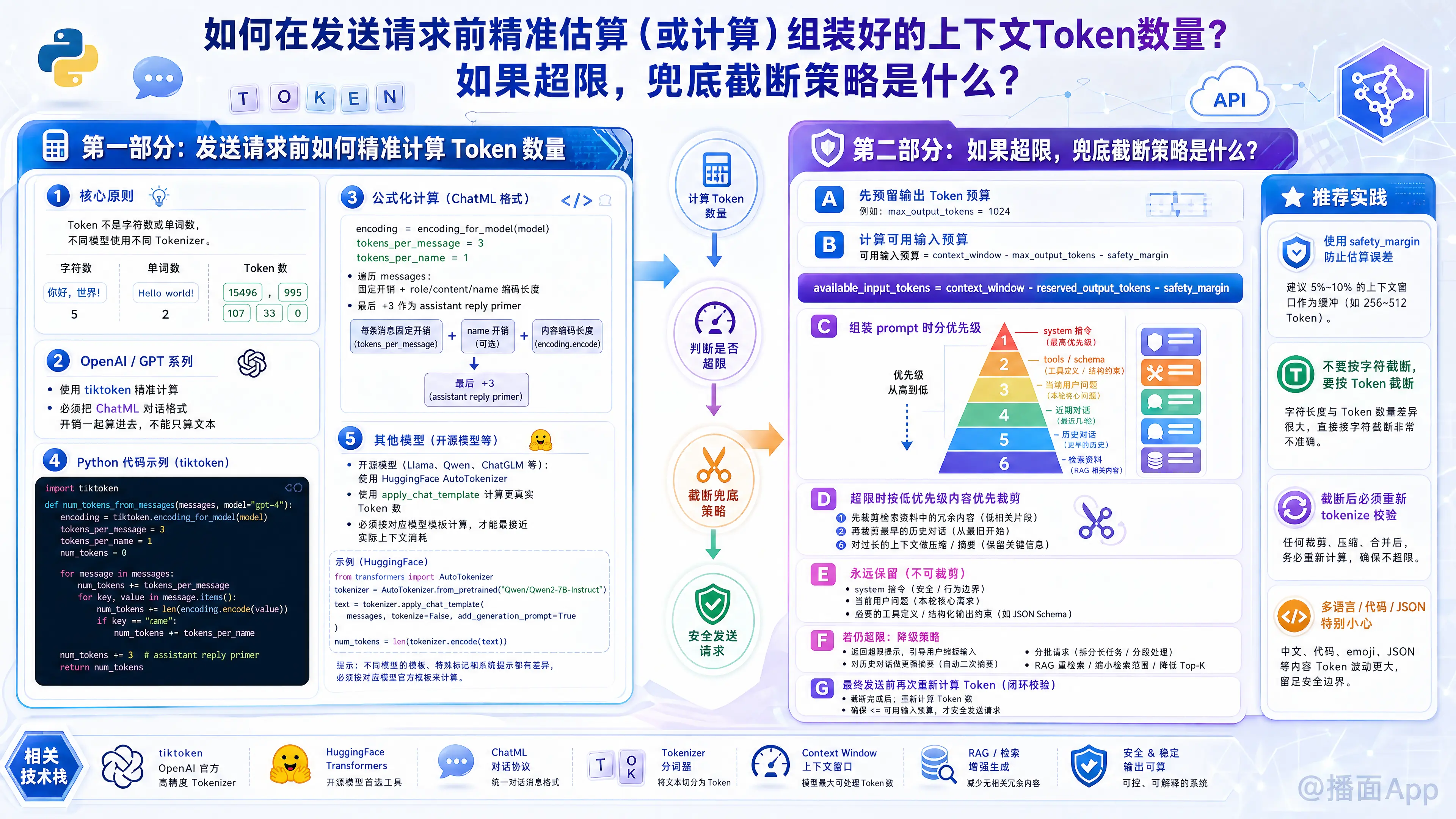
在调用大语言模型(LLM)API时,精准计算 Token 数量并设计健壮的截断策略是保证系统稳定性、控制成本和避免 400 Bad Request(超出上下文窗口)错误的核心能力。
以下是完整的解决方案,分为精准计算 Token 和 超限兜底截断策略 两部分。
第一部分:如何在发送请求前精准计算 Token 数量?
