 播面
播面 为什么“角色扮演(Persona Prompting / Act as...)”能提高大模型在特定任务上的表现?]
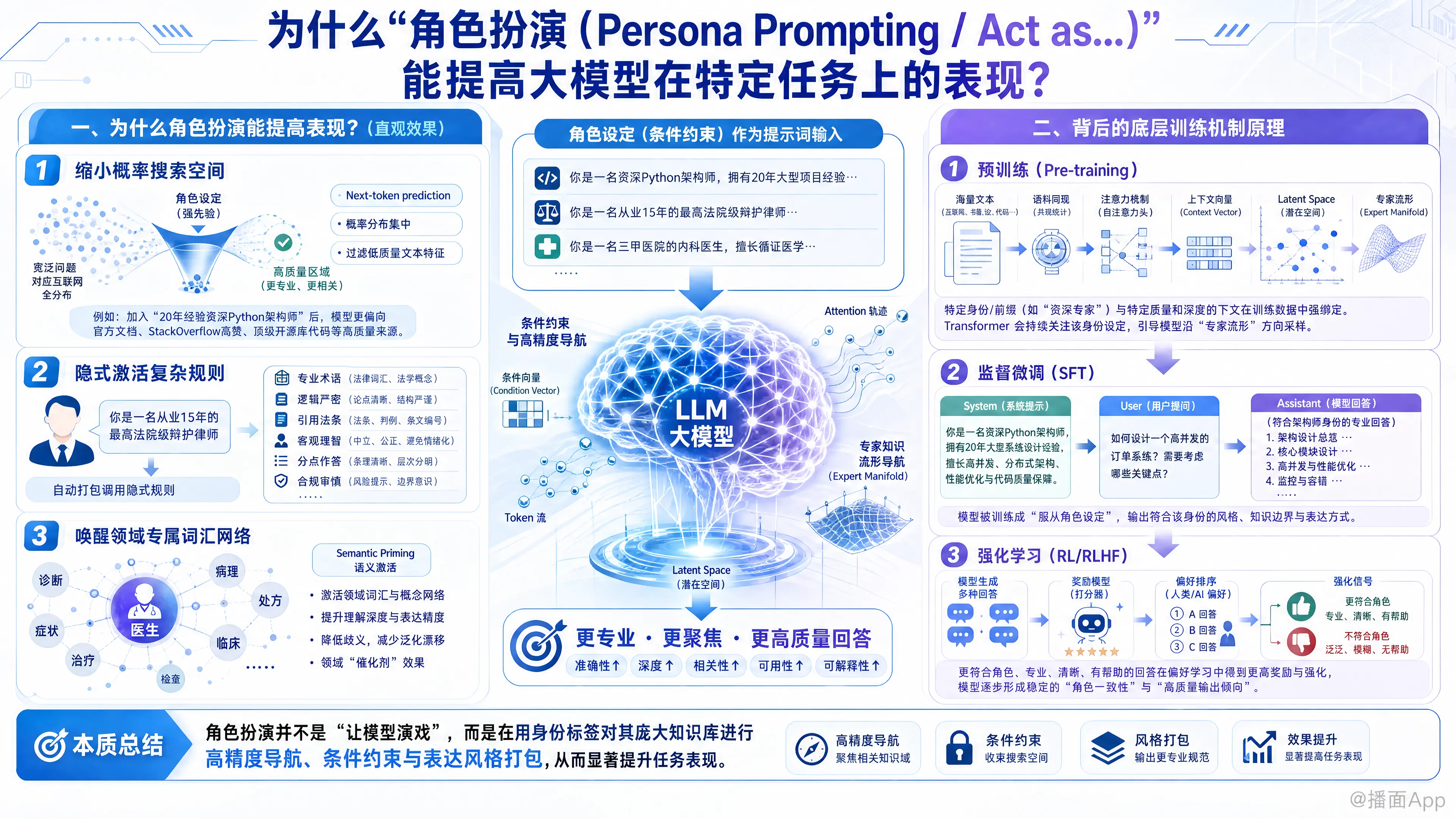
“角色扮演(Persona Prompting / Act as...)”是提示词工程(Prompt Engineering)中最经典且最有效的技巧之一。它之所以能显著提高大语言模型(LLM)在特定任务上的表现,是因为它在本质上是对模型庞大的“知识库”进行了一次高精度的导航和条件约束。
我们可以从直观效果(Why it works)和底层训练机制(How it was trained)两个维度来深度解析这个问题。
一、 为什么角色扮演能提高表现?(直观效果)
1. 缩小概率搜索空间(缩小范围,提高质量)
大模型的本质是“预测下一个词(Next-token prediction)”。当你问一个宽泛的问题时,模型面对的是整个互联网的文本分布(包括专家论文、知乎问答、贴吧灌水、甚至错误信息)。
当你加入“你是一个拥有20年经验的资深Python架构师”时,你实际上是在给模型添加一个强约束条件。模型在计算下一个词的概率时,会自动过滤掉“新手教程”或“业余论坛”的低质量文本特征,将其概率分布集中在“官方文档、StackOverflow高赞回答、顶级开源库代码”所在的概率空间中。
2. 隐式激活一组复杂的规则(打包指令)
一个“角色”其实是无数条指令的打包集合。
如果你想要一个高质量的法律咨询回答,你原本需要写:“请使用专业术语,逻辑要严密,引用相关法条,语气要客观理智,不要带有情绪,分点作答……”
但如果你只写一句:“你是一名从业15年的最高法院级辩护律师”,模型就能瞬间“秒懂”并自动应用上述所有的隐式规则,这大大降低了提示词的编写成本,同时激活了更连贯的表达模式。
3. 唤醒领域专属的“词汇网络”
人类的语言是有关联性的(Semantic Priming)。当“医生”这个词出现时,网络中与之相关的“诊断、病理、处方、临床”等词汇的激活权重就会升高。角色扮演相当于给模型的大脑打了一针“领域催化剂”,让它在提取知识时更加垂直和专业。
二、 背后的底层训练机制原理是什么?
大模型之所以吃这一套,是由其三个核心训练阶段(预训练 -> 监督微调 -> 强化学习)共同决定的:
1. 预训练阶段(Pre-training):注意力机制与潜在空间(Latent Space)
- 语料的上下文同现(Co-occurrence): 在模型吞下互联网上海量数据时,它发现人类的语言是高度依赖语境的。比如,在一篇医学论文的开头,通常会有“Dr. Smith, Chief of Oncology...”这样的背景介绍;在一个高质量代码库的README中,会有“As a senior developer...”的预设。模型在预训练时,学习到了“特定的身份/前缀”总是与“特定质量、特定深度的下文”强绑定。
