Set、HashSet与TreeSet区别
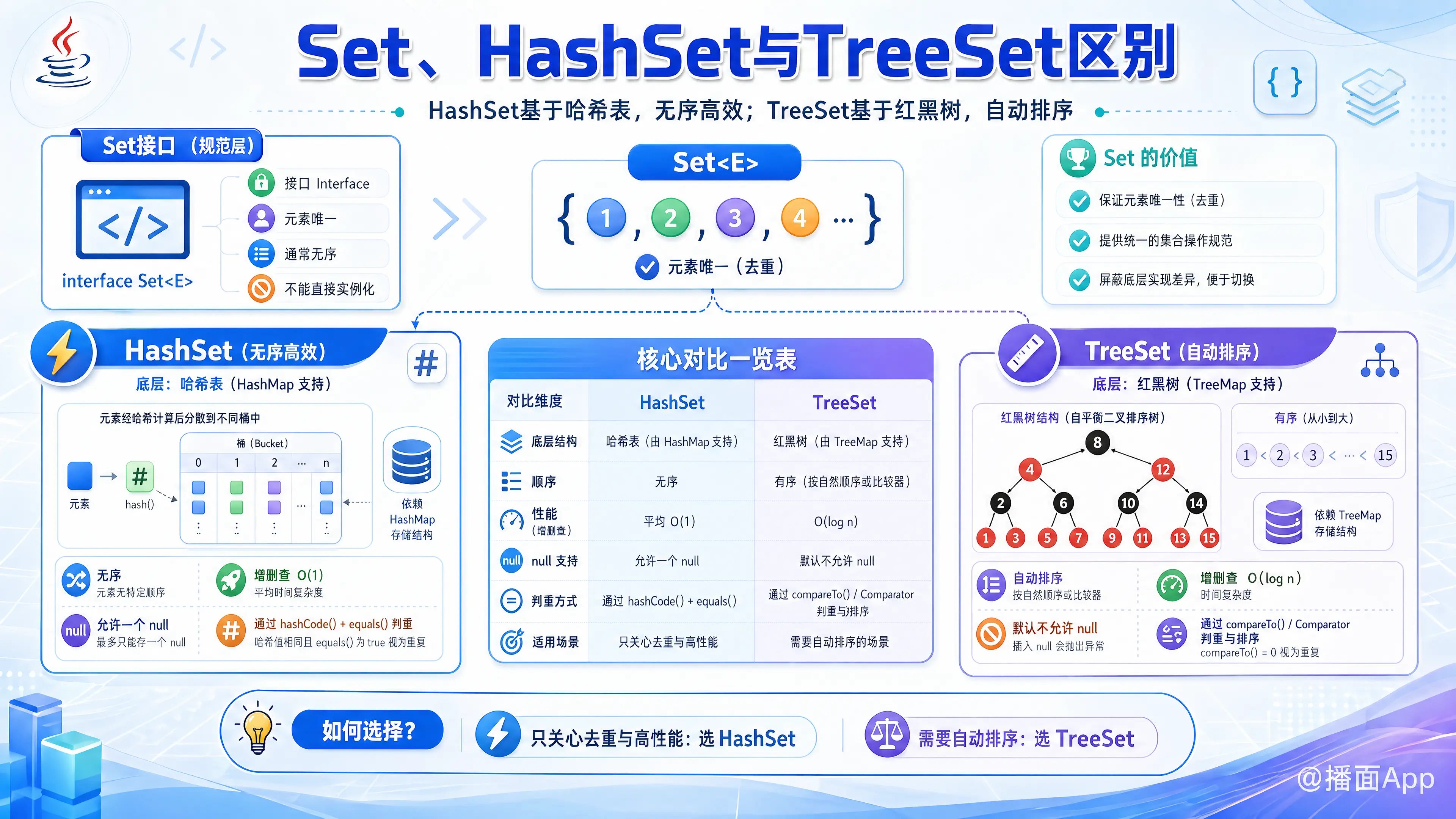
本文对比了HashSet与TreeSet的核心区别。前者基于哈希表,无序且高效;后者基于红黑树,能自动排序。文章阐明了两者在性能、顺序和底层结构上的差异,以助用户选择。
我们来详细地解释一下Java中 Set、HashSet 和 TreeSet 之间的区别。
首先,我们需要理解它们之间的层级关系:
Set是一个接口 (Interface)。它定义了一个不包含重复元素的集合的规范。它本身不能被实例化。HashSet和TreeSet是Set接口的两个主要实现类 (Implementation Class)。它们都遵循Set接口的规范(即元素唯一),但实现方式和特性完全不同。
1. Set 接口
Set 是 java.util.Collection 接口的一个子接口。它的核心特性是:
- 元素唯一性:
Set中不允许包含重复的元素。如果你尝试添加一个已经存在的元素,添加操作会失败,但不会抛出异常。 - 无序性(通常):
Set接口本身不保证元素的顺序。也就是说,你存入元素的顺序和取出元素的顺序可能不一致。当然,它的实现类TreeSet是个例外。
2. HashSet
HashSet 是 Set 接口最常用、最典型的实现类。
- 底层数据结构:
HashSet是基于 哈希表 (Hash Table) 实现的。实际上,它的内部由一个HashMap实例来支持。它将元素作为HashMap的键(key),而值(value)则是一个固定的虚拟对象。 - 顺序:不保证元素的顺序。元素的存储和取出顺序是不可预测的,并且可能会随着元素的增删而改变。
- 性能:由于基于哈希表,
HashSet的添加、删除、查找(add,remove,contains)操作的时间复杂度通常是 O(1)。这是它最大的优势,性能非常高。 - Null 值:允许存储一个
null元素。 - 判断元素唯一性的方式:
HashSet通过两个方法来判断元素是否重复:hashCode(): 首先计算元素的哈希码,以确定其在哈希表中的存储位置(桶)。equals(): 如果哈希码相同,再调用equals()方法来确认两个元素是否真的相等。注意:如果你将自定义类的对象存入
HashSet,必须正确地重写该类的hashCode()和equals()方法,否则无法保证元素的唯一性。
3. TreeSet
TreeSet 是 Set 接口的另一个重要实现类,它提供了排序功能。
- 底层数据结构:
TreeSet是基于 红黑树 (Red-Black Tree) 实现的。实际上,它的内部由一个TreeMap实例来支持。 - 顺序:元素是有序的。
TreeSet会根据元素的自然顺序或者在构造时提供的Comparator进行排序。 - 性能:由于基于红黑树,
TreeSet的添加、删除、查找操作的时间复杂度是 O(log n),其中 n 是集合中元素的数量。性能上不如HashSet,但提供了排序功能。 - Null 值:默认情况下不允许存储
null元素。因为TreeSet需要对元素进行比较排序,而null无法与任何值进行比较,会抛出NullPointerException。 - 判断元素唯一性的方式:
TreeSet通过比较元素的大小来判断唯一性,而不是hashCode()和equals()。它依赖于以下两者之一:- 自然排序:存入
TreeSet的元素必须实现Comparable接口,并重写compareTo()方法。TreeSet使用compareTo()的返回值来判断元素的大小和是否重复(返回值为0表示重复)。 - 定制排序:在创建
TreeSet时,可以传入一个Comparator对象。TreeSet会使用这个比较器的compare()方法来对元素进行排序和判断唯一性。
