 播面
播面 Temperature、Top-p、Frequency Penalty 和 Presence Penalty 超参数是如何与 Prompt 协同影响模型输出结果的?
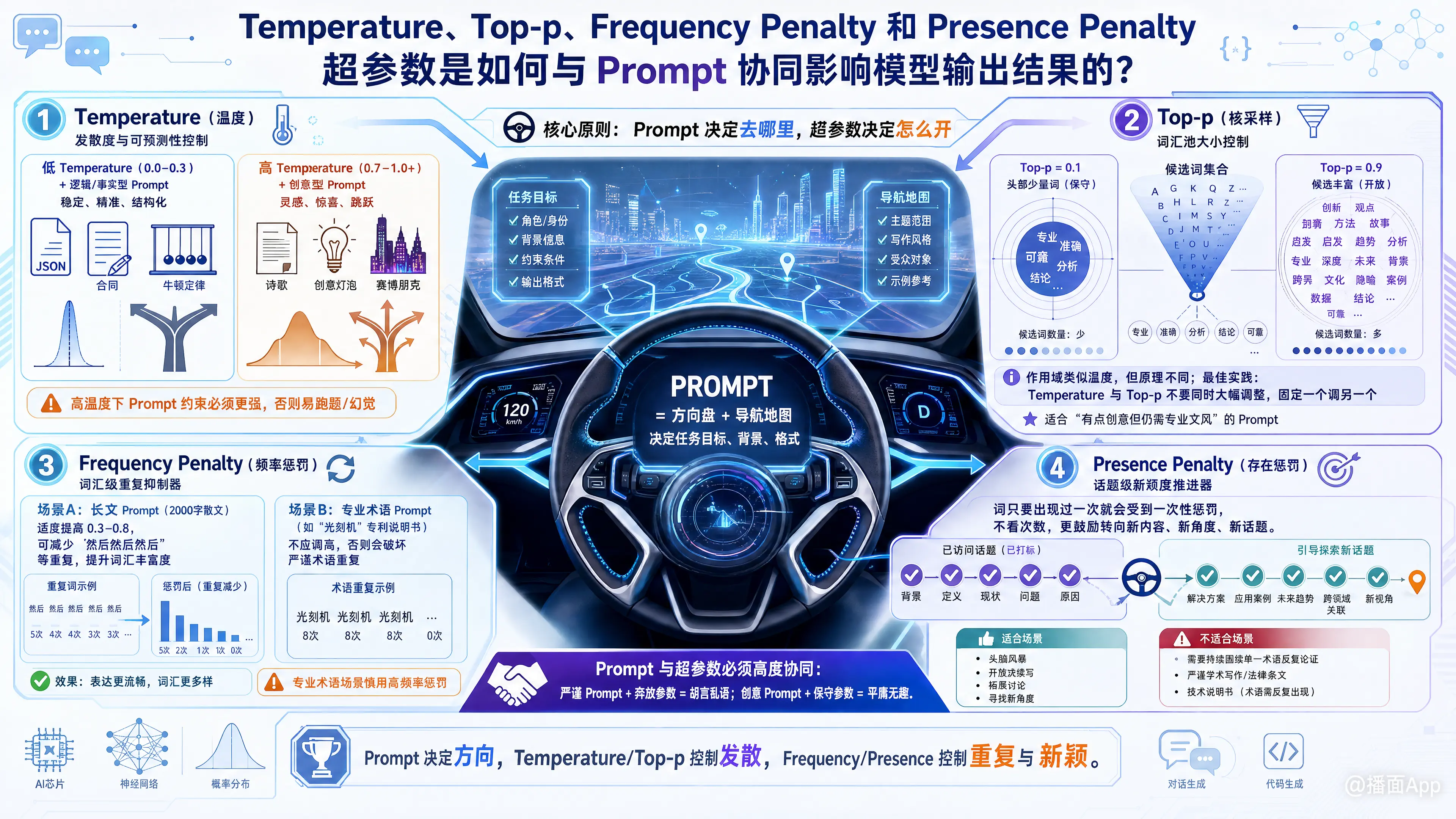
要理解这四个超参数(Hyperparameters)如何与 Prompt(提示词)协同工作,我们可以用一个驾驶的比喻:
- Prompt 是方向盘和导航地图:它决定了你要去哪里、走哪条路线(任务目标、背景、格式)。
- 超参数 是油门、悬挂系统和方向盘的灵敏度:它决定了你开车的风格(是稳重安全地按既定路线开,还是喜欢随性漂移、探索未知小路)。
这两者必须高度协同。一个严谨的 Prompt 配上极其奔放的超参数,会导致模型“胡言乱语”;而一个需要创意的 Prompt 配上极度保守的超参数,则会产出极其平庸的内容。
以下是这四个超参数的具体作用,以及它们如何与 Prompt 产生化学反应:
1. Temperature (温度) —— “发散度与可预测性控制”
机制: 它调整了模型预测下一个词(Token)的概率分布。温度越低(趋近于 0),模型越倾向于选择概率最高的那个词;温度越高(趋近于 1 或更高),概率分布越平缓,模型可能会选择概率较低、更冷门的词。
与 Prompt 的协同效应:
- 低 Temperature (0.0 - 0.3) + 逻辑/事实型 Prompt:
- 协同效果: 完美适配。当你使用诸如“提取以下文本中的JSON数据”、“翻译这段合同”、“解释牛顿第一定律”这类 Prompt 时,低温度能确保模型不抖机灵,严格按照 Prompt 的约束输出最准确、最常见的结果。
- 高 Temperature (0.7 - 1.0+) + 创意型 Prompt:
- 协同效果: 激发灵感。当你的 Prompt 是“写一首关于赛博朋克秋天的现代诗”或“帮我想 10 个脑洞大开的营销点子”时,高温度会打破常规词汇组合,让输出充满惊喜。
- 注意: 在高温度下,Prompt 的约束力必须更强。如果你开了高温度,但 Prompt 写得很模糊,模型非常容易跑题(幻觉)。
2. Top-p (核采样 Nucleus Sampling) —— “词汇池大小控制”
机制: 它按照概率从高到低累加词汇,直到累计概率达到设定值 P 为止,模型只能从这个“候选池”里选词。Top-p = 0.1 意味着只从累计概率占 10% 的极少数头部词汇中选;Top-p = 0.9 意味着备选词汇非常丰富。
与 Prompt 的协同效应:
- 作用域类似温度,但原理不同。 业界最佳实践是:Temperature 和 Top-p 不要同时大幅度调整,固定一个,调另一个。
- 限制绝对冷门词: 即使你的 Prompt 鼓励创新,如果把 Top-p 设为 0.5,模型也会在一个“相对安全”的词汇池里进行组合。这对于“需要一点创意,但要求文风专业(例如写新闻公关稿)”的 Prompt 非常有效。
3. Frequency Penalty (频率惩罚) —— “词汇级重复抑制器”
机制: 根据一个词在生成的文本中已经出现的次数来进行惩罚。出现的次数越多,再次生成这个词的概率就越低。
