 播面
播面 链路追踪系统中的 TraceId 和 SpanId 分别代表什么含义?
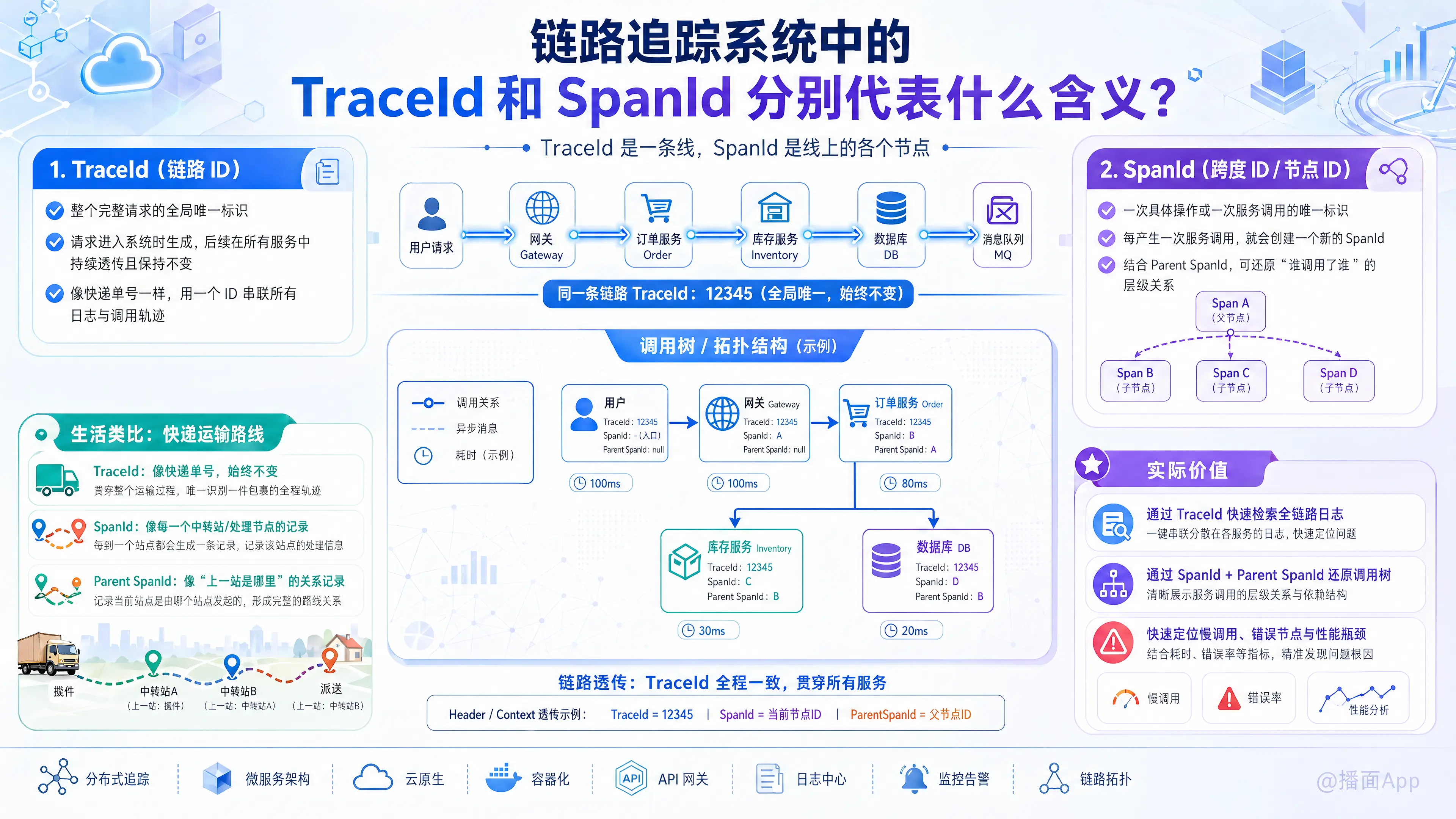
在微服务架构和分布式链路追踪系统(如 SkyWalking, Zipkin, Jaeger 等)中,TraceId 和 SpanId 是两个最核心的概念,它们共同协作来还原一个复杂请求的完整调用链路。
你可以用一句话来理解它们的关系:TraceId 是一条线,SpanId 是线上的各个节点。
以下是它们的具体含义和工作原理:
1. TraceId (链路 ID)
- 代表含义:它是整个完整请求的全局唯一标识。
- 作用:当一个外部请求(例如用户点击了“下单”按钮)第一次到达系统的入口(如 API 网关)时,系统会为这个请求生成一个全局唯一的 TraceId。在这个请求后续调用所有微服务、数据库、消息队列的过程中,这个 TraceId 会一直被透传(带着走)且保持不变。
- 生活中的比喻:就像你寄快递时的快递单号。无论这个包裹经过了多少个中转站、快递员,这个单号始终是不变的。通过这个单号,你就能查出包裹的完整轨迹。
- 实际应用:当系统出现报错时,你只需要拿到报错日志里的 TraceId,去日志系统或追踪系统中一搜,就能把这个请求在所有微服务中的相关日志全部串联起来。
2. SpanId (跨度 ID / 节点 ID)
- 代表含义:它是某一次具体操作或某一次服务调用的唯一标识。
- 作用:在一个完整的请求(Trace)中,会包含多次微服务调用或内部操作(比如 A 调用 B,B 再查询数据库)。每一次这样的动作,就会生成一个新的 Span,并分配一个局部的唯一标识,也就是 SpanId。
- 核心关联(Parent SpanId):为了知道是谁调用了谁(梳理出层级关系),每个 Span 除了有自己的 SpanId,通常还会记录一个 Parent SpanId(父 SpanId)。如果没有父 SpanId,说明它是链路的起点(Root Span)。
