梯度爆炸/消失在大规模训练中会引发哪些系统级问题?
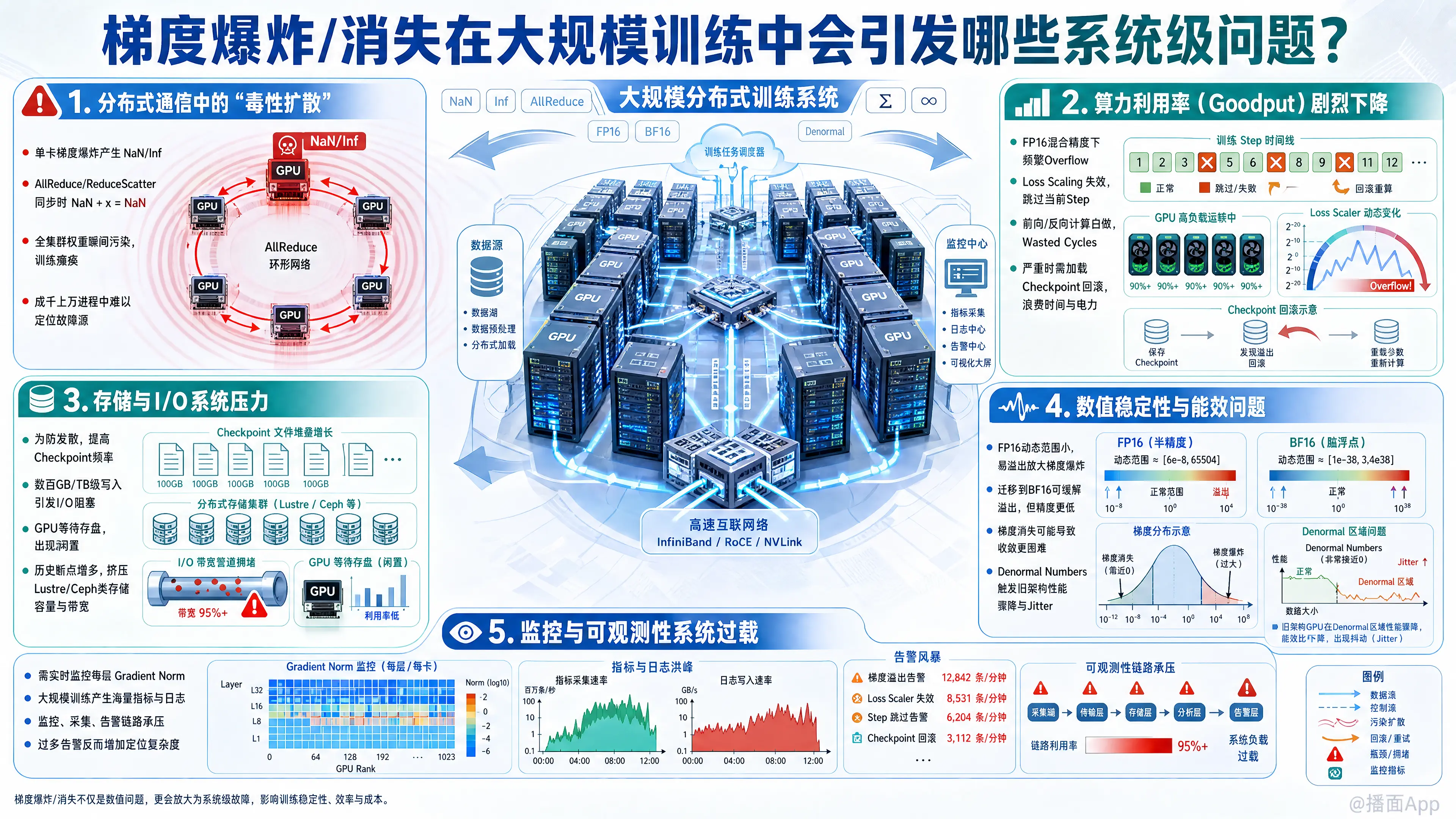
在大规模分布式训练(如LLM训练,涉及成百上千张GPU)中,梯度爆炸(Gradient Explosion)和梯度消失(Gradient Vanishing)不仅仅是算法层面的收敛问题,它们会引发一系列严重的系统级(System-level)挑战。
这些问题会直接冲击基础设施的稳定性、通信效率、存储I/O以及整体的算力利用率(Goodput)。以下是详细的系统级问题分析:
1. 分布式通信中的“毒性扩散” (Global Contamination via AllReduce)
这是大规模训练中最致命的系统问题。
- 现象:在数据并行(DDP/FSDP)模式下,如果某一张GPU(Rank N)上出现了梯度爆炸(导致 NaN 或 Inf),在进行梯度同步(
AllReduce或ReduceScatter)时,这个 NaN 会与所有其他 GPU 的正常梯度相加。 - 系统后果:
- 全集群瞬间瘫痪:根据 IEEE 754 标准,
NaN + x = NaN。因此,一次通信操作后,整个集群所有 GPU 的模型权重瞬间全部变成 NaN。 - 难以定位故障源:在成千上万个进程中,很难通过简单的日志快速定位是哪一张卡、哪一批数据首先触发了 NaN,增加了 Debug 的系统复杂度。
- 全集群瞬间瘫痪:根据 IEEE 754 标准,
2. 算力利用率(Goodput)剧烈下降
梯度异常会导致训练步数无效,必须触发容错机制,这直接降低了系统的有效产出。
- Loss Scaling 频繁失效:在混合精度训练(FP16)中,为了防止梯度消失,系统会使用 Loss Scaler。梯度爆炸会导致 Scaler 检测到溢出(Overflow),从而跳过当前 Step 的权重更新并缩小 Scale factor。
- 系统后果:
- 无效计算(Wasted Cycles):GPU 满负荷运转完成了前向和反向传播,但因梯度溢出被丢弃,电费和计算时间白白浪费。
- 频繁回滚(Rollback):严重的梯度爆炸可能导致模型发散,系统必须停止训练,加载上一个正常的 Checkpoint(断点)重新开始。这涉及巨大的 I/O 开销和时间回溯。
3. 存储与 I/O 系统的压力 (Checkpointing & I/O Storms)
为了应对梯度不稳定带来的潜在崩溃,工程团队通常会采取更激进的备份策略。
- 现象:为了防止梯度爆炸导致长时间训练成果作废,系统必须提高 Checkpoint 的保存频率。
- 系统后果:
- I/O 阻塞:保存千亿参数模型的 Checkpoint 需要写入数百 GB 甚至 TB 级的数据。频繁写入会阻塞计算(除非实现完美的异步保存),导致 GPU 闲置。
