 播面
播面 Few-Shot 提示中,提供给模型的示例(Examples)的选择标准是什么?示例的顺序会对模型的输出产生影响吗?
在 Few-Shot Prompting(少样本提示)中,示例的选择和排列对大语言模型(LLM)的最终表现起着决定性的作用。
以下是关于示例选择标准以及示例顺序影响的详细解答:
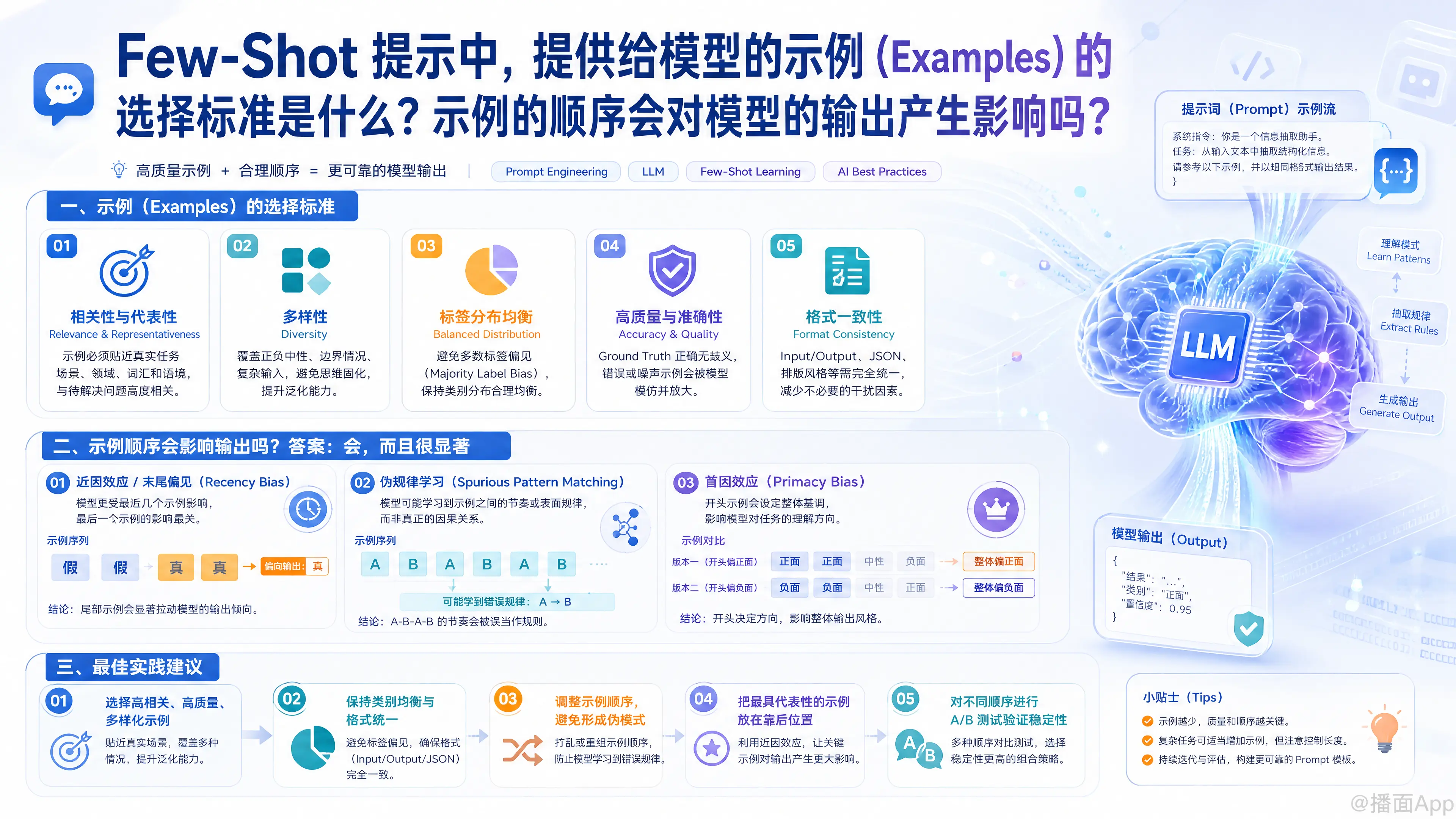
一、 示例(Examples)的选择标准
为了让模型最好地理解任务并输出高质量的结果,选择示例时应遵循以下几个核心标准:
1. 相关性与代表性 (Relevance & Representativeness)
- 标准: 示例必须与最终要解决的实际任务高度相关。
- 解释: 如果你要让模型做“医疗领域的客户情感分析”,就不要用“电影评论”的示例。示例越贴近实际输入场景(词汇、语境、领域),模型的泛化效果越好。
2. 多样性 (Diversity)
- 标准: 示例需要覆盖任务中可能出现的各种情况、边界条件和输入类型。
- 解释: 如果是情感分析,必须同时包含“正面”、“负面”和“中性”的示例;如果是实体提取,不仅要包含标准的句子,最好也包含带有错别字、或者缺乏标点符号的复杂句子。多样性不足会导致模型思维固化。
3. 标签分布的均衡性 (Balanced Distribution)
- 标准: 各个类别的示例数量应该尽可能均衡。
- 解释: 如果你给了 4 个示例,其中 3 个的结果是“同意”,1 个是“拒绝”,模型会产生多数标签偏见(Majority Label Bias),在遇到不确定的输入时,盲目猜测“同意”。
4. 高质量与准确性 (High Quality & Accuracy)
- 标准: 示例的输入和输出必须是绝对正确、无歧义的(Ground Truth)。
- 解释: “垃圾进,垃圾出”(Garbage in, garbage out)。大模型具有很强的模仿能力,如果示例中存在逻辑错误或拼写错误,模型会完美地“学会”这些错误。如果使用思维链(Chain-of-Thought),示例中的推理过程必须严密、清晰。
5. 格式的一致性 (Format Consistency)
- 标准: 示例的排版、符号、输入输出前缀(如
Input:,Output:)必须与最终测试的格式完全一致。 - 解释: 如果你希望模型最终输出 JSON 格式,那么所有示例的输出部分都必须是标准的 JSON。模型不仅学习任务逻辑,还在学习输出的“样式”。
