 播面
播面 当Agent的历史对话记录超出模型的Max Tokens时,你会采取哪些“记忆折叠/压缩(Memory Summarization/Compression)”策略?
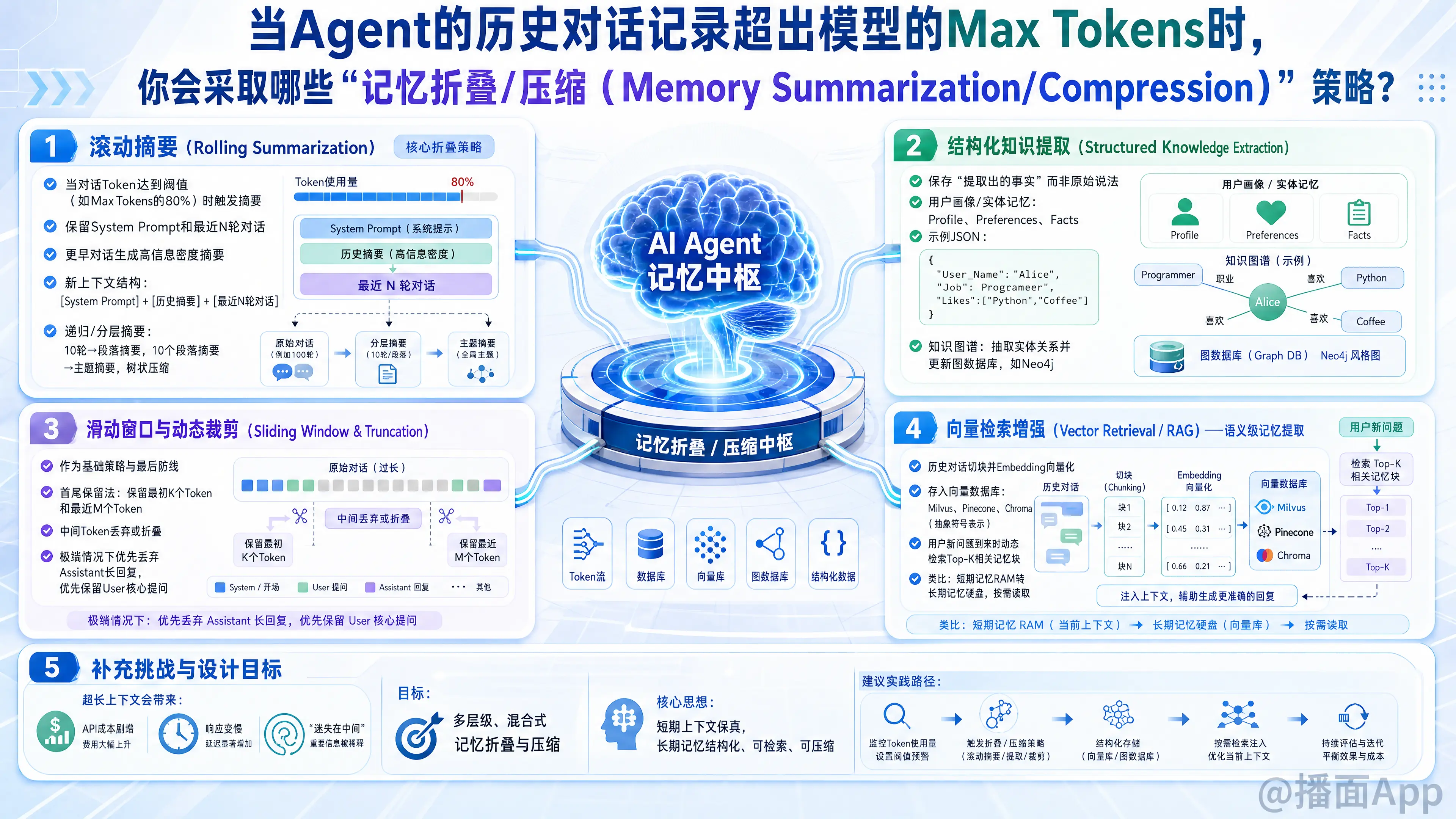
在构建Agent时,历史对话超出大语言模型(LLM)的Max Tokens是一个非常经典的工程挑战。即使现在的模型支持长上下文(如128K甚至1M),无限制地输入完整历史依然会导致API成本剧增、响应变慢,以及“迷失在中间(Lost in the middle)”(模型忽略长文本中间的信息)的问题。
为了解决这个问题,我会采取一种多层级、混合式的记忆折叠与压缩策略。以下是具体的实施方案,从简单到高级分为五类:
1. 滚动摘要(Rolling Summarization)—— 核心折叠策略
这是最直接的“记忆折叠”方法,将过去的原始对话转化为高信息密度的摘要。
- 基础滚动摘要:
- 当对话Token达到设定的阈值(如Max Tokens的80%)时,触发摘要机制。
- 保留系统设定(System Prompt)和最近的 轮对话(保证短期上下文的连贯性)。
- 将更早的对话交给LLM生成一段摘要。
- 新的上下文结构:
[System Prompt] + [历史摘要] + [最近N轮对话]。
- 递归/分层摘要(Hierarchical Summarization):
- 随着时间推移,“摘要的摘要”也会变长。可以采用分级机制:将10轮对话压缩成“段落摘要”,将10个“段落摘要”压缩成“主题摘要”。类似树状结构,越久远的记忆越抽象。
2. 结构化知识提取(Structured Knowledge Extraction)
与其保存“说了什么”,不如保存“提取出了什么事实”。这种压缩率极高,且对Agent极其有用。
- 用户画像/实体记忆(Entity Memory):
- 在后台运行一个轻量级的总结任务,从历史对话中提取关键实体(User Profile, Preferences, Facts)。
- 例如,将一大段讨论压缩成 JSON 键值对:
{"User_Name": "Alice", "Job": "Programmer", "Likes": ["Python", "Coffee"]}。 - 每次对话时,只将这些高密度的 JSON 注入到 System Prompt 中。
- 知识图谱(Knowledge Graph):
- 对于复杂的业务型Agent,将对话中的实体关系提取并更新到图数据库(如Neo4j)中。Agent只需查询图谱,无需读取原始文本。
3. 滑动窗口与动态裁剪(Sliding Window & Truncation)
这是最基础的策略,通常与其他策略配合使用,以作为最后一道防线。
- 首尾保留法(Keep Start and End):
- 保留对话的最初 个Token(通常包含System Prompt和任务背景)和最近的 个Token(当前正在讨论的内容)。
