 播面
播面 如何设计机制让Agent自主决定何时“写入”新记忆,以及何时从上下文中“遗忘”无用信息?
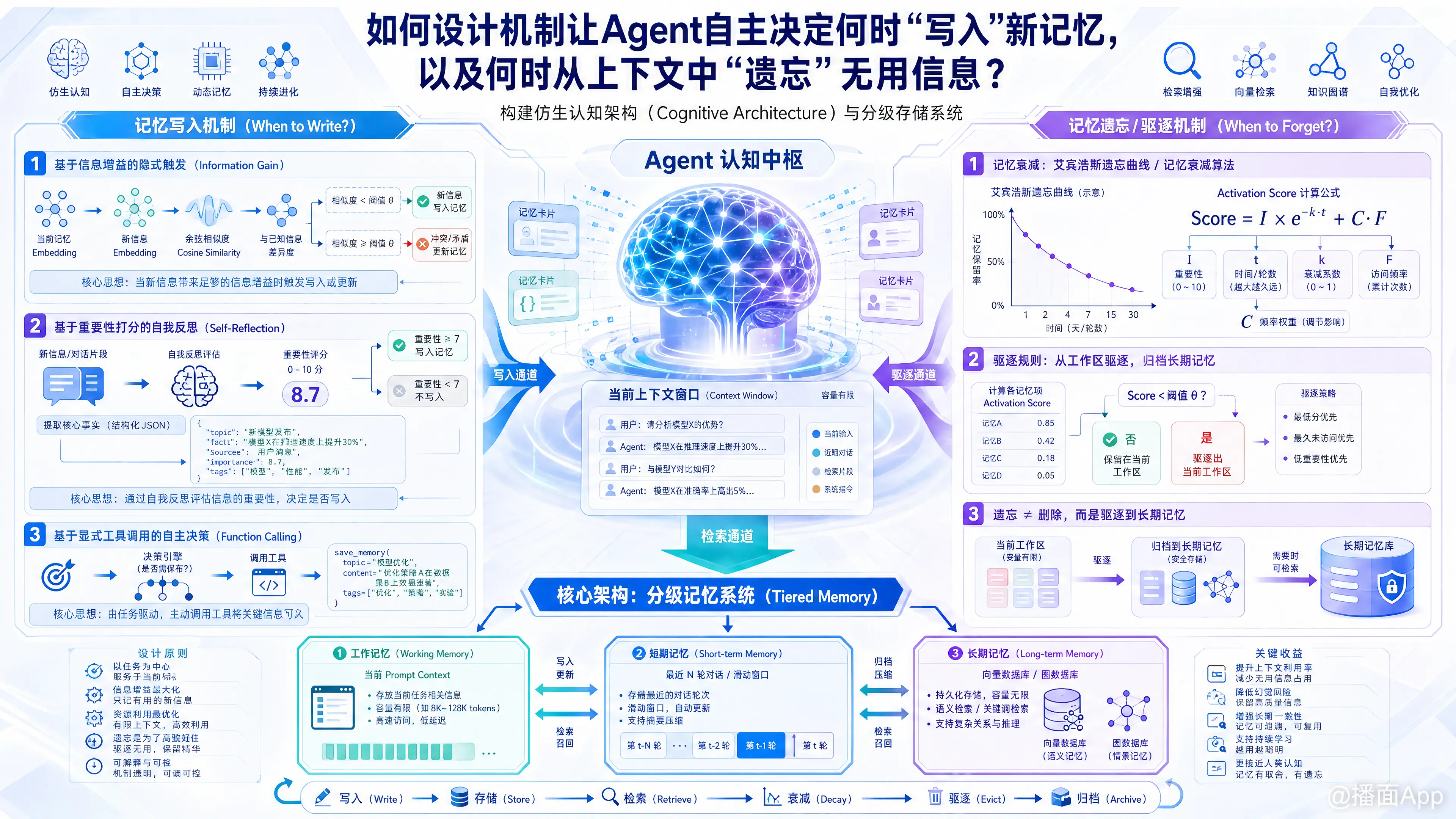
设计让Agent自主管理记忆(写入与遗忘)的机制,本质上是为其构建一个仿生认知架构(Cognitive Architecture)与分级存储系统。
在上下文中,“遗忘”通常不是物理删除,而是“从当前工作区(Context Window)中驱逐(Evict),归档到长期记忆”;而“写入”则是“提取有价值的信息并持久化”。
以下是实现这一目标的核心机制设计蓝图:
一、 核心架构:分级记忆系统 (Tiered Memory)
要实现自主管理,首先需要对记忆进行分级:
- 工作记忆 (Working Memory): 即当前的Prompt Context,容量有限,包含当前对话和被激活的相关记忆。
- 短期记忆 (Short-term Memory): 最近N轮的对话历史(通常以滑动窗口形式存在)。
- 长期记忆 (Long-term Memory): 外部存储(如向量数据库、图数据库),包含语义记忆(事实、知识)和情景记忆(历史事件)。
二、 记忆“写入”机制(When to Write?)