- 存储空间爆炸:需要保留更多的历史 Checkpoint 以备回滚,对分布式文件系统(如 Lustre, Ceph)的容量和带宽造成巨大压力。
4. 硬件层面的数值稳定性与能效问题
- FP16 vs BF16 的系统选择:
- 梯度爆炸在 FP16(半精度)下尤为严重,因为 FP16 的动态范围很小(最大值仅 65504)。这迫使系统架构迁移到 BF16(Bfloat16),虽然解决了溢出问题,但 BF16 的精度较低,可能加剧梯度消失导致的收敛困难。
- Denormal Numbers(非规格化数)导致的性能骤降:
- 梯度消失到极小值时,可能会落入浮点数的“非规格化区域”(Denormal range)。在某些旧架构或特定设置的 CPU/GPU 上,处理非规格化数极其缓慢,会导致计算核心的处理速度突然下降,造成系统级的性能抖动(Jitter)。
5. 监控与可观测性系统的过载 (Observability Overload)
- 现象:为了检测梯度问题,系统需要实时监控每一层的梯度范数(Gradient Norm)。
- 系统后果:
- 遥测数据洪流:在大模型中,收集所有层、所有 Rank 的梯度统计信息会产生海量的遥测数据,可能阻塞监控系统的带宽或导致 Prometheus/Grafana 等监控后端崩溃。
- 同步开销:计算全局 Gradient Norm 需要额外的
AllReduce操作,这在计算图中引入了额外的同步屏障,增加了通信延迟。
6. 流水线并行(Pipeline Parallelism)中的气泡与死锁风险
在 3D 并行(数据+模型+流水线)架构中:
- 现象:如果流水线前段发生梯度爆炸(NaN),这个 NaN 会沿着流水线向后传播。
- 系统后果:
- 状态不一致:如果系统设计了某些基于梯度幅度的动态调度策略(例如跳过某些层),异常梯度可能导致流水线各阶段状态不一致,甚至引发分布式死锁(Deadlock),导致训练任务挂起而不报错。
总结:工程应对策略
针对上述系统级问题,业界通常采取以下工程手段:
- 强制使用 BF16:牺牲少量精度换取更大的动态范围,物理上杜绝 FP16 的溢出问题。
- 梯度裁剪(Gradient Clipping):在 Optimizer 更新前,强制将梯度范数限制在阈值内,防止爆炸。
- 自动跳过机制(Auto-Skip):在系统层检测到 Inf/NaN 时,自动丢弃该 Batch,不进行参数更新,并报警。
- 3D 并行中的隔离:优化通信算子,尽量在本地检测 NaN,避免通过 AllReduce 污染全局。
- 异步 Checkpoint:将存储 I/O 移至 CPU 内存或 NVMe SSD 缓存,避免阻塞 GPU 计算。
右滑查看面试常问