- 直接丢弃或折叠中间的Token。
- 按系统级/用户级/助手级进行过滤:
- 在极端情况下,可以优先丢弃Agent生成的大段回复(Assistant Message),而保留用户的核心提问(User Message),因为用户的意图通常更重要。
4. 向量检索增强(Vector Retrieval / RAG)—— 语义级记忆提取
当记忆量极大时,不能把所有记忆都塞进Prompt,而是“按需读取”。这是将“短期记忆(RAM)”转化为“长期记忆(硬盘)”的策略。
- 对话切块打向量(Embedding):
- 将历史对话按轮次或语义块(Chunk)进行切割,通过Embedding模型转化为向量,存入向量数据库(如Milvus, Pinecone, Chroma)。
- 动态回忆(Dynamic Recall):
- 当用户输入新问题时,先对当前问题进行向量检索,找出历史中最相关的 Top-K 个对话块。
- 新的上下文结构:
[System Prompt] + [检索到的相关历史片段] + [最近短期对话] + [当前问题]。 - 注:这种方式完美解决了Max Tokens限制,并且能回忆起非常久远且具体的细节。
5. 提示词压缩算法(Prompt Compression)—— Token级硬压缩
如果必须保留大量文本,可以使用专门的算法或小模型剔除冗余Token,而不改变语义。
- 信息熵压缩(如 LLMLingua):
- 使用较小的模型(如 LLaMA-7B 或 BERT)评估Prompt中每个词的“信息熵”。
- 去除停用词、废话和低信息量的Token,只保留核心词汇。
- 经过 LLMLingua 处理的文本,人类读起来可能像“电报体”(语法破碎),但大模型依然能完美理解,最高可节省 50%-80% 的Token。
💡 最佳工程实践:分层记忆架构(类似 MemGPT 的设计)
在实际的企业级Agent开发中,我通常不会只用一种策略,而是构建一个三级记忆系统:
- 工作记忆 (Working Memory - 缓冲区):
- 直接保留原始文本,包含 System Prompt + 最近 5~10 轮对话。(保证当前聊天的绝对流畅)。
- 语义记忆 (Semantic Memory - 知识库):
- 超出缓冲区的对话,提取其中的“事实(Facts)”和“用户画像(Profile)”,以结构化方式(JSON)持续更新并保留在上下文中。(策略2)
- 情景记忆 (Episodic Memory - 数据库):
- 将所有过去的原始对话存入向量数据库。当用户突然聊起一个月前的话题时,通过 RAG 机制将其无缝调取到当前Prompt中。(策略4)
通过这种“短期滑动窗口 + 中期结构化提取 + 长期向量检索”的混合机制,既能保证Agent不会“失忆”,又能将单次调用的 Token 消耗控制在最低范围内,同时避开了 Max Tokens 的天花板。