 播面
播面 Zero-Shot CoT(例如在末尾加上 "Let's think step by step")为什么有效?
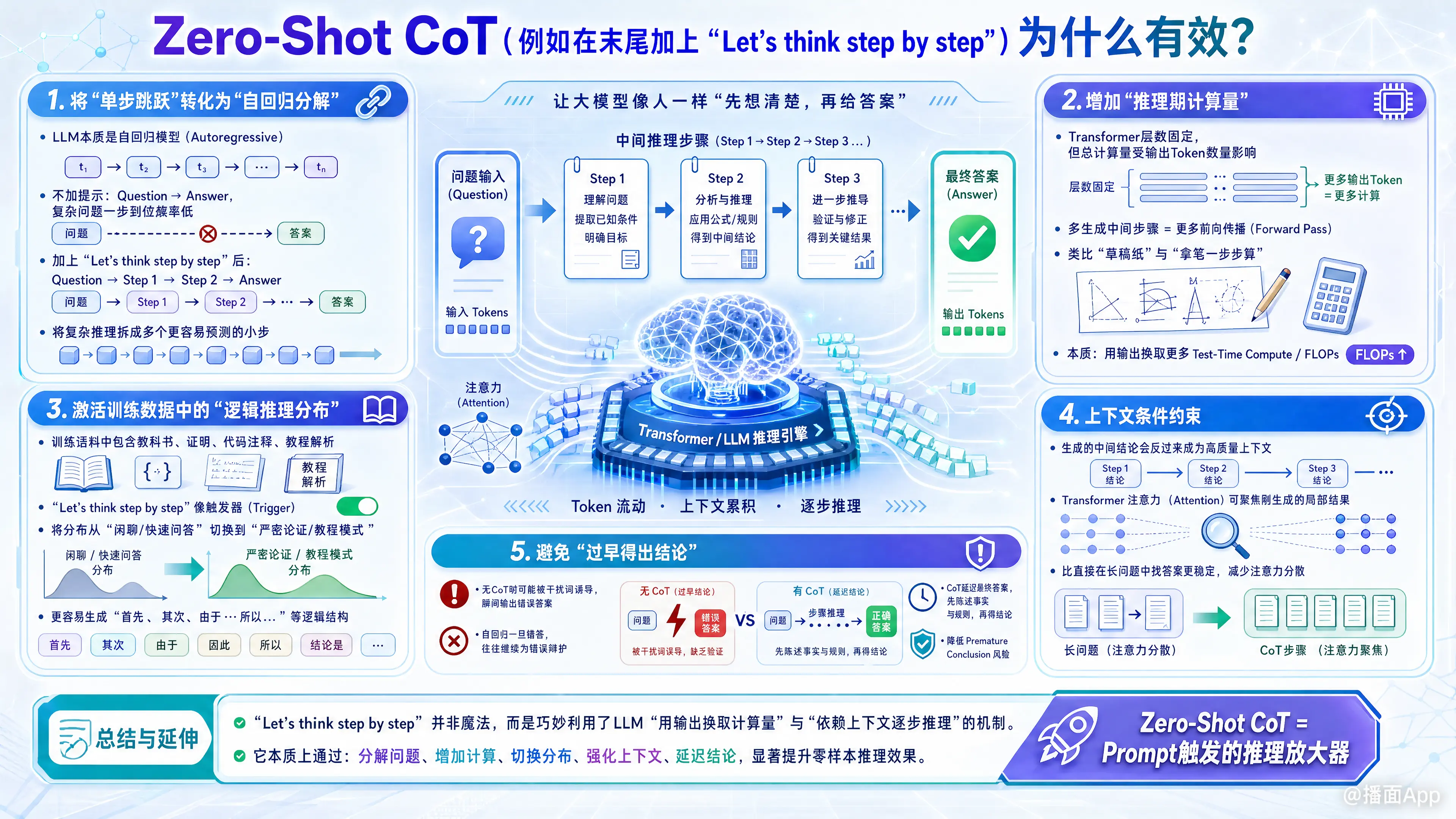
Zero-Shot CoT(零样本思维链,最著名的代表就是加上一句 "Let's think step by step")之所以能在不提供任何示例的情况下大幅提升大语言模型(LLM)的推理能力,其背后的原理可以从模型架构、计算机制、训练数据分布等多个维度来解释。
以下是它有效核心原因的深度解析:
1. 将“单步跳跃”转化为“自回归分解”(Autoregressive Decomposition)
大语言模型本质上是自回归模型(Autoregressive Models),即通过已经生成的词(Token)来预测下一个词。
- 如果不加这句话: 模型试图将复杂问题直接映射到最终答案(Question Answer)。对于需要多步计算或逻辑推导的问题,这种“一步到位”的概率极低,很容易产生幻觉或瞎猜。
- 加上这句话后: 模型被强制要求输出中间步骤(Question Step 1 Step 2 Answer)。由于每一步都是建立在前一步的基础上的,生成 Step 2 时,Step 1 已经成为了上下文的一部分。这种分解大大降低了每一步预测的难度。
2. 增加了“推理期计算量”(Test-Time Compute)
这可能是最本质的原因。在 Transformer 架构中,模型处理信息的深度是固定的(即它的层数),但它分配给某个问题的总计算量取决于输出 Token 的数量。
- 人类类比: 如果让你立刻回答“17 乘以 24 是多少”,你可能会猜错;但如果允许你拿笔在纸上一步步算(先算 17x20=340,再算 17x4=68,最后相加得出 408),你就能算对。
- 模型机制: 每多生成一个 Token,模型就进行了一次完整的前向传播(Forward Pass)。"Let's think step by step" 迫使模型生成大量的中间 Token。这些多出来的 Token 就像是模型的“草稿纸”,让模型有更多的计算资源(FLOPs)和时间去处理这个复杂问题,然后再得出最终结论。