Agent如何判断一段信息值得被写入长期记忆?可以通过以下三种维度的机制结合:
1. 基于“信息增益”的隐式触发 (Information Gain)
不需要Agent自己思考,由系统后台计算。
- 机制: 将当前对话的Embedding与长期数据库中的已有Embedding进行余弦相似度对比。
- 判断: 如果相似度低于某个阈值(说明是新信息),或者与已有事实产生冲突(需要更新),则自动触发写入/更新逻辑。
- 适用场景: 记录零碎的日常对话和新事件。
2. 基于“重要性打分”的自我反思 (Self-Reflection)
参考斯坦福“小镇智能体(Generative Agents)”的论文设计。
- 机制: 引入一个轻量级的后台LLM(或利用主Agent的闲置算力),对用户的每一段输入或Agent的输出进行0-10分的重要性评估。
- Prompt示例:
“评估以下信息对未来交互的重要性(0-10分)。日常问候为1分,用户的核心偏好/重要事实为9分。如果分数≥7,请提取核心事实并输出JSON格式写入长期记忆。”
- 适用场景: 提取用户的长期偏好(如“我吃花生过敏”)。
3. 基于“显式工具调用”的自主决策 (Function Calling)
赋予Agent主动操作记忆的工具(API)。
- 机制: 在System Prompt中告知Agent:“当你认为某些信息在未来完成任务时会用到,请调用
save_memory工具。” - 工具定义:
save_memory(topic: str, content: str, tags: list) - 适用场景: 任务驱动型Agent(如编程助手记下用户的代码规范,私人助理记下用户的日程)。
三、 记忆“遗忘/驱逐”机制(When to Forget?)
如何让Agent把无用信息从Context(工作记忆)中移除,以节省Token并降低幻觉?
1. 记忆衰减算法 (Ebbinghaus Decay Curve)
为工作记忆中的每一条信息/上下文片段维护一个激活分数 (Activation Score)。
- 公式:
- : 初始重要性评分 (Importance)
- : 距离上一次被访问经过的时间/轮数 (Time)
- : 衰减系数 (Decay Rate)
- : 被检索/使用的频率 (Frequency)
- 机制: 随着对话轮数增加,旧信息的Score会指数级下降。当Agent思考或回答时引用了某条记忆,其频率 增加,Score重新上升。
- 驱逐规则: 每次组装Context时,剔除Score低于阈值的信息。
2. 基于“任务边界”的上下文清理 (Task-Boundary Clearing)
Agent可以感知任务的生命周期。
- 机制: Agent在每次回复时,输出当前的任务状态(如
status: "in_progress"或status: "completed")。 - 驱逐规则: 当Agent判定某个子任务
completed(例如成功预订了机票),系统自动将与“预订机票”相关的中间推理过程(Scratchpad)和临时信息从Context中“遗忘”(归档或总结),只保留一个结果摘要(“已预订飞往北京的国航CA123”)。
3. 动态注意力剪枝 (Dynamic Attention Pruning / 向量检索驱逐)
- 机制: 当前用户的输入通常代表当前意图(Intent)。将当前Intent转化为向量,与Context中现存的所有记忆块(Memory Blocks)计算相关性。
- 驱逐规则: 如果某段上下文与当前Intent的相似度极低(例如用户从“讨论量子物理”突然转向“今晚吃什么”),系统主动将“量子物理”的上下文从工作记忆中换出(Swap out),替换为与“饮食”相关的长期记忆。
4. Agent显式调用“遗忘”工具 (Explicit Forget)
- 机制: 给Agent提供
remove_from_context(memory_id)工具。 - 指导原则: 在System Prompt中规定:“如果你发现当前上下文中的某些信息已经过时、被证明是错误的,或者对当前任务产生干扰,请调用工具将其移除。”
四、 具体实现范式:双系统架构 (Dual-System Architecture)
直接让一个Agent同时负责“对话”、“思考”、“写记忆”、“删记忆”,会导致模型负载过重且容易指令遵循失败(Instruction Override)。业界最佳实践是主从架构(Main-Worker):
- System 1 (前台 Agent - 潜意识/快速响应):
- 只负责与用户对话,解决当前任务。
- 它不直接写数据库,但会在输出流中附带特殊标记或思考过程,例如
<thought>用户提到了新需求</thought>。
- System 2 (后台 Agent - 海马体/记忆管理):
- 异步运行。它监听前台Agent的对话历史。
- 执行“写入”:定期(如每3轮对话)进行总结(Summarization)和实体提取(Entity Extraction),并写入图数据库或向量库。
- 执行“遗忘”:计算记忆的衰减分数,并负责在下一轮用户输入时,精准组装并过滤出最优的Context Prompt提供给前台Agent。
五、 总结与效果评估
将上述机制组合后,Agent的工作流将变为:
- 接收输入 -> 2. 向量检索关联记忆 -> 3. 计算Context中现有记忆的衰减/相关性并剔除无用项 -> 4. 组装新Context -> 5. Agent生成回复 -> 6. 后台评估该轮对话的价值 -> 7. 更新长期记忆数据库。
如何评估这套机制设计得好不好?
- Context 召回率: 需要的信息是否都在Context中?(衡量“提取”和“衰减算法”的准确性)。
- Token 消耗率: 在无限轮对话中,Context Token是否能维持在稳定水位而不爆仓?(衡量“遗忘”机制)。
- 幻觉率: Agent是否因为Context中堆积了过多的旧指令而产生行为混乱?(衡量上下文清理能力)。