- 生活中的比喻:依然是寄快递。快递单号是 TraceId,而包裹到达“北京分拨中心”、“上海转运中心”、“派件员小李”这些具体的每一个处理节点和记录,就对应一个个 SpanId。记录里还会写明“上一站是哪里”(Parent SpanId)。
3. 具体示例演示
假设有一个用户请求:用户 -> 网关 (Gateway) -> 订单服务 (Order) -> 库存服务 (Inventory) / 数据库 (DB)
当请求发生时,链路追踪的标识生成过程如下:
网关接收到用户请求:
- 生成全新的
TraceId = 12345 - 生成
SpanId = A(当前节点) Parent SpanId = null(因为它是起点)
- 生成全新的
网关调用“订单服务”:
TraceId = 12345(继续透传,保持不变)- 生成新的
SpanId = B Parent SpanId = A(说明是网关调用的订单服务)
“订单服务”调用“库存服务”:
TraceId = 12345(保持不变)- 生成新的
SpanId = C Parent SpanId = B(说明是订单服务调用的库存服务)
“订单服务”同时又去查了“数据库”:
TraceId = 12345(保持不变)- 生成新的
SpanId = D Parent SpanId = B(说明这也是订单服务发起的操作)
形成的调用树(调用链拓扑图):
借助 TraceId、SpanId 和 Parent SpanId,追踪系统能在后台完美还原出一棵树状图:
plaintext
TraceId: 12345
└── [SpanId: A] 网关 (耗时: 100ms)
└── [SpanId: B] 订单服务 (耗时: 80ms)
├── [SpanId: C] 库存服务 (耗时: 30ms)
└── [SpanId: D] 数据库 (耗时: 20ms)总结
- TraceId 解决的是“把相关的操作归为一组”的问题(全局串联)。
- SpanId 加上 Parent SpanId 解决的是“这一组操作之间的层级调用关系和先后顺序”的问题(局部定位与结构构建)。同时,Span 内部还会记录这次调用的开始时间、结束时间、状态码等详细性能数据。