 播面
播面 LangGraph State 里面存储了大量的大文件内容(如 PDF 提取的全量文本),状态的频繁复制传递会导致内存暴涨,如何优化这类场景下的数据流转?
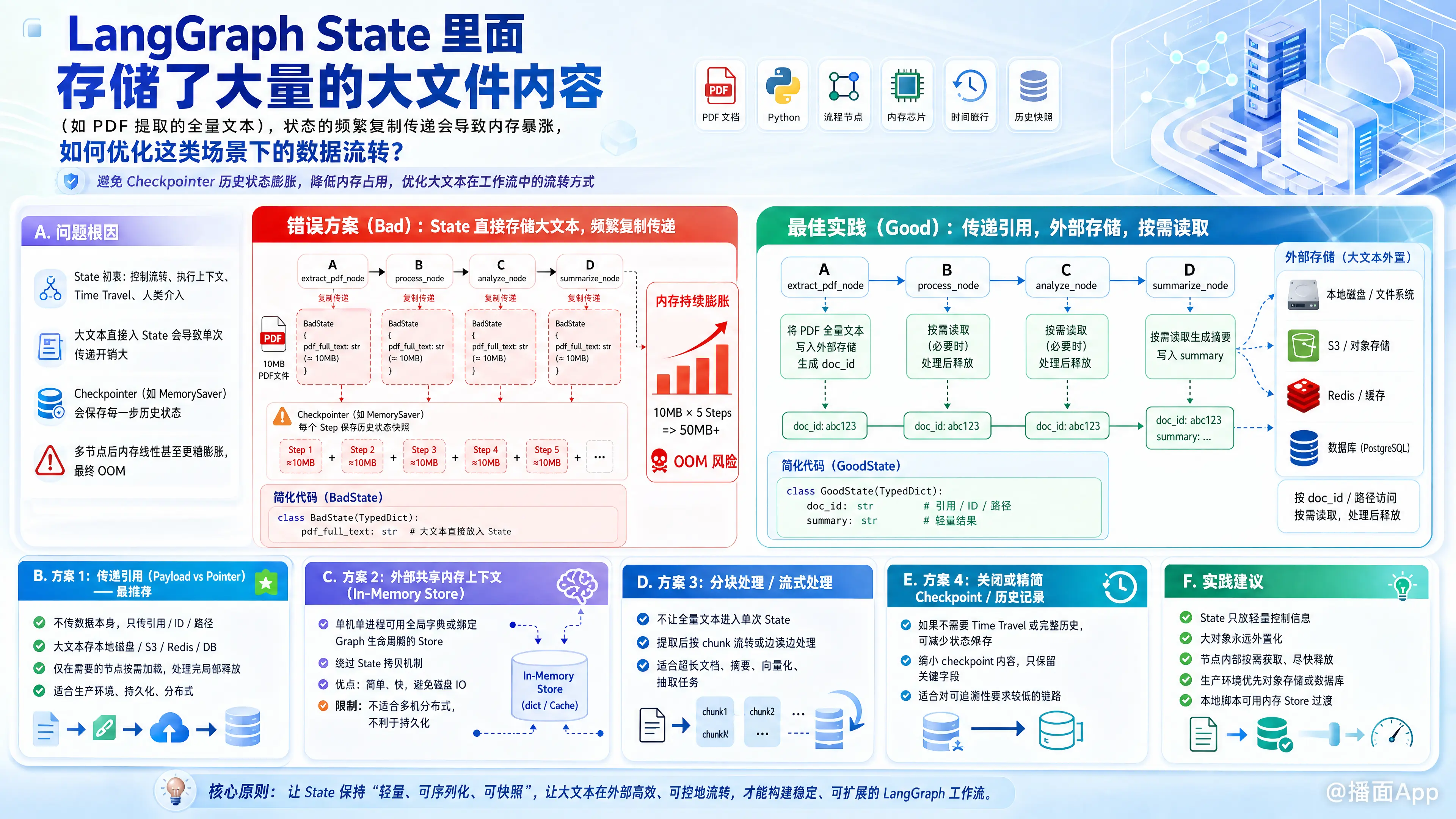
在 LangGraph 中,State 的设计初衷是用于控制流转、保存图的执行上下文以及支持“时间旅行”(Time Travel)和人类介入(Human-in-the-loop)等特性。
如果在 State 中直接存储极大的数据(如数 MB 甚至更大的 PDF 全文),不仅会导致单次传递时内存开销极大,更致命的是 LangGraph 的 Checkpointer(如 MemorySaver)会保存每一个 Step 的历史状态。这意味着一个 10MB 的文本经过 5 个节点,可能会在内存中膨胀到 50MB 以上,最终导致 OOM(内存溢出)。
针对这种场景,以下是几种业界最佳的优化方案(按推荐程度排序):
1. 核心模式:传递引用(Payload vs. Pointer)—— 最推荐
不要在 State 中传递数据本身,而是传递数据的“指针”(引用/ID/路径)。
- 实现原理:将大文件提取后的文本存储在外部存储(本地磁盘、S3、Redis、数据库)中,State 中只保留该文档的唯一标识符(如
doc_id或file_path)。 - 适用场景:所有包含大文件的流转场景,尤其是需要持久化和分布式的生产环境。
代码示例:
python
from typing import TypedDict
import uuid
import os
# ❌ 错误的状态定义(内存杀手)
class BadState(TypedDict):
pdf_full_text: str # 直接存大文本
# ✅ 优化的状态定义
class GoodState(TypedDict):
doc_id: str # 只存 ID 或路径
summary: str
# 节点 A:读取、落盘并传递引用
def extract_pdf_node(state: GoodState):
doc_id = str(uuid.uuid4())
text = extract_massive_text_from_pdf("...")