二、 示例的顺序会对模型的输出产生影响吗?
答案是:会,而且影响可能非常显著。
在学术界和工程实践中,已经多次证实了 LLM 对提示词中的内容顺序非常敏感。示例顺序主要会通过以下几种机制产生影响:
1. 近因效应 / 末尾偏见 (Recency Bias)
- 现象: 模型通常对提示词中最靠近结尾(即紧挨着实际问题)的示例印象最深。
- 影响: 如果最后一个示例的输出是类别 A,当模型面对模棱两可的新问题时,它会有极大的倾向输出类别 A。
- 例子: 假设做二分类(真/假),示例顺序是
[假, 假, 真, 真],模型在实际预测时输出“真”的概率会异常增高。
2. 模式匹配与伪规律学习 (Spurious Pattern Matching)
- 现象: 大模型是非常强大的“模式寻找者”。如果你的示例顺序无意中包含某种规律,模型可能会放弃学习任务本身,转而学习这个伪规律。
- 影响:
- 如果示例答案是
[A, B, A, B],模型遇到第五个问题时,很可能会不看题目直接输出A。 - 如果示例按输入文本的长度从短到长排列,模型可能会认为输出结果与文本长度有关。
- 如果示例答案是
3. 首因效应 (Primacy Bias)
- 现象: 类似于人类,模型有时也会对最开头的信息分配较高的注意力(尽管通常不如近因效应强烈)。最前面的示例往往定下了整个对话的基调。
三、 最佳实践建议(如何应对上述问题)
为了最大化 Few-Shot 的效果并消除顺序带来的负面影响,建议采取以下策略:
- 随机化顺序 (Randomization): 如果可能,每次请求时将准备好的示例打乱顺序后再喂给模型,这在批量处理任务时能有效降低单一顺序带来的系统性偏差。
- 保证末尾示例的客观性: 在做分类任务时,尽量确保最后一个示例具有代表性,或者在末尾加上一句强调指令,如:
"请根据上述规则,客观地评估以下输入:",以阻断末尾偏见。 - 数量要适中: 通常提供 3 到 8 个示例效果最佳(即 3-shot 到 8-shot)。示例太少无法覆盖多样性;示例太多不仅浪费 Token 成本,还会导致模型的注意力被严重分散(“迷失在中间”效应,Lost in the Middle)。
- 动态示例检索 (Dynamic Few-Shot): 对于高级应用,不要使用固定的示例。可以使用向量数据库,根据用户的当前输入,动态检索出最相似的 3 个示例作为 Few-Shot。这是目前业界公认效果最好的方案。