- Transformer的自注意力机制(Self-Attention): 当你的提示词中包含“资深专家”时,Transformer的注意力头(Attention Heads)会在生成后续每一个词时,都不断回头去“关注(Attend to)”这个身份设定。这个身份特征会作为一个极强的上下文向量(Context Vector),持续引导模型在它的高维潜在空间(Latent Space)中,沿着特定的“专家流形(Manifold)”进行采样,而不是走到“外行流形”去。
2. 监督微调阶段(Supervised Fine-Tuning, SFT):系统指令的强化
- 在SFT阶段,研究人员会给模型喂入大量高质量的“指令-回答”对(Prompt-Response pairs)。
- 现在的开源/闭源大模型(如GPT-4, Llama 3等)都专门引入了“系统提示词(System Prompt)”的概念。在微调数据集中,有大量数据被刻意构造成:
[System: 你是一个XXX] -> [User: 提问] -> [Assistant: 符合XXX身份的专业回答]。 - 通过这种大量的微调,模型学会了“服从角色设定”这一行为本身。它被训练成:只要开头定义了角色,后续的输出就必须严格遵守该角色的行为规范。
3. 基于人类反馈的强化学习(RLHF / RLAIF):对齐人类偏好
- 在强化学习阶段,模型会生成多个不同的回答,由人类(或AI)来进行打分排序。
- 假设提示词是“以莎士比亚的口吻解释相对论”。如果模型给出了一个干巴巴的科普(虽然科学上正确),人类打分员会给低分;如果模型使用了古英语、诗歌格律和比喻,人类打分员会给高分。
- 奖励模型(Reward Model)由此学到了一个规律:响应与所设定的Persona的契合度,是决定回答质量(Reward)的重要指标。 因此,模型在最终生成时,会极力去迎合并模仿设定的角色,以获取更高的内在奖励分数。
总结与比喻
如果把大语言模型比作一个无所不知但没有自我意识的超级演员:
- 不加角色扮演: 相当于把演员推上台,只告诉他“演个哭戏”。他可能会演成琼瑶剧、也可能演成喜剧片里的假哭,效果随机。
- 加入角色扮演: 相当于给他一份详细的人物小传——“你是一个刚刚在战场上失去战友、患有PTSD的二战老兵”。演员(模型)的大脑里会立刻调动出他在电影学院(预训练)看过的所有相关素材,结合导演的要求(SFT和RLHF),给出极为精准、震撼的表演。
这就是Persona Prompting在算法和认知层面的底层逻辑。