3. 激活了训练数据中的“逻辑推理分布”
大语言模型的训练数据包含海量的互联网文本,其中既有毫无逻辑的闲聊,也有严谨的数学证明、代码注释和教科书解析。
- 触发器(Trigger): "Let's think step by step" 就像一个神奇的开关。它在模型的潜在空间(Latent Space)中,将预测的概率分布从“快速问答/闲聊模式”强行切换到了“教科书/教程/严密论证模式”。
- 在这种模式下,模型更倾向于使用诸如“首先”、“其次”、“由于...所以”等逻辑连接词,这些词本身就会引导模型走向正确的推理路径。
4. 上下文条件约束(Context Conditioning)
在生成思维链的过程中,模型实际上是在自己给自己创建更高质量的上下文(Context)。
- 一旦模型生成了“首先,A=5”,这个正确的前提就会作为强有力的上下文,约束模型接下来生成的词。
- Transformer 的注意力机制(Attention Mechanism)可以聚焦在刚刚生成的这些清晰、局部的中间结果上,而不是试图在长篇大论的原始问题中寻找答案。这避免了注意力分散导致的逻辑混乱。
5. 避免了“过早得出结论”(Premature Conclusion)
如果没有 CoT,模型有时会因为问题中的某些强干扰词,瞬间生成一个错误的最终答案。而一旦模型输出了错误答案,由于自回归的特性,它为了保持上下文的连贯性,就会继续为这个错误答案辩护(即便它内部的知识表明这是错的)。
- "Let's think step by step" 延迟了最终答案的生成,迫使模型先陈述事实和规则,这极大降低了被干扰信息误导、过早得出错误结论的风险。
总结与延伸:
"Let's think step by step" 并非魔法,而是巧妙地利用了 LLM “用输出换取计算量” 和 “依赖上下文生成” 的底层特性。
注:目前最前沿的 AI 发展(例如 OpenAI 的 o1 模型),其实就是把这种 Zero-Shot CoT 的思想内化了。o1 模型在给出最终答案前,会在后台自动生成一条漫长且不可见的“思维链”(Internal CoT),通过强化学习让模型学会如何分配更多的“推理期计算量”(Test-Time Compute)来解决极度复杂的问题。