与 Prompt 的协同效应:
- 长文 Prompt 的润滑剂: 当你的 Prompt 要求“写一篇 2000 字的散文”时,适当调高频率惩罚(如 0.3 - 0.8),可以强制模型使用更丰富的同义词,避免像“然后...然后...然后...”或反复使用同一个形容词的情况。
- 专业术语 Prompt 的克星: 如果你的 Prompt 是“起草一份关于‘光刻机’的专利说明书”,你绝不应该调高频率惩罚。因为专利说明书中“光刻机”这个词必须反复出现,如果开启高频率惩罚,模型为了不重复,会发明出“逐光雕刻设备”、“硅片曝光机器”等奇怪的词,破坏了 Prompt 要求的严谨性。
4. Presence Penalty (存在惩罚) —— “话题级新颖度推进器”
机制: 只要一个词在生成的文本中出现过(哪怕只出现过 1 次),就会受到一次性惩罚。它不看次数,只看“有没有”。这实际上是在鼓励模型引入新概念、新话题。
与 Prompt 的协同效应:
- 头脑风暴/列举型 Prompt 的好帮手: 如果你的 Prompt 是“列出 20 个导致初创公司失败的原因”,调高存在惩罚(如 0.5 - 1.0),模型会在写完“资金链断裂”后,立刻寻找全新的维度(如团队内讧、市场定位错误),而不是在“钱不够”这个话题上啰嗦。
- 深度剖析型 Prompt 的干扰项: 如果你的 Prompt 是“深度解析《红楼梦》中林黛玉的性格”,调高存在惩罚会导致模型在分析了一小段林黛玉后,因为“林黛玉”相关的词汇被惩罚了,急于转移话题去聊薛宝钗或贾宝玉,导致论述不够深入。
总结:实战中的“Prompt + 超参数”黄金组合
在实际应用中,我们通常会根据任务类型,对它们进行组合配置:
| 任务类型 | Prompt 特点 | Temperature | Top-p | Freq Penalty | Pres Penalty | 协同表现描述 |
|---|---|---|---|---|---|---|
| 代码/数据提取 | 规则严格、格式限定、Few-shot | 0.0 - 0.2 | 1.0 | 0.0 | 0.0 | 模型变成精准的机器,完全服从 Prompt 的指令,不加任何自我发挥。 |
| 逻辑推理/问答 | 强调事实、需要一步步思考 | 0.3 - 0.5 | 1.0 | 0.0 | 0.0 | 保证事实准确性的同时,语言稍微自然流畅一点。 |
| 长文写作/博客 | 给定大纲、设定 Persona(角色) | 0.6 - 0.8 | 0.9 | 0.2 - 0.5 | 0.1 - 0.3 | 词汇丰富不枯燥(Freq起效),能顺着大纲不断推进新内容(Pres起效)。 |
| 头脑风暴/起名 | 开放式问题、要求天马行空 | 0.9 - 1.2 | 0.95 | 0.0 - 0.2 | 0.5 - 1.0 | 模型极度发散,Presence 惩罚逼迫它不断抛出之前没提过的新点子。 |
核心法则:
Prompt 决定了模型的上限和下限(写得差的 Prompt 调什么参数都没用),而这四个超参数负责在 Prompt 圈定的框架内,找到准确性与创造力之间的最佳平衡点。