# 将大文本写入磁盘或临时存储(如 Redis/S3/临时目录)
with open(f"/tmp/{doc_id}.txt", "w") as f:
f.write(text)
return {"doc_id": doc_id} # State 中只流转 ID
# 节点 B:通过引用按需读取
def summarize_node(state: GoodState):
doc_id = state["doc_id"]
# 仅在需要处理的节点加载数据,处理完后局部变量自动释放
with open(f"/tmp/{doc_id}.txt", "r") as f:
text = f.read()
summary = llm.invoke(f"Summarize: {text[:2000]}...") # 假设按需截取或处理
return {"summary": summary}2. 外部共享内存上下文(In-Memory Store)
如果你只是在单机单进程下运行,不想引入复杂的磁盘 IO 或外部数据库,可以使用一个全局的或与 Graph 生命周期绑定的内存字典来暂存大对象。
- 实现原理:使用 Python 原生的字典或对象作为
Store,绕过 LangGraph 的 State 拷贝机制。 - 适用场景:本地单机脚本、无需跨机分布式的轻量级应用。
python
# 全局或绑定到具体请求的内存池
DOCUMENT_STORE = {}
def extract_pdf_node(state: GoodState):
doc_id = str(uuid.uuid4())
text = extract_massive_text()
DOCUMENT_STORE[doc_id] = text # 存入外部字典
return {"doc_id": doc_id}
def process_node(state: GoodState):
text = DOCUMENT_STORE[state["doc_id"]] # 获取引用
# ... 处理逻辑
return {}
# 清理节点(重要!防止内存泄漏)
def cleanup_node(state: GoodState):
doc_id = state["doc_id"]
if doc_id in DOCUMENT_STORE:
del DOCUMENT_STORE[doc_id]
return {}(注:LangChain 近期推出了 BaseStore 的概念,官方也开始推荐使用独立的 Store 来管理跨节点/跨 session 的大块数据,以保持 State 轻量)
3. 用尽即弃:及时清理 State 中的大字段
如果必须在 State 中传递数据,请确保在使用完毕后立刻将其从 State 中清除,防止被后续节点和 Checkpoint 无限期保留。
- 实现原理:利用 Reducer 机制,当节点返回
None或空字符串时,覆盖原有的大文本。
python
import operator
from typing import Annotated
class ProcessState(TypedDict):
# 使用覆盖(overwrite)逻辑,允许设置为空
full_text: str | None
result: str
def extract_node(state: ProcessState):
return {"full_text": "THIS IS A VERY LARGE STRING..."}
def analyze_node(state: ProcessState):
text = state["full_text"]
result = analyze(text)
# 处理完毕后,主动把 full_text 置为 None,释放内存
# 这样后续节点的 State 拷贝和 Checkpoint 就不会包含这个大字符串了
return {"full_text": None, "result": result}4. 架构优化:Map-Reduce 分块处理 (使用 Send API)
如果大文件需要全量丢给大模型处理,与其把一整本书存入 State,不如在第一步就将其切片(Chunking),然后利用 LangGraph 的并发 API 发送给多个 Worker 节点。
- 实现原理:使用 LangGraph 的
Send机制实现 Map-Reduce,State中只流转切片。
python
from langgraph.constants import Send
# 1. 拆分节点不把全文存入State,而是直接发射任务
def chunk_and_distribute(state: ProcessState):
chunks = split_pdf_into_100_chunks("large_file.pdf")
# 向 worker_node 派发 100 个并发任务,每个任务只携带很小的 chunk_text
return [Send("worker_node", {"chunk_text": chunk}) for chunk in chunks]
# 2. Worker 节点独立处理小文本
def worker_node(state: WorkerState):
summary = llm.invoke(state["chunk_text"])
return {"summaries": [summary]} # 汇总到主 State 5. Checkpointer 优化
如果你开启了 MemorySaver() 来做调试或线程管理:
- 生产环境慎用
MemorySaver:对于大吞吐量应用,请使用AsyncSqliteSaver或AsyncPostgresSaver。这样历史状态会落盘到数据库,不会撑爆应用程序的 RAM。 - 只保留最新状态:如果不依赖“时间旅行”或撤销功能,尽量少用 checkpointer,或者定期清理数据库中的旧 checkpoint 记录。
总结建议
- 最佳实践:采用 方案 1(传递外部引用/存储路径)。这是最符合微服务和复杂应用设计的做法,它彻底解耦了“控制流”(LangGraph State)和“数据流”(外部存储)。
- 快速修复:如果你想在现有代码上做最小改动,采用 方案 3(及时清理大字段)。
- 文档处理利器:如果是为了并发处理长文本,结合 方案 4(Map-Reduce) 会获得性能和内存的双重提升。