- 自然排序:存入
总结与对比表格
| 特性 | HashSet |
TreeSet |
|---|---|---|
| 底层数据结构 | 哈希表 (Hash Table) | 红黑树 (Red-Black Tree) |
| 顺序 | 无序,不保证顺序 | 有序,按元素值排序 |
| 性能 | 高 (增删查改: O(1)) | 较低 (增删查改: O(log n)) |
| Null 值 | 允许存储一个 null |
不允许 (默认情况) |
| 比较方式 | hashCode() 和 equals() |
compareTo() (Comparable) 或 compare() (Comparator) |
| 主要用途 | 快速存取,去重,不关心顺序 | 需要对元素进行排序的去重场景 |
如何选择?
- 当你想快速地存储不重复的元素,并且不关心它们的顺序时,
HashSet是最佳选择。这是最常用的Set实现。- 例如:统计一篇文章中出现了多少个不同的单词。
- 当你需要一个存储不重复元素,并且希望这些元素始终保持排序状态时,
TreeSet是唯一的选择。- 例如:存储学生成绩,并希望成绩总是从高到低(或从低到高)排列。
代码示例
java
import java.util.HashSet;
import java.util.Set;
import java.util.TreeSet;
public class SetComparison {
public static void main(String[] args) {
// 1. HashSet 示例 (无序)
Set<String> hashSet = new HashSet<>();
hashSet.add("Banana");
hashSet.add("Apple");
hashSet.add("Cherry");
hashSet.add("Apple"); // 尝试添加重复元素,会被忽略
hashSet.add(null); // 允许添加一个 null
System.out.println("HashSet (无序): " + hashSet);
// 输出可能是: [null, Apple, Cherry, Banana] (顺序不固定)
System.out.println("------------------------------------");
// 2. TreeSet 示例 (有序)
Set<String> treeSet = new TreeSet<>();
treeSet.add("Banana");
treeSet.add("Apple");
treeSet.add("Cherry");
treeSet.add("Apple"); // 尝试添加重复元素,会被忽略
// 尝试添加 null 会抛出 NullPointerException
// try {
// treeSet.add(null);
// } catch (NullPointerException e) {
// System.out.println("TreeSet 不允许添加 null 元素!");
// }
System.out.println("TreeSet (有序): " + treeSet);
// 输出总是: [Apple, Banana, Cherry] (按字母顺序排序)
}
}代码解释:
hashSet的输出顺序与添加顺序无关,并且是不可预测的。它成功地去除了重复的 "Apple" 并接受了一个null。treeSet的输出是按照字符串的自然顺序(字母顺序)排列的。它也去除了重复的 "Apple"。如果取消注释并尝试添加null,程序会抛出NullPointerException。
右滑查看面试常问