Token 的计算并不是简单的字符数或单词数统计,不同的模型使用了不同的分词器(Tokenizer)。
1. 精准计算(以 OpenAI / GPT 系列为例)
对于 OpenAI 模型,最精准的方式是使用官方提供的 tiktoken 库。注意:不能仅仅计算文本的 Token,必须加上对话格式(ChatML)带来的额外开销。
python
import tiktoken
def num_tokens_from_messages(messages, model="gpt-4"):
"""返回一组 messages 所需的精确 Token 数"""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base") # GPT-3.5 / GPT-4 默认
# 不同的模型格式开销不同,GPT-3.5 和 GPT-4 通常适用以下规则
tokens_per_message = 3 # 每条消息的固定开销:<|im_start|>role\n...<|im_end|>\n
tokens_per_name = 1 # 如果有 name 字段,额外 +1
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
# 模型生成回复时的固定引导 Token(<|im_start|>assistant\n)
num_tokens += 3
return num_tokens
# 测试
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好,今天天气怎么样?"}
]
print(f"Total Tokens: {num_tokens_from_messages(messages)}")2. 其他模型的计算方式
- 开源模型 (Llama, Qwen, ChatGLM 等):
使用 HuggingFace 的transformers库加载对应的tokenizer。pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat") # apply_chat_template 会自动拼接角色标签,计算出最真实的 Token 数 tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True) print(len(tokens)) - Anthropic (Claude):
使用官方的 SDK(如 TypeScript 的@anthropic-ai/tokenizer)进行离线计算。
3. 粗略估算法(前端或轻量级场景)
如果不方便引入分词器库,可以使用经验公式进行估算(建议计算结果乘以 1.2 作为安全冗余):
- 纯英文:1 Token ≈ 4 个英文字符 ≈ 0.75 个单词。
- 纯中文:GPT-4 / Qwen 等现代模型,1 Token ≈ 1 ~ 1.5 个汉字;较老的模型(如 GPT-3)可能 1 个汉字占 2~3 个 Token。
第二部分:超限兜底截断策略 (Fallback Strategies)
如果你计算出组装好的 Context Tokens + Max Expected Output Tokens > Model Window Size,就必须执行截断。
一个成熟的系统通常采用多级降级策略(Graceful Degradation)。以下策略按推荐优先级排序:
策略一:按重要性分级,剔除低优消息(最常用:滑动窗口)
在多轮对话中,最老的聊天记录价值最低。
- 绝对保留:System Prompt(系统设定)、最新的 User Query(用户当前问题)。
- 截断目标:中间的历史对话(History)。
- 做法:从最旧的历史对话开始,一对一对地(User + Assistant)删除,直到总 Token 数降至安全阈值以下。
python
def truncate_chat_history(messages, max_tokens, model="gpt-4"):
"""滑动窗口策略:保留System和最新消息,剔除最老的多轮对话"""
# 假设 messages[0] 是 system, messages[-1] 是最新的 user prompt
system_msg = [m for m in messages if m["role"] == "system"]
current_query = [messages[-1]]
history = messages[len(system_msg):-1] # 中间的历史记录
while num_tokens_from_messages(system_msg + history + current_query, model) > max_tokens:
if len(history) >= 2:
# 每次删掉最老的一轮对话(一问一答,共两条)
history = history[2:]
elif len(history) == 1:
history = []
else:
break # 历史已经被清空了
return system_msg + history + current_query策略二:RAG(检索增强)场景的 Chunk 截断
如果上下文是由向量数据库检索出的文档块(Chunks)组装的:
- 按向量相似度(Relevance Score)对 chunks 排序。
- 从评分最低的 chunk 开始剔除,直到满足 Token 限制。
策略三:历史记录动态摘要(Summarization)
这是一种高级策略,不直接丢弃老消息,而是将其压缩。
- 触发条件:发现历史消息超出阈值。
- 动作:异步或同步调用一个轻量级模型(如 GPT-3.5/Qwen-Turbo),将老的 10 轮对话总结为一段 200 Tokens 的摘要文本。
- 替换:将老的
[{"role":"user"}, {"role":"assistant"}...]替换为{"role": "system", "content": "Previous Context: [摘要]"}。
策略四:终极兜底 —— 强制 Token 级安全截断 (Hard Cut)
如果剔除了所有历史记录和次要文档,单条用户的输入或核心 System Prompt 依然超限(例如用户粘贴了一本几万字的小说),就必须进行强制截断。
⚠️ 危险做法:直接 text[:2000] 切割字符串。在多字节字符(如中文、Emoji)或 JSON 结构中,这样切极易切碎字符,导致模型乱码或报错。
✅ 正确做法:使用 Tokenizer 编码成数组 -> 截取数组 -> 解码回文本。
python
def safe_hard_truncate(text, max_tokens, model="gpt-4"):
"""Token 级别的安全强制截断"""
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(text)
if len(tokens) <= max_tokens:
return text
# 截取允许的最大 Token,然后安全解码回字符串
truncated_tokens = tokens[:max_tokens]
return encoding.decode(truncated_tokens)
# 使用场景:
# current_query["content"] = safe_hard_truncate(current_query["content"], 4000)💡 工程实践的最佳建议 (Best Practices)
- 预留输出空间 (Buffer):
模型窗口 = 输入 (Context) + 输出 (Generation)。如果你使用的模型窗口是 8192,不要把输入塞到 8000。建议预留至少 1000 - 2000 Tokens 给模型的回答。
公式:Max Input Tokens = Model_Context_Window - Max_Tokens_Param - Buffer(约200) - 避免破坏 JSON/Markdown 结构:
如果强行截断了一段代码块或 JSON,模型可能会补全错误的格式。如果截断涉及结构化数据,应当按结构节点(如 JSON Array 的元素)进行剔除,而不是按字符切断。 - 多模态图片的 Token 计算:
GPT-4-Vision 等多模态模型中,图片的 Token 取决于分辨率。OpenAI 规则大约是:低分辨率固定 85 Tokens;高分辨率计算瓦片(Tiles),每 512x512 算 170 Tokens 再加上 85 基础值。在处理图文混排时需格